 647
647 
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и как это работает с Hive и Spark.
SQL для Feature Engineering
Разработка фич — один из наиболее важных аспектов машинного обучения. Фича (Feature) — это атрибуты или характеристики, переменные из данных – признаки, которые полезны для обучения и получения результатов ML-модели, полученные на основе опыта из бизнеса или предметной области, например, средний рейтинг продукта.
Генерация признаков или разработка фич (Feature Engineering) — это очень интересный процесс определения переменных из набора данных, чтобы использовать их в обучении ML-модели для решения конкретной бизнес-задачи. Выявление и вычисление фич – сложная задача, которая требует доступа к данным и их извлечения из различных систем, этапов обработки и хранилищ. Подробнее о том, как выполняется работа с признаками на этапе Feature Engineering, мы писали здесь. Облегчить этот процесс помогают специализированные инструменты типа Featuretools, Trane, Feature Hub и комплексные ML-фреймворки, автоматизирующие создание конвейеров машинного обучения: MLBox, H2O, Auto Sklearn, TPOT и пр.
Также Data Scientist может вручную выполнять Feature Engineering, самостоятельно написав Python-скрипты с учетом особенностей данных и предметной области, а также бизнес-потребностей. Однако, независимо от конкретного инструмента Feature Engineering, ключевыми критериями для выбора средства и способа генерации фичей являются его гибкость и скорость поставки результатов.
Реализовать это требование поможет SQL – язык структурированных запросов, с которым знаком каждый аналитик и Data Scientist. Этот подход дает следующие преимущества:
- низкий порог входа в проект;
- экономит время;
- возможность повторного использования существующих фич для создания новых;
- переиспользование существующей инфраструктуры для преобразования и хранения данных.
Далее рассмотрим, как реализовать Feature Engineering с помощью SQL.
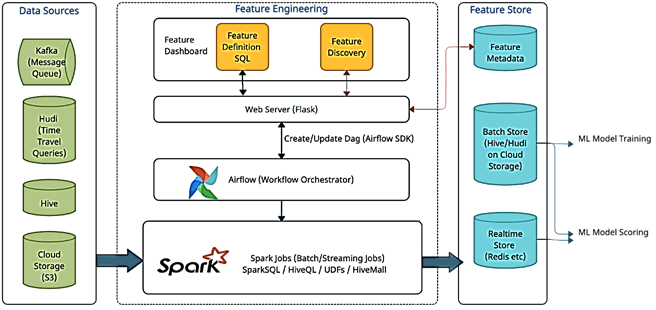
Архитектура ML-системы с точки зрения дата-инженера
Изначально данные могут храниться в разных системах:
- очередь сообщений типа Kafka, которая содержит потоковые данные для вычисления фичей в реальном времени;
- хранилище пакетных данных типа Hive, HDFS или AWS S3, которые содержат предварительно агрегированные данные, вывод ETL-заданий и пр.
- данные в формате открытых таблиц — специальные системы поверх озера данных (Data Lake), такие как Apache CarbonData, Hudi, Iceberg и Open Delta. Они обеспечивают поддержку ACID-транзакций для озер данных, вставляя эту транзакционную семантику и правила в сами форматы файлов или с использованием метаданных. Они удобны в качестве использования хранилища изменения данных, которые обслуживают запросы об изменении данных во времени, например, изменение цены продукта за неделю до распродажи и в период объявления скидок. Подробнее об этом мы писали здесь.
- Хранилище фичей (Feature Store), где хранятся определенные/вычисленные фичи в зависимости от их типа. Для потоковой обработки данных в качестве хранилища фич используются быстрые СУБД типа Redis и пр. А пакетные фичи хранятся в пакетных хранилищах, таких как Hive, HDFS или S3. Задание ML-моделирования считывает фичи из этого хранилища для обучения и эксплуатации моделей.
- хранилище метаданных (Feature Metadata) содержит метаданные о группе фич, которые можно объединить логически и вычислить с помощью одного и того же SQL-запроса.
Через дэшборды пользователь может создавать фичи через SQL-запросы, обращаясь через RESTful API к веб-серверу, который соединяет GUI со следующими компонентами обработки и хранилищем метаданных функций через конечные точки http. Он взаимодействует с хранилищем метаданных фич для расширения возможностей обнаружения функций. Для запросов определения группы фич он обновляет их метаданные, создает задачу AirFlow и добавляет ее в DAG, созданные на основе частоты планирования с использованием Python API.
В случае групп фич реального времени они напрямую передаются в вычислительный кластер с помощью команд bash или службы супервизора unix. В случае изменения группы фич эти Spark-задания потоковой передачи автоматически перезапускаются с измененной конфигурацией. Идентификатор группы фич (ссылка на запись группы в метаданных) передается в качестве аргумента приложения Spark-заданию.
Airflow как планировщик рабочего процесса, состоит из DAG (направленный ациклический график), который представляет собой набор задач, отражающих их отношения и зависимости. Каждая группа фич будет соответствовать одной задаче в DAG. Группы DAG создаются в зависимости от частоты выполнения заданий. Типичная конфигурация воздушного потока для групп фич пакетные Spark-задания. Идентификатор группы фич (ссылка на запись группы в метаданных) передается в качестве аргумента приложения Spark-заданию.
Задания Spark являются основным компонентом всей инфраструктуры Feature Engineering/ отвечая за фактическое выполнение SQL-запросов в вычислительном кластере. Эти задания могут выполняться через кластер Hadoop YARN, Aws EMR, Kubernetes и пр. Можно использовать различные SQL-функции из Hive, Spark и пользовательских библиотек из UDF-функций для разных вариантов использования. Далее их можно многократно использовать в группах фич.
Если необязательная конфигурация группы фич не предоставляется пользователем, то же самое предполагается после выполнения SQL-запросы для группы фич в Spark-задании, но только во время самого первого запуска данной группы фич и впоследствии обновляется в метаданных фичи.
Вычисление признаков в реальном времени немного сложнее пакетного режима. Временные представления создаются в наборах данных потоковой передачи, а SQL-запросы выполняются поверх них.
Говоря про пакетное вычисление фич, отметим возможность использования библиотеки Apache Hivemall – проекта с открытым исходным кодом в стадии инкубации в Apache Software Foundation. Он включает следующие функциональные возможности для ML: алгоритмы регрессии, классификации, рекомендации, обнаружения аномалий, k-средних и метод ближайших соседей, а также разработка фич. Hivemall также поддерживает сложные алгоритмы машинного обучения: Soft Confidence Weighted, Adaptive Regularization of Weight Vectors, Factorization Machines и AdaDelta.
Apache Hivemall в основном предназначен для работы в Hive, но он также поддерживает Pig и Spark во время выполнения. Таким образом, Hivemall можно рассматривать как кроссплатформенную библиотеку для машинного обучения: ML-модели, построенные с помощью пакетного запроса Apache Hive, можно использовать в Spark или Pig. И, наоборот, ML-модели, созданные в Apache Spark, можно использовать из Hive или Pig.
Таким образом, вычисление фич с помощью SQL повышает доступность Feature Engineering для более широкой аудитории DS-специалистов, может увеличить скорость ML-моделирования и повысить эффективность решений. Хотя этот подход не позволяет полностью исключить инженеров данных из ML-проектов, он экономит время и силы команды, а потому может отлично применяться на практике.
Узнайте больше про практическое применение Apache Hive и других компонентов экосистемы Hadoop для реализации проектов Machine Learning и эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

