
В Apache HBase индексация таблиц возможна только по одному полю. Обойти это ограничение позволяет Apache Phoenix — инструмент обращения к NoSQL-хранилищу средствами SQL-запросов. В этой статье для дата-инженеров, архитекторов ИТ-решений и аналитиков данных рассмотрим типы вторичной индексации таблиц HBase в Phoenix и проблемы согласованности вторичных индексов, с которыми столкнулись специалисты американской компании Salesforce.
Что такое вторичные индексы и зачем они нужны
Самым известным продуктом ИТ-компании Salesforce является одноименная CRM-система, предоставляемая исключительно по модели SaaS. Big Data инфраструктура Salesforce активно использует HBase, однако из-за некоторых специфических особенностей этого NoSQL-хранилища данных его возможностей недостаточно для удовлетворения всех потребностей в аналитике больших данных. Поэтому для работы с HBase дата-инженеры и аналитики данных также применяют Apache Phoenix – реляционную СУБД с интерфейсом SQL, которая использует HBase в качестве хранилища. Для манипулирования данными распределенное хранилище ключей и значений HBase использует Java API, а Phoenix как слой поверх этого NoSQL-хранилища позволяет обратиться к данными с помощью запросов ANSI SQL. Про совместное использование HBase и Phoenix мы писали здесь и здесь.
Можно сказать, что Phoenix расширяет функциональные возможности Apache HBase, включая семантику SQL, соединения и вторичное индексирование. Индекс – это вспомогательная структура данных, которая ускоряет поиск отдельных записей в файле и сокращает время выполнения запросов. Индекс в базе данных аналогичен предметному указателю в книге. Индекс позволяет избежать последовательного или пошагового сканирования файла в поисках нужных данных. Индекс содержит название искомого объекта с одним или несколькими указателями (идентификаторы записей) на место его расположения. Структура индекса связана с определенным ключом поиска и содержит записи из ключевого значения (ключа) и соответствующего адреса логической записи в файле – значения. Файл с логическими записями называется файлом данных, а файл с индексами – индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое чаще всего строится на основе одного поля.
Первичный индекс – это специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по полю ключа, на основе которого создается поле индексации с уникальным значением в каждой записи. Будучи основанным на первичном ключе, первичный индекс может быть только один. А вторичных индексов, определенным по НЕ ключевым полям файла данных, может быть несколько. Ключ поиска для индекса может включать несколько полей, что повышает вероятность ускорения фильтрации нужных данных.
Таким образом, вторичный индекс можно рассматривать как альтернативный способ доступа к данным из основного пути доступа. В таблицах HBase возможен только один индекс, лексикографически отсортированный по первичному ключу строки. Доступ к записям любым способом, кроме как через основную строку, требует сканирования потенциально всех строк в таблице, чтобы проверить их на соответствие условию фильтра. При вторичном индексировании проиндексированные столбцы или выражения образуют ключ альтернативной строки, позволяя выполнять точечный поиск и сканирование диапазона по этой оси.
На практике вторичная индексация, обеспечивающая эффективные запросы к полям, которые не являются первичными ключами, играет центральную роль во многих сценариях использования. В частности, вторичные индексы повышают производительность обработки запросов, в которых для поиска используются атрибуты, отличные от атрибута первичного ключа. Однако такое повышение производительности запросов требует дополнительной обработки по сопровождению индексов при обновлении информации в базе данных. Эта задача решается на этапе физического проектирования структуры таблиц базы данных и связи между ними. А как Phoenix позволяет реализовать вторичную индексацию таблиц HBase, мы рассмотрим далее.
Вторичная индексация таблиц HBase с Phoenix
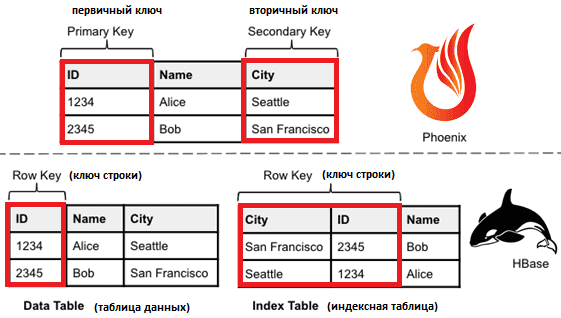
Чтобы показать, как реализуется вторичная индексация в Phoenix, рассмотрим таблицу HBase как набор ячеек, каждая из которых идентифицируется ключом из ключа строки, имени семейства, квалификатора столбца и метки времени. Ячейка содержит значение в виде массива байтов. Таким образом, ячейка — это структура «ключ-значение», а HBase – это распределенное хранилище ключей-значений. Строка идентифицируется ключом строки и представляет собой набор ячеек с этим ключом строки. Строки в таблице HBase сортируются по ключу строки таблицы. Таблицы Phoenix поддерживаются таблицами HBase, и первичный ключ таблицы Phoenix сопоставляется с ключом строки базовой таблицы HBase.
