 696
696 
Содержание
Для дата-инженеров и аналитиков про манипулирование данными в Apache Hadoop HDFS средствами SQL-запросов с помощью удобных инструментов. Apache Phoenix для обращения к таблицам NoSQL-хранилища HBase через SQL-запросы из графического интерфейса Hue.
Как обратиться к таблицам HBase через SQL-запросы с Phoenix
Apache HBase как хранилище данных над Hadoop HDFS предоставляет множество преимуществ NoSQL, таких как неограниченное масштабирование, миллионы строк, эволюция схемы, обеспечивая возможности, подобные RDBMS: ANSI SQL, простые соединения, готовые типы данных.
Однако, для манипулирования данными HBase использует Java API вместо ANSI SQL, что повышает порог входа в эту технологию и ограничивает круг пользователей. HBase-оболочка не позволяет запускать SQL-запросы к таблицам базы данных подобно реляционным СУБД. Чтобы дата-аналитик или другой пользователь без глубоких знаний Java, мог обратиться к данным, например, выбрать таблицу и фильтровать нужные значения средствами SQL-запроса из пользовательского интерфейса, используются специальные средства. Одним из них является Apache Phoenix, который предоставляет слой SQL поверх HBase, позволяя обратиться к данными привычным большинству аналитиков способом. Подробнее о том, как связаны HBase и Phoenix, а также чем этот механизм отличается от других инструментов класса SQL-on-Hadoop, мы писали здесь и здесь.
Приложения на базе Phoenix выигрывают от скрытой оптимизации HBase, хотя совмещение вычислений с базовым хранилищем может чуть снизить производительность, о чем мы недавно говорили на примере кейса компании Vimeo. Тем не менее, плюсов от совместного использования Apache HBase с Phoenix гораздо больше, чем минусов. В частности, Phoenix реализует криптографический прием защиты данных, называемый «соль» для первичных ключей — так что пользователям HBase не нужно продумывать этот аспект дизайна ключей. Подробнее об этом мы рассказывали на примере проблемы перекоса данных в Apache Spark.
Кроме того, приложения на основе Phoenix отлично существуют вместе с приложениями HBase на одном кластере, позволяя клиентам использовать привычные инструменты бизнес-аналитики и дэшборды аналогично Hive и Imrala. К последним также можно подключить Phoenix.
Чтобы упростить сам процесс обращения к данным, можно использовать веб-интерфейс экосистемы Hadoop — HUE (Hadoop User Experience). Этот open-source продукт распространяется под лицензией Apache 2.0, но принадлежит компании Cloudera. Hue подключается к различным СУБД и NoSQL-хранилищам данных через интерфейсы JDBC или SqlAlchemy – Python-библиотеки для работы с реляционными базами данных с применением объектно-реляционного моделирования (ORM). SQLAlchemy позволяет описывать структуры баз данных и способы взаимодействия с ними на языке Python без использования SQL. Как обратить к данным в HBase через SQL-запросы Phoenix в рамках графического интерфейса Hue, мы рассмотрим далее.
