
В этой статье для дата-инженеров и администраторов SQL-on-Hadoop рассмотрим, что такое Cloudera Data Platform Operational Database, как это связано с Apache HBase и Phoenix. Также разберем, каким образом перенести данные из кластера HBase в Cloudera Operational Database, избежав их потери и других подводных камней. Что такое Cloudera Operational Database: назначение...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...
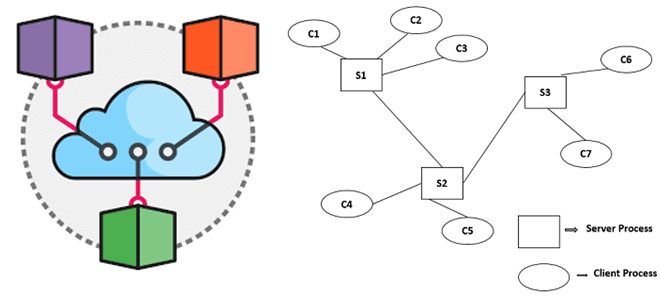
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования. Шаблоны проектирования распределенных систем: что это и...
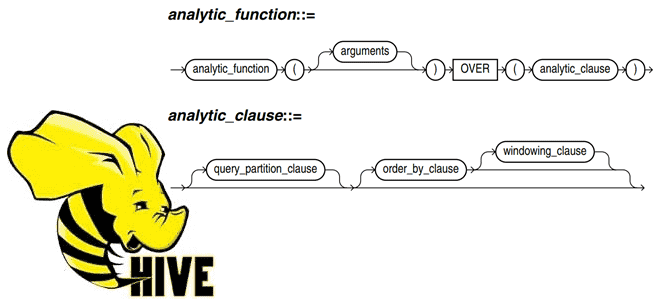
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank(). Генерация порядкового номера строки...

Недавно на примере ИТ-компании Salesforce мы рассказывали про вторичную индексацию таблиц Apache HBase с помощью Phoenix – средства обращения к NoSQL-хранилищу через SQL-запросы. В продолжение этого кейса, сегодня рассмотрим, как были перепроектированы глобальные вторичные индексы для обеспечения более высокого уровня согласованности, чем предлагает Apache Phoenix. Реализация вторичных индексов в таблицах...

Чтобы самостоятельное обучение по Impala стало еще интереснее, сегодня мы предлагаем вам простой комплексный тест по основам работы с различными функциями в этой распределенной СУБД, включая особенности их применения. Комплексный тест по основам работы с функциями в Impala для новичков Для тех, кто начинает самостоятельное обучение по Apache Impala, мы...

В Apache HBase индексация таблиц возможна только по одному полю. Обойти это ограничение позволяет Apache Phoenix - инструмент обращения к NoSQL-хранилищу средствами SQL-запросов. В этой статье для дата-инженеров, архитекторов ИТ-решений и аналитиков данных рассмотрим типы вторичной индексации таблиц HBase в Phoenix и проблемы согласованности вторичных индексов, с которыми столкнулись специалисты...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop, рассмотрим, что такое Trino и как это работает с Apache Hive. А также при чем здесь Presto и зачем коннектор со своей средой выполнения использует Hive Metastore. Что такое Trino и при чем здесь Presto SQL Trino – это механизм запросов для...

Чтобы самостоятельное обучение по Hive стало еще интереснее, сегодня мы предлагаем вам простой комплексный тест по основам работы с различными функциями в этой распределенной СУБД, включая особенности их применения. Комплексный тест по основам работы с функциями в Hive для новичков Для тех, кто начинает самостоятельное обучение по Apache Hive, мы...

Для дата-инженеров и аналитиков про манипулирование данными в Apache Hadoop HDFS средствами SQL-запросов с помощью удобных инструментов. Apache Phoenix для обращения к таблицам NoSQL-хранилища HBase через SQL-запросы из графического интерфейса Hue. Как обратиться к таблицам HBase через SQL-запросы с Phoenix Apache HBase как хранилище данных над Hadoop HDFS предоставляет множество...