 1410
1410 
В этой статье для дата-инженеров и администраторов SQL-on-Hadoop, рассмотрим, что такое Trino и как это работает с Apache Hive. А также при чем здесь Presto и зачем коннектор со своей средой выполнения использует Hive Metastore.
Что такое Trino и при чем здесь Presto SQL
Trino – это механизм запросов для разных видов баз данных, что позволяет использовать его как способ быстрого доступа к разнородным источникам информации. Изначально Trino был разработан на базе основан на базе движка Apache Hive под названием Presto, чтобы обеспечить более быстрое выполнение запросов к хранилищам больших данных и озерам данных. Считается, что этот движок появился в 2012 году из-за медленного выполнения запросов к Hive в Facebook.
Trino не хранит данные, а взаимодействует с системами их хранения, разбирая и анализируя переданный SQL-запрос. При этом движок создает и оптимизирует план выполнения запроса, который включает источники данных, а затем планирует рабочие узлы, которые могут интеллектуально запрашивать базы данных – источники для подключения. Подробнее про архитектуру и принципы работы этого MPP-движка читайте в нашей новой статье.
При этом Trino использует инструменты оптимизации самих источников данных, которые имеют специальные индексы и форматы хранения. Целью большинства оптимизаций для Trino является отправка запроса в базу данных и получение только того минимального количества данных, которые нужны для соединения с другим набором данных из другого источника. Также возможно выполнение дополнительной обработки или просто возврат в виде набора результатов запроса.
Trino предоставляет пользователям возможность сопоставлять стандартизированный запрос ANSI SQL, которые имеют настраиваемый DSL запросов. Например, с Trino очень просто настроить каталог Elasticsearch и выполнять в нем SQL-запросы. При этом движок не ограничивается только доступом к данным: можно соединять данные из таблиц разных СУБД, в частности, поисковой системы Elasticsearch с OLTP-базой MySQL. Наконец, Trino позволяет даже соединять друг с другом такие источники данных, где это изначально не поддерживается, к примеру, Elasticsearch и MongoDB.
Таким образом, Trino действует как единая точка доступа для запроса для оезр и корпоративных хранилищ данных, включая Iceberg, Databricks, Hive, Snowflake и пр. Он имеет архитектуру коннекторов, что позволяет подключаться практически к любому источнику данных, написав собственный коннектор, который абстрагирует любую базу данных или службу как просто таблицу в домене Trino. На практике это требуется редко, т.к. для большинства популярных баз данных уже существуют коннектора. Один из них, для работы с Apache Hive мы рассмотрим далее.
Коннектор Trino к Apache Hive
Для доступа к данных в Apache Hive, как и к другим хранилищам и СУБД, Trino использует соответствующий коннектор. Прежде чем заглянуть к нему под капот, напомним основные компоненты и принципы работы этого популярного инструмента SQL-on-Hadoop. Его основными компонентами архитектуры являются следующие:
- среда выполнения (runtime) с логикой обработчика запросов, переводящего SQL-подобный язык запросов (HQL) в задания MapReduce для выполнения над файлами в файловой системе, которой чаще всего является Hadoop (HDFS).
- хранилища файлов (File Storage) в различных форматах и индексных структурах. Форматы файлов могут быть простыми (JSON и CSV) и более сложными файлами: ORC, Parquet и пр. Хотя обычно Hive работает поверх Hadoop HDFS, по мере роста популярности облачных объектных хранилищ типа Amazon S3, Azure Blob Storage, Google Cloud Storage и др., сегодня можно обратиться и к ним.
- Хранилище метаданных (Metastore) для управления метаданными о файлах, такими как столбцы таблицы, расположение файлов, форматы файлов и пр., чтобы сопоставлять таблицы во время выполнения запросов с файлами и каталогами в основном хранилище. Подробно о хранилище метаданных мы писали здесь и здесь.
- Спецификация организации данных Hive, используемая в Trino для совместимости с другими системами.