Доступ к данным в Hadoop через графический интерфейс HUE
Чтобы обратиться к данным в HBase с помощью SQL-запросов Phoenix в GUI-интерфейсе Hue, подключившись к NoSQL-хранилищу через SqlAlchemy, следует сперва установить на хосте Hue pyPhoenix: ./build/env/bin/pip install pyPhoenix
Далее в конфигурационном файле конфигурации desktop/conf/hue.ini прописать этот интерфейс подключения:
[notebook]
[[interpreters]]
[[[phoenix]]]
name=phoenix
interface=sqlalchemy
options='{«url»: «phoenix://sql-phoenix.gethue.com:8765/»}’
Затем можно запустить сервер запросов Рhoenix phoenix-queryserver … и запрашивать HBase. Например, выбрать ТОП-10 американских городов мегаполисов: select * from us_population limit 10
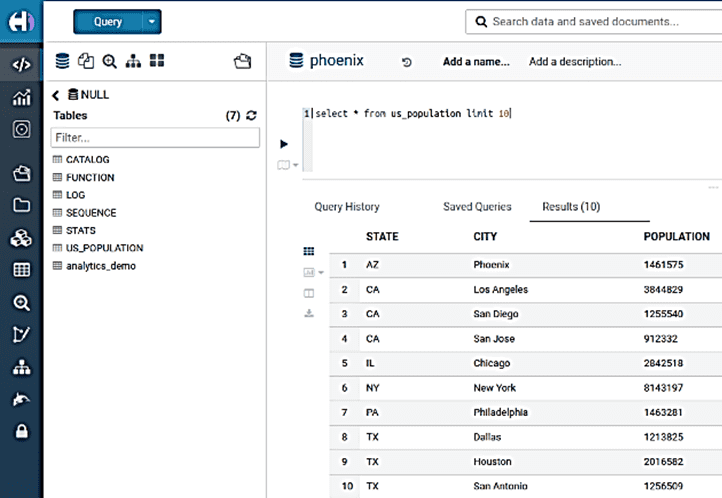
Стоит отметить несколько особенностей доступа к данных в HBase через Phoenix:
- Существующие таблицы HBase должны быть сопоставлены с представлениями Рhoenix
- Рhoenix чувствителен к регистру, поэтому следует внимательно прописывать названия таблиц;
- интерфейс HUE и лежащий в основе SQLAlchemy АРI не видит разницы между любым пространством имен (‘АNY nаmesрасe’) и пустым/по умолчанию (‘emрty/Defаult’).
Очистка исторических в Apache HBase
Чтобы оптимизировать хранение и чтение данных в одном регионе (диапазон записей, соответствующих определенному диапазону подряд идущих первичных ключей), в Apache HBase есть процесс объединения всех файлов HFile в один большой. Это называется уплотнением или сжатием (compaction) и бывает двух типов: малое уплотнение и масштабное уплотнение:
- малое уплотнение (Minor Compaction) запускается автоматически и выполняется в фоновом режиме. Имеет низкий приоритет по сравнению с другими операциями.
- масштабное уплотнение (Major Compaction) запускается вручную или при наступлении определенных условий (триггеров) типа срабатывание по таймеру и пр. Имеет высокий приоритет и может сильно замедлить работу кластера, поэтому следует проводить эту операцию при невысокой нагрузке, поскольку происходят операции дискового ввода-вывода из-за перезаписи данных в хранилище файлов. Здесь же происходит физическое удаление данных, ранее помеченных соответствующей меткой tombston
При масштабном сжатии удаляются все удаленные и просроченные ячейки, а при малом – сохраненные H-файлы. Поэтому для удаления устаревших и неактуальных данных следует запустить масштабное уплотнение. Если требуется удалить все данные за определенный период в таблице HBase, это можно на каждом уровне ее семейства столбцов. Поэтому процесс необходимо удаления придется повторить для всех семейств столбцов в таблице HBase.
При этом нужно установить значение Time To Leave (TTL) – временные метки старше этого значения будут удалены при масштабном уплотнении, а файлы HBase перезапишутся без удаленных данных. Для удаления семейства столбцов во всей таблице следует установить TTL для него. Маркер удаления tombstone записывается, когда происходит явное удаление, во время сжатия они идентифицируются и обрабатываются соответствующим образом. Если удаление происходит из-за истекшего TTL, tombstone не создается, а просроченные данные отфильтровываются и не записываются обратно в сжатое хранилище файлов (StoreFile).
Установить TTL и запустить масштабное уплотнение можно в оболочке hbase:
alter ‘table name’ , NAME => ‘columnfamily’ ,TTL=>value in seconds
major_compact ‘table name’, ‘columnfamily’
Если после масштабного уплотнения в HBase не удалены данные, следует проверить наличие моментальных снимков (snapshot) этой таблицы и удалить их, убедившись, что ранее удаленные данные не будут перемещены в архив при Major Compaction.
Освоить все тонкости работы с Apache HBase для эффективной аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://sidgarg009.medium.com/how-to-overcome-the-challenge-of-nosql-hbase-table-of-querying-the-data-through-sql-queries-firing-c5440ea29996
- https://gethue.com/
- https://ru.wikipedia.org/wiki/SQLAlchemy
- https://abhinavpokuri.medium.com/hbase-history-data-clean-up-quick-read-2d0a13c670cf

