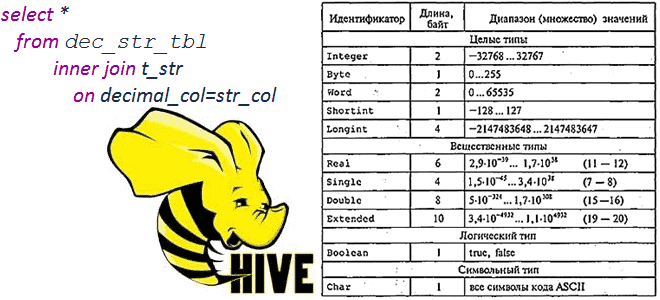
Сегодня рассмотрим тему, полезную для обучения администраторов SQL-on-Hadoop и разработчиков распределенных приложений: операции сравнения и арифметические вычисления между строковыми и десятичными типами в Apache Hive 1.2.0 и 3.1.0, а также MySQL и Microsoft SQL Server 2017. Про типы данных и SQL-запросы в Apache Hive Чтобы упростить сравнение, будем считать типы...

В прошлый раз мы говорили про метаданные в Apache Impala. Сегодня поговорим про функции командной строки в Impala. Читайте далее про особенности работы функций командной строки Impala, благодаря которым становится возможным процесс оптимизации обработки Big Data массивов. Как работают функции командной строки в Impala: особенности оптимизации обработки Big Data Командная...

Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода. Сходства и различия Apache HBase с Google Cloud BigTable...

Добавляя новые интересные примеры в наши курсы для дата-аналитиков, разработчиков распределенных приложений и администраторов SQL-on-Hadoop, сегодня рассмотрим опыт видеоаналитики в компании Vimeo с использованием Apache Spark. Как быстро запросить множество данных из Apache HDFS через Phoenix и Spark из моментальных снимков HBase с минимальным влиянием на кластер. Аналитика очень больших...

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...

Чтобы самостоятельное обучение по Hive стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы DDL-операциями в этой распределенной СУБД, включая особенности их применения. Тест по основам работы с DDL-операциями для новичков Для тех, кто начинает самостоятельное обучение по Apache Hive, мы предлагаем простой интерактивный тест по этой...

В прошлый раз мы говорили про DML-операции в Hive. Сегодня поговорим про DDL-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к объектам, хранящимся в этой СУБД. Читайте далее про особенности работы DDL-операции в Hive. DDL-операции в СУБД Apache Hive DDL-операции (Data Definition Language, Язык Определения Данных)...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...

Чтобы самостоятельное обучение по Hive стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы DML-операциями в этой распределенной СУБД, включая особенности их применения. Тест по основам работы с DML-операциями для новичков Для тех, кто начинает самостоятельное обучение по Apache Hive, мы предлагаем простой интерактивный тест по этой...