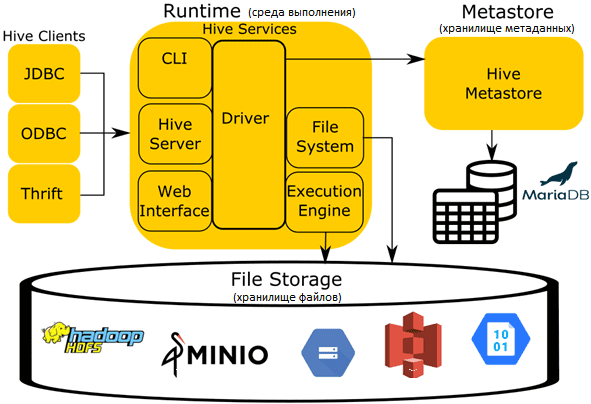
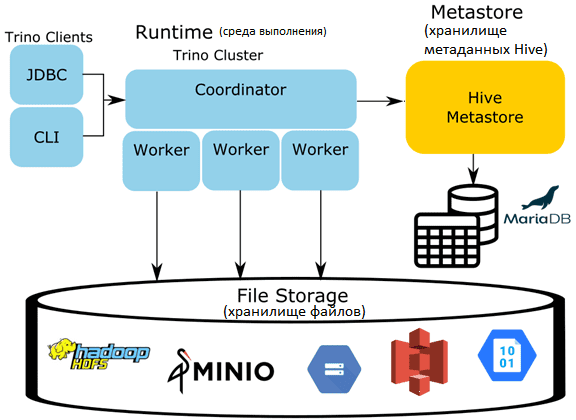
Аналогично Spark, Drill и Impala, Trino использует все эти компоненты, кроме среды выполнения. Собственная среда выполнения Trino заменяет среду выполнения Hive. Metastore остается единственным процессом Hive, используемый во всей экосистеме Trino при использовании коннектора. На самом деле хранилище метаданных – это простой сервис с бинарным API, использующий протокол Thrift. Этот сервис обновляет метаданные, хранящиеся в СУБД (PostgreSQL, MySQL, MariaDB и пр). Вместо Metastore может использоваться облачная альтернатива, например, AWS Glue Data Catalog. Trino не использует HiveQL или какую-либо другую часть среды выполнения Hive. Координатор и все worker’ы должны иметь сетевой доступ к хранилищу метаданных и системе хранения. По умолчанию для доступа к хранилищу метаданных с протоколом Thrift используется порт 9083.
Коннектор Hive поддерживает следующие типы файлов: ORC, Parquet, Avro, RCText (RCFile с колоночной сериализацией и десериализацией ColumnarSerDe), RCBinary (RCFile с отложенной бинарной колоночной сериализацией и десериализацией LazyBinaryColumnarSerDe), SequenceFile JSON (org.apache.hive.hcatalog.data.JsonSerDe), CSV (org.apache.hadoop.hive.serde2.OpenCSVSerde), TextFile.
Коннектор поддерживает чтение из материализованных представлений Hive, которые в Trino представлены в виде обычных таблиц, доступных только для чтения. Представления определяются в HiveQL и хранятся в Metastore. Они анализируются, чтобы разрешить доступ к данным для чтения.
Коннектор поддерживает чтение представлений в трех различных режимах, поведение которых можно настроить в файле свойств каталога:
- Disabled – по умолчанию представления Hive игнорируются, т.е. бизнес-логика и данные, закодированные в представлениях, недоступны в Trino;
- Legacy — простая реализация для выполнения представлений Hive и предоставления доступа для чтения к данным в Trino. Это можно включить, задав параметрам конфигурации translate-hive-views и hive.legacy-hive-view-translation значения true. В случае временного использования устаревшего поведения для определенного каталога можно установить для свойства сеанса каталога legacy_hive_view_translation значение true. Это устаревшее поведение интерпретирует любой запрос HiveQL, определяющий представление так, как это бы выглядело на SQL. При этом не выполняется никакого перевода, а используется близость HiveQL к SQL. Это работает для очень простых представлений, но может привести к проблемам для более сложных запросов. Например, если функция HiveQL имеет идентичную сигнатуру, но поведение отличается от версии SQL, возвращаемые результаты могут отличаться. В некоторых случаях запросы завершатся ошибкой или не будут проанализированы и выполнены.
- Experimental – позволяет анализировать, обрабатывать и переписывать представления Hive с выражениями и операторами. Этот режим поддерживает многие функции представления Hive: UNION [DISTINCT] и UNION ALL, вложенный GROUP BY, current_user(), LATERAL VIEW OUTER EXPLODE, LATERAL VIEW [OUTER] EXPLODE для массива или структуры, LATERAL VIEW json_tuple. Можно включить этот режим, установив свойству translate-hive-views значение true и удалив свойство hive.legacy-hive-view-translation или задав ему значение false. Это необходимо, чтобы убедиться, что устаревшие версии не включены. Однако, в этом экспериментальном режиме некоторые функции Hive не поддерживаются, например, исполнение пользовательских UDF, работа со всеми типами данных Hive и правильное сопоставление с типами Trino, HiveQL current_date, current_timestamp, вызовы отдельных функций, включая translate(), оконные функции, общие табличные выражения и простые выражения case.
Читайте в нашей новой статье, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank().
Освойте использование Trino на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

