
В прошлый раз мы говорили про индексы в Hive. Сегодня поговорим про DML-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про DML-операции в Hive и их особенности. DML-операции в СУБД Apache Hive DML-операции (Data Manipulation Language) -...
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
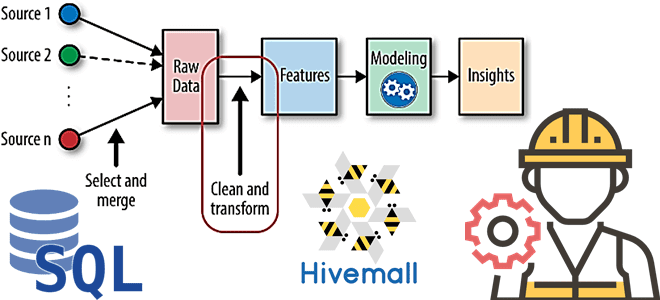
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...
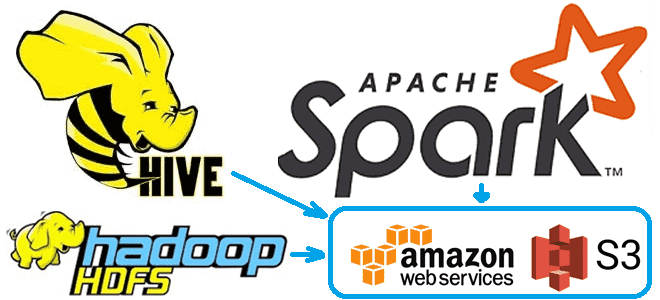
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...

В прошлый раз мы говорили про особенности работы механизмов группировки и сортировки в распределенной среде Impala. Сегодня поговорим про метаданные таблиц в Impala и про то, как их извлекать и выводить на экран. Читайте далее про табличные метаданные в Impala, благодаря которым становится доступным и весьма удобным legacy-проектирование. Что из...
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...
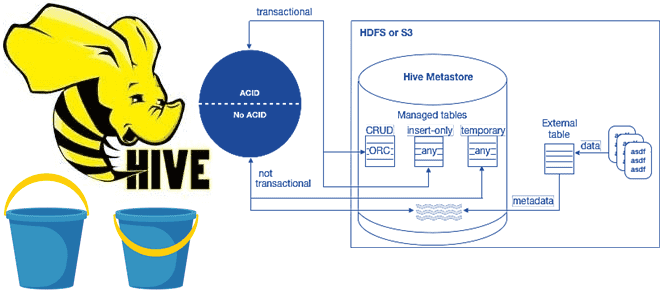
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....

Чтобы самостоятельное обучение по Hbase стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с этой СУБД в этой распределенной СУБД, включая ее особенности работы и архитектуру. Тест по основам работы с СУБД Hbase для новичков Для тех, кто начинает самостоятельное обучение по Apache Hbase, мы предлагаем...

В этой статье мы поговорим про основные базовые операции распределенной СУБД Hbase. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД на практических примерах. Читайте далее про базовые CRUD-операции в Hbase и их особенности. Основные CRUD-операции в распределенной СУБД Hbase HBase - это распределенная NoSQL столбцово-ориентированная (данные представлены...