 1348
1348 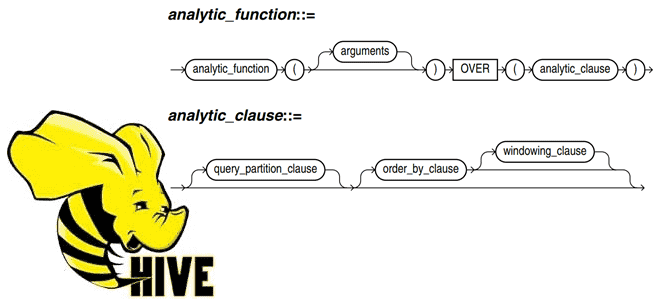
Содержание
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank().
Генерация порядкового номера строки в Apache Hive
Иногда при обработке данных с помощью Apache Hive нужно сгенерировать порядковый номер строки. Например, чтобы создать суррогатные ключи или упорядочить последовательность. Предположим, есть набор данных с ответами на вопросы, которые требуется упорядочить средствами Apache Hive. Для этого сперва создадим внешнюю таблицу:
CREATE EXTERNAL TABLE data_source_raw ( QUESTION STRING ) LOCATION '/user/hive/warehouse/datasource.db/survey_results/';
Задачу установки порядкового номера строки в Hive можно решить с помощью аналитической функции row_number(), которая возвращает восходящую последовательность целых чисел, начиная с 1. Эта функция начинает последовательность заново для каждой группы, созданной предложением PARTITIONED BY. Выходная последовательность включает разные значения для повторяющихся входных значений. Таким образом, результирующая последовательность никогда не содержит дубликатов или пробелов, независимо от повторяющихся входных значений.
На практике функция row_number() чаще всего используется для первых N и нижних N запросов, когда известно, что входные значения уникальны или требуется ровно N строк независимо от повторяющихся значений. Поскольку результирующее значение отличается для каждой строки в результирующем наборе без использования в запросе выражения PARTITION BY, row_number() можно использовать для синтеза уникальных числовых значений идентификаторов, например, для результирующих наборов, содержащих уникальные значения или кортежи. Результаты, возвращаемые этой функцией аналогичны применению RANK и DENSE_RANK в SQL-запросах, но процессы обработки повторяющихся комбинации значений немного отличаются. Чем именно row_number() отличается от rank() с dense_rank(), рассмотрим далее.
ROW_NUMBER vs RANK и DENSE_RANK
Итак, аналитическая функция row_number() в Hive используется для присвоения уникальных значений каждой строке или строкам в группе на основе значений столбца, используемых в предложении OVER.
Функция rank() используется для получения ранга строк в столбце или в группе. Строки с одинаковыми значениями получают одинаковый ранг, а следующее значение ранга пропускается.
Функция dense_rank() также возвращает ранг значения в группе. Строки с одинаковыми значениями критериев ранжирования получают одинаковый ранг в последовательном порядке, т. е. никакие ранговые значения не пропускаются.
Таким образом, row_number() просто возвращает номер строки каждой записи, начиная с 1. В отличие от rank() и dense_rank(), эта функция не будет учитывать никакой связи между строками, даже если в ней присутствуют одинаковые значения. Поэтому row_number() можно использовать для удаления повторяющихся записей в Hive.
Функцию rank() можно использовать для ранжирования строк на основе значения столбца. Но при наличии связи между N предыдущими записями для значения в столбце ORDER BY, функции rank() пропускают следующие N-1 позиции перед увеличением счетчика. Dense_rank() также аналогична функции rank(), но она не пропускает ни одного ранга, даже если между строками есть связь.
Практический пример использования функции row_number()
Итак, после создания таблицы и вставки данных при выполнении HiveQL-запроса с применением функции row_number()имеем следующий результат:
select row_number() over( order by question) id, question from data_source_raw;
Чтобы использовать функцию row_number() и добавить столбец с порядковым номером, следует сообщить столбцу о разделении на более высокий порядок. В нашем примере можно использовать столбец вопроса и создать порядковый номер на его основе. Выполнив запрос, получим упорядоченные вопросы и созданный идентификатор столбца последовательности.
А если нужно создать столбец последовательности на основе порядка вопросов в файле, то при использовании функции row_number() можно упорядочивать данные по NULL:
select row_number() over( order by null) id, question from data_source_raw;
Чтобы упорядочить данные, как в исходном файле, с помощью Apache Hive, можно использовать предыдущий запрос в качестве подзапроса и упорядочить столбец идентификатора по убыванию:
select row_number() over( order by s.id desc) id, s.question from (select row_number() over( order by null) id, * from data_source_raw) s;
Освойте все тонкости работы с Apache Hive для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://jozimarback.medium.com/generating-sequence-number-in-apache-hive-279b73c315df
- https://studywithswati.wordpress.com/2020/06/12/rank-dense_rank-row_number-in-hive/
- http://www.bigdatainterview.com/rank-vs-dense_rank-vs-row_number-in-hive-or-differences-between-rank-dense_rank-and-row_number-or-ranking-window-functions-in-hive/

