 1226
1226 
В прошлый раз мы говорили про особенности работы механизмов группировки и сортировки в распределенной среде Impala. Сегодня поговорим про метаданные таблиц в Impala и про то, как их извлекать и выводить на экран. Читайте далее про табличные метаданные в Impala, благодаря которым становится доступным и весьма удобным legacy-проектирование.
Что из себя представляют метаданные таблиц и почему они так нужны Impala
Метаданные — это информация или данные, которые относятся к дополнительной информации о содержимом или объекте. Метаданные, как правило, раскрывают сведения о признаках и свойствах, характеризующих какие-либо сущности (абстрактные объекты), позволяющие автоматически искать и управлять ими в больших потоках информации. Информация о метаданных также важна при legacy-проектировании. Legacy-проект — это уже существующий проект, который нуждается в различных доработках, обновлениях или адаптации под современный стек технологий с целью достижения большей производительности. В Impala под метаданными таблиц понимается информация об объектах таблицы (например, тип столбца, индексы или ключи).
Получение и вывод метаданных Impala-таблиц на экран
Для того, чтобы обратиться к метаданным таблицы в Impala, необходимо выбрать базу данных, таблицы которой необходимо проанализировать на предмет метаданных. Для того, чтобы обратиться к базе данных, в Impala используется SQL-оператор USE. Следующий код на языке Impala SQL отвечает за обращение к базе данных mydb [1]:
[quickstart.cloudera:21000] > USE my_db;
После того, как доступ к необходимой базе данных получен, необходимо узнать, какие таблицы имеются в базе данных Impala (а также уточнить их точные названия, под которыми они хранятся в базе данных). Для этого необходимо вызвать SQL-операцию Impala SHOW TABLES, которая отвечает за вывод названий имеющихся таблиц на экран [1]:
[quickstart.cloudera:21000] > SHOW TABLES

Для того, чтобы получить метаданные таблиц, в Impala существует специальный оператор DESCRIBE, который отвечает за описания всех полей Impala-таблиц. В качестве примера можно получить метаданные таблицы employee [2]:
[quickstart.cloudera:21000] > DESCRIBE employee;
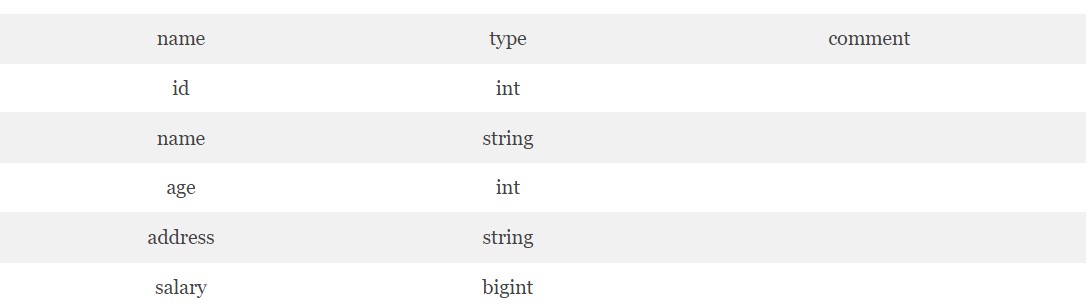
Таким образом благодаря механизму метаданных, Impala обеспечивает разработчиков возможностью удобного legacy-проектирования, а также упрощенного процесса дебаггинга. Это делает Apache Impala весьма удобным и быстрым средством для работы с большими массивами данных.
Больше подробностей про применение Apache Impala в проектах анализа больших данных вы узнаете на практических курсах по Impala в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
MPA: CLOUDERA IMPALA DATA ANALYTICS
ADQM: ЭКСПЛУАТАЦИЯ ARENADATA QUICKMARTS
ADBR: Arenadata DB для разработчиков
ADB: Эксплуатация Arenadata DB
HBASE: Администрирование кластера HBase
HIVE: Hadoop SQL администратор Hive
NoSQL: Интеграция Hadoop и NoSQL
Источники

