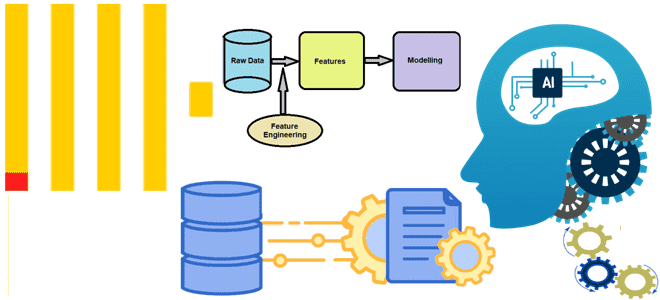
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...
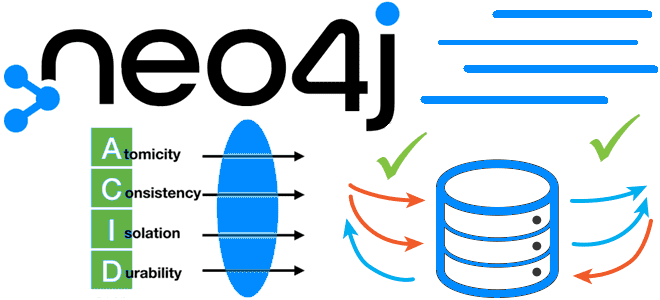
Как сделать крупное обновление, вставку или удаление данных в Neo4j без OOM-ошибки и APOC-процедур при выполнении транзакции с параллельным выполнением подзапросов: функция CICT, ее возможности, ограничения и отличия от конструкции CALL IN TRANSACTIONS. Подзапросы в транзакциях Neo4j: CIT-запросы Cypher vs процедуры APOC Параллельная обработка данных быстрее последовательной. Поэтому многие фреймворки...

Разработчики ClickHouse с завидной регулярностью радуют новыми релизами. Не прошло и месяца, как опубликован очередной выпуск этой колоночной СУБД, версия 24.8 LTS от 20 августа 2024. О ее главных новинках читайте далее. Несовместимые изменения Начнем с самых важных и несовместимых изменений. В релизе ClickHouse 24.8 LTS для clickhouse-client и clickhouse-local...

