
Недавно на примере ИТ-компании Salesforce мы рассказывали про вторичную индексацию таблиц Apache HBase с помощью Phoenix – средства обращения к NoSQL-хранилищу через SQL-запросы. В продолжение этого кейса, сегодня рассмотрим, как были перепроектированы глобальные вторичные индексы для обеспечения более высокого уровня согласованности, чем предлагает Apache Phoenix.
Реализация вторичных индексов в таблицах HBase с помощью Phoenix
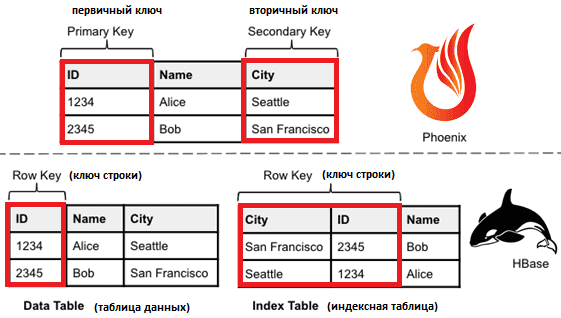
Напомним, распределенное хранилище ключей и значений Apache HBase поверх Hadoop HDFS для манипулирования данными использует Java API, а Phoenix как слой поверх этого NoSQL-хранилища позволяет обратиться к данными с помощью запросов ANSI SQL. Про совместное использование HBase и Phoenix мы писали здесь и здесь.
В таблицах HBase возможен только один индекс, отсортированный по первичному ключу строки. Это увеличивает время поиска данных из-за сканирования всех строк в таблице, чтобы проверить их на соответствие условию фильтра. Вторичная индексация позволяет выполнять точечный поиск и сканирование диапазона по альтернативному ключу, повышая производительность обработки запросов, в которых для поиска используются атрибуты, отличные от первичного ключа. Проблема вторичной индексации таблиц HBase решается с помощью Phoenix, о чем мы подробно рассказывали в прошлой статье.
Глобальные (global) индексы в Phoenix оптимизированные для чтения и реализованы путем соединения базовой таблицы со всеми пользовательскими данными (таблица данных) и физически отдельных таблиц, индексируемых по другому ключу (таблицы индексов). Каждая индексная таблица поддерживается отдельной таблицей HBase, а ее вторичный ключ, реализованный Phoenix, сопоставляется с ключом строки таблицы HBase.
Решение проблемы согласованности для неизменяемых непокрытых индексов
Строгая согласованность означает возвращение одного и того же результата запроса, независимо от источника его обслуживания: таблица данных или индексная таблица. Это означает, что Phoenix должен обновлять таблицу данных и ее индексные таблицы атомарно, чтобы поддерживать их согласованность. Но таблицы распределенного NoSQL-хранилища HBase разделены по горизонтали диапазоном ключей строк на регионы и распределены по разным серверам. Обновление таблицы с глобальными индексами требует обновления нескольких регионов таблицы HBase, распределенных по разным серверам. Это усложняет поддержку согласованности между разными областями одной таблицы. А для изменяемых таблиц еще необходимо поддерживать вставку и обновления существующих строк, которые могут привести к изменению вторичного ключа. В этом случае придется удалить существующую строку индекса со старым ключом и добавить новую. Регион для новой строки индекса может отличаться от прежнего региона. Поэтому удаление и обновление строк индекса в одной и той же таблице индексов может требовать обработки на разных региональных серверах HBase.
Таблица индексов HBase, где хранятся постоянные и неизменяемые ключи вторичного индекса, называется неизменной. Но столбцы связанной с ней таблицы данных могут меняться, если не перезаписываются столбцы, используемые для вторичных индексов. Поэтому, когда строка индекса создается для строки таблицы данных, ее ключ строки действителен до тех пор, пока связанная строка таблицы данных не будет удалена.
Индекс, который используется только для сопоставления вторичного ключа с первичным, называется непокрытым (uncovered) и включает только столбцы, соответствующие столбцам таблицы данных для вторичного и первичного ключей. Непокрытый индекс подразумевает, что индексная таблица сама по себе не используется для обслуживания пользовательских запросов к таблице данных. Индекс нужен для идентификации строк таблицы данных, затронутых конкретным запросом, а остальные значения столбца берутся взяты из таблицы данных. Другими словами, непокрытый индекс никогда не покрывает запрос к своей таблице данных, в отличие от покрытого индекса (covered), когда не нужно возвращаться к таблице данных после нахождения записи индекса.
Если требуется строго согласованное решение только для неизменяемого глобального непокрытого индекса, можно считать таблицу данных является источником истины. Тогда индексная таблица используется только для сопоставления вторичных ключей с первичными ключами, чтобы избежать полного сканирования таблицы. Корректность такого решения обеспечивается, если для каждой строки таблицы данных существует индексная строка. Согласованное обновление таблиц данных и их индексов будет двухэтапным: сперва делается вставка строк индексной таблицы, а затем, в случае успеха первого шага, обновляются строки таблицы данных.