Хотя Phoenix напрямую использует индексирование ключа строки HBase для индексирования первичных ключей своих таблиц, доступ к ним через столбец, который не является первичным ключом, требует сканирования всей таблицы без вторичного индексирования. Это снижает скорость запросов по полям, не являющихся первичными ключами, т.к. сканирование всех строк может быть чрезмерно медленным и дорогостоящим.
Вторичные индексы в Phoenix могут быть нескольких типов:
- Покрытые (covered), когда не нужно возвращаться к основной таблице после того, как мы нашли запись индекса. Вместо этого мы связываем нужные нам данные прямо в строках индекса, экономя время чтения.
- функциональные (functional), доступные в версии 4.3 и выше, позволяют создавать индексы не только для столбцов, но и для произвольных выражений, чтобы получать отдельные записи как результат выполнения запроса вместо всей таблицы данных. Например, индекс для UPPER(FIRST_NAME||‘ ’||LAST_NAME) даст возможность выполнять поиск без учета регистра по объединенным полям имени и фамилии человека.
- Глобальные (global), оптимизированные для чтения. Phoenix реализует глобальное вторичное индексирование путем соединения базовой таблицы со всеми пользовательскими данными и физически отдельных таблиц, индексируемых по другому ключу. Базовая таблица называется таблицей данных (data table), а таблицы для вторичного индексирования, называются индексными (index table). Так каждая индексная таблица также поддерживается отдельной таблицей HBase, а ее вторичный ключ, реализованный Phoenix, сопоставляется с ключом строки таблицы HBase.
- Локальные (local), оптимизированные для записи. Данные индекса и данные таблицы находятся на одном сервере, что предотвращает любые сетевые накладные расходы во время записи. Phoenix автоматически выбирает, использовать ли локальный индекс во время запроса. Локальные индексы можно использовать, даже если запрос не полностью покрыт, поскольку Phoenix автоматически извлекает столбцы, не входящие в индекс, путем сопоставления точек с таблицей данных.
Особенности вторичной индексации и проблема согласованности
При использовании глобальных индексов производительность операций записи снижается из-за необходимости перехватывать обновления таблицы данных (DELETE, UPSERT VALUES и UPSERT SELECT), обновлять сами индексы и отправлять обновления во все соответствующие индексные таблицы. Во время чтения Phoenix выберет индексную таблицу для использования, которая обеспечит самое быстрое время запроса, и напрямую просканирует ее, как и любую другую таблицу HBase. Индекс не будет использоваться для запроса, который ссылается на столбец, не являющийся частью индекса.
Ключ строки индексной таблицы состоит из вторичного ключа для индексной таблицы и первичного ключа для таблицы данных. Добавление первичного ключа к вторичному ключу делает ключ строки уникальным и обеспечивает прямое сопоставление вторичного ключа с первичным. Приложениям Phoenix не нужно знать эти подробности, поскольку они не взаимодействуют напрямую с индексными таблицами. Phoenix отвечает за синхронизацию таблицы индексов с таблицей данных и использует таблицы индексов для ускорения запросов к таблицам данных.
В отличие от глобальных индексов, все локальные индексы таблицы хранятся в одной отдельной общей таблице до версии 4.8.0. А начиная с 4.8.0 все данные локального индекса хранятся в отдельных семействах теневых столбцов в одной таблице данных. Во время чтения с локальным индексом, каждый регион (диапазон записей, соответствующих определенному диапазону подряд идущих первичных ключей) проверяется на наличие индексных данных, поскольку точное местоположение их региона нельзя определить заранее. Поэтому в случае локальных индексов во время чтения возникают