Новая логика дедупликации данных, ограничения работы с матпредставлениями, дополнительные SQL-функции и улучшения производительности ClickHouse 24.7: краткий обзор ключевых особенностей июльского выпуска. Несовместимые изменения и новые фичи 30 июля 2024 года вышел очередной релиз ClickHouse, в котором довольно много изменений, несовместимых с прошлыми версиями. В частности, в реплицированных базах данных теперь...
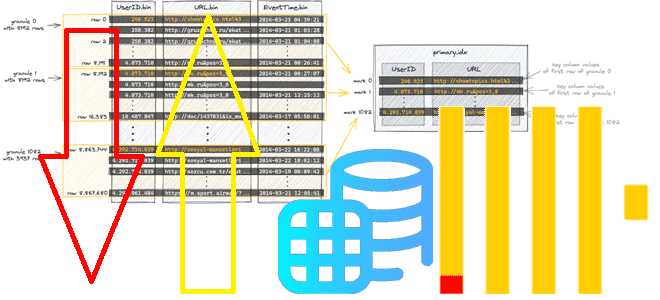
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
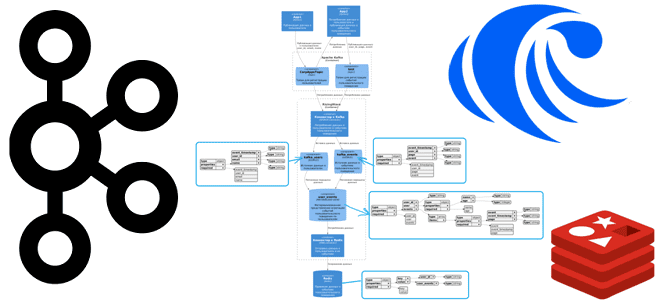
Как SQL-запросами соединить потоки из разных топиков Apache Kafka и отправить результаты в Redis: демонстрация ETL-конвейера на материализованных представлениях в RisingWave. Постановка задачи и проектирование потоковой системы Продолжая недавний пример потоковой агрегации данных из разных топиков Kafka с помощью SQL-запросов, сегодня расширим потоковый конвейер в RisingWave, добавив приемник данных –...
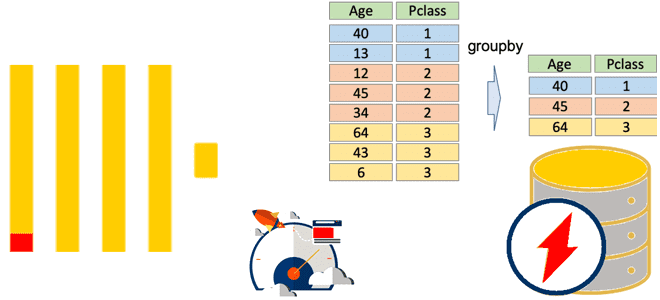
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных. Особенности выполнения оператора GROUP BY в ClickHouse Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение...
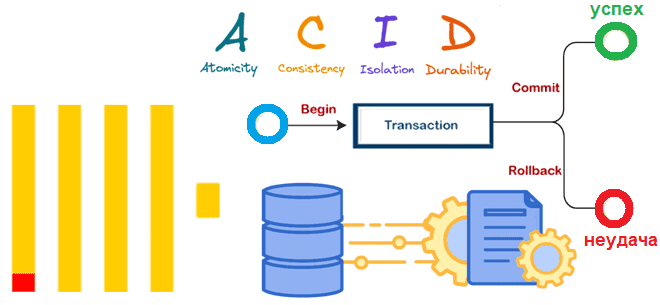
Почему в ClickHouse нет полноценных транзакций, но введена экспериментальная поддержка ACID для операций вставки в таблицы движка MergeTree, как это реализуется и чем синхронная вставка отличается от асинхронной. Особенности операций вставки в ClickHouse В ClickHouse нет полноценных транзакций, поскольку это колоночное хранилище в первую очередь ориентировано на чтение большого объема...
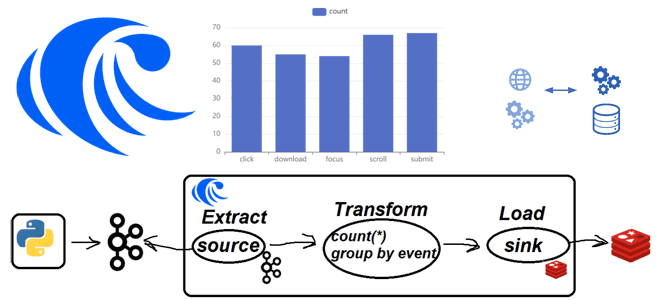
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций. Постановка задачи Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так...
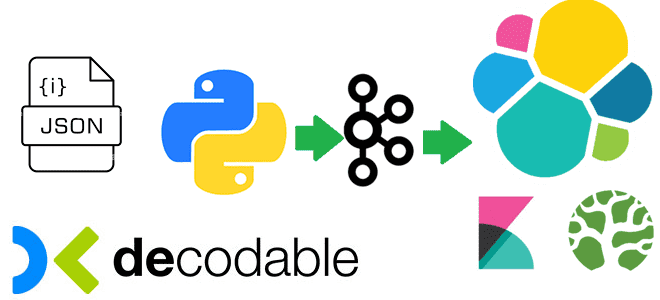
Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable. Потребление сообщений из Apache Kafka Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня...
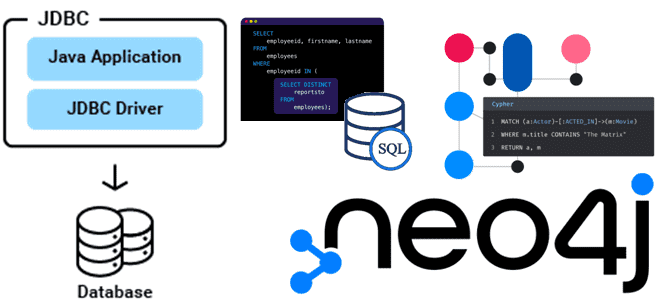
Что не так с общим Java-драйвером Neo4j, зачем нужен JDBC-драйвер, какие функции он поддерживает, а что не позволяет разработчику делать с этой графовой базой данных. Что не так с общим Java-драйвером Neo4j и зачем нужен JDBC-драйвер 25 марта 2024 года вышла 6-я версия драйвера JDBC для графовой СУБД Neo4j, поддерживаемого...
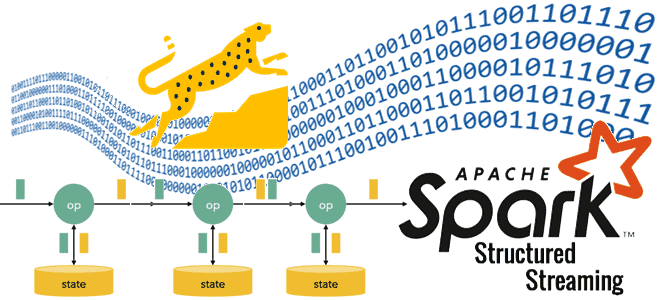
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее. Где stateful-операторы Spark Structured Streaming хранят состояния? Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные...

Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...

Тонкости параллельной среды выполнения Cypher-запросов в NoSQL-СУБД Neo4j и критерии выбора runtime для аналитических и транзакционных сценариев работы с графами. Слотовая и конвейерная среды выполнения Вообще в графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. По умолчанию в версии в Community Edition используется слотовая, а...
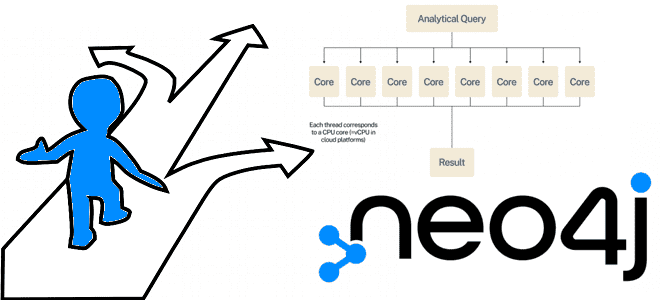
Чем слотовая среда выполнения Cypher-запросов в Neo4j отличается от конвейерной, как ее задать и что выбрать для транзакционных и аналитических сценариев работы с графами: наглядные примеры. Слотовая среда выполнения В графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. В большинстве случаев среды выполнения по умолчанию...
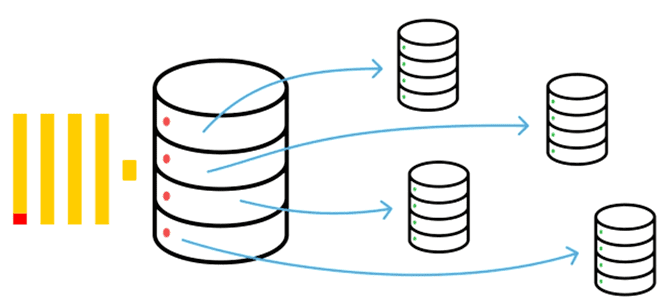
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...

Почему тормозит Cypher-запрос к Neo4j, как его отладить и чем оператор PROFILE отличается от EXPLAIN. Краткий ликбез с примерами выполнения запросов к графовой базе данных для аналитиков и разработчиков. Как выполняются Cypher-запросы в Neo4j Любой дата-аналитик и разработчик, работающий с базами данных, знает, что одной из самых частых причин медленного...
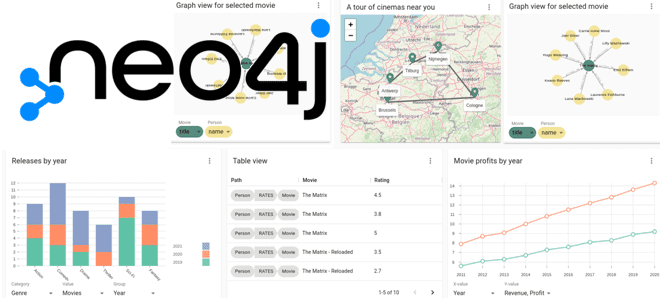
Создаем визуализации Cypher-запросов к своему графу в графовой базе данных Neo4j с помощью дэшборда NeoDash на примере анализа финансовых транзакций в банке. Python-генерация графа в Neo4j с фейковыми данными Поскольку NoSQL-СУБД Neo4j отлично подходит для задач графовой аналитики больших данных благодаря своей нативно графовой модели хранения данных, ее можно использовать...

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...
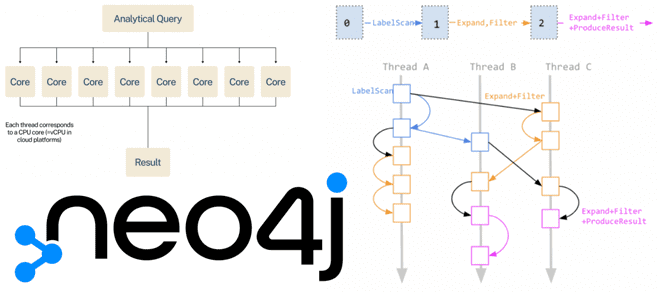
Как разработчики Neo4j улучшают производительность этой графовой СУБД с помощью нового блочного формата хранения данных и параллельной среды выполнения Cypher-запросов. Блочный формат хранения данных Наиболее важной новинкой Neo4j в релизе 5.14, вышедшего в конце ноября 2023 года, стал новый формат хранения данных – блочный, который размещает данные на диске в...