При совместном использовании Apache HBase с Phoenix распределенным приложениям не нужно знать детали индексных таблиц и непосредственно взаимодействовать с ними. Приложение через клиент Phoenix обновляет строку в таблице данных, которое выполняется в соответствующем регионе таблицы HBase сервером этого региона. Сервер региона сперва обновляет индексную таблицу перед обновлением региона таблицы данных, запуская RPC-вызов с ключом строки индекса. Сервер региона для таблицы индексов, скорее всего, будет отличаться от сервера региона для таблицы данных. Поэтому обновление региона индексной таблицы должно выполняться с использованием удаленного вызова процедур (RPC).
Но, поскольку индексные таблицы неизменяемы, вторичные индексные столбцы таблицы данных тоже не изменяются. Поэтому не нужно удалять существующие строки индекса, а достаточно просто вставлять новые строки индекса при обновлении строк таблицы данных. Если обновление индексной таблицы завершается неудачей, можно просто прервать транзакцию записи, не обновляя строки таблицы данных. Хотя это может оставить некоторые устаревшие строки индекса, в целом идея не создает проблемы с корректностью и целостностью информации, т.к. таблица индекса не является источником истины. Всегда происходит возврат к таблице данных для обслуживания запросов, даже если он покрывается таблицей индекса. Устаревшие строки могут быть удалены из индексных таблиц как часть фонового процесса очистки.
Удаление строки в таблице данных происходит в 3 этапа:
- сперва прочитать строку таблицы данных, которую нужно удалить, и ключ строки для соответствующей строки таблицы индексов;
- удалить строку таблицы данных;
- в случае успеха предыдущего шага удалить строку индексной таблицы.
Если возник сбой на втором или последнем этапе, строка таблицы данных может быть удалена, но соответствующая строка индекса остается нетронутой. Впрочем, как уже было отмечено выше, это не создает проблем, поскольку таблица индексов нужна только для сопоставления строк индекса со строками таблицы данных. Если сопоставление указывает на несуществующую строку таблицы данных, можно считать, что строка индексной таблицы устарела и ее следует игнорировать.
Так устаревшие строки индекса будут побочным продуктом сбоев операции записи, их должно быть немного, и они не будут существенно влиять на производительность чтения, а процесс очистки для их удаления не должен выполняться часто.
Если для таблицы данных имеется несколько индексных таблиц, чтобы иметь несколько вторичных индексных ключей в этой таблице данных, обновления и удаления в этих индексных таблицах могут выполняться параллельно. Все строки таблицы индексов могут быть обновлены параллельно на первом этапе двухэтапного обновления, и аналогично все строки индекса могут быть удалены параллельно на последнем этапе трехэтапного удаления.
Согласованность неизменяемых покрытых индексов
Реализовав вышеописанные идеи для непокрытых индексов, инженеры Salesforce решили расширить их до покрытых неизменяемых индексов. Покрытый индекс означает, что запрос может быть обслужен непосредственно из индексной таблицы, если индексная таблица покрывает запрос. Индексная таблица охватывает запрос, если она включает все столбцы для обслуживания этого запроса. Покрытые индексные таблицы могут включать не только первичные и вторичные ключевые столбцы, но и любые другие столбцы таблицы данных для покрытия запросов.
Строго согласованный покрытый индекс подразумевает, что запрос должен давать один и тот же результат независимо от того, обслуживается ли он непосредственно из индексной таблицы или таблицы данных. Чтобы расширить предыдущее решение для покрытых индексов, предотвратив возврат противоречивых результатов запроса, нужно знать, успешно ли обновляются строки таблицы данных после обновления строк таблицы индекса. Для этого следует сохранять информацию о состоянии в каждой строке индекса, добавляя скрытый индексный столбец в индексные таблицы.
Таким образом, при обновлении строки индексной таблицы как часть обновления строки таблицы данных, значение этого скрытого столбца изначально устанавливается как «непроверенное». После успешного завершения обновления строки таблицы данных значение скрытого столбца в строке индекса устанавливается на «проверено». Сохранение информации о состоянии для каждой строки индекса, т.е. есть статус «непроверено»/«проверено» и обновление строки индекса в два этапа сводится к реализации протокола двухэтапной фиксации, т.е. трехшаговому обновлению данных и индексной таблицы. Каждая следующая фаза выполняется только после успешного завершения предыдущей. Если эта трехэтапная операция обновления не завершена, останутся некоторые непроверенные строки индекса в таблицах индексов.
Для удаления строк таблицы данных используется четырехэтапный подход:
- извлечение удаляемой строки из таблицы данных и создание ключей строк индексной таблицы;
- установка для этих строк индексной таблицы статус «непроверенные», чтобы подготовить их к удалению;
- удаление строки таблицы данных;
- удаление строки индексной таблицы.
При обслуживании запросов из таблиц индексов напрямую, проверяется статус строк индекса. Если строка индекса непроверенная, она восстанавливается из строки таблицы данных. Поскольку непроверенные строки индекса существуют в основном из-за сбоев операций записи, строки индексной таблицы почти всегда будут проверены, а их восстановление будет выполняться редко.
Правильность этого решения обусловлена использованием протокола двухэтапной фиксации для обновления индексных таблиц и использованием подхода чтения-восстановления для восстановления строк индекса, которые не прошли успешно обновление двухэтапной фиксации.
На основе этого строго согласованного решения для неизменяемых индексов, инженеры Salesforce реализовали подобную идею для изменяемых индексов Phoenix, что мы рассмотрим в следующий раз.
Разобраться со всеми тонкостями администрирования и использования Apache HBase для эффективной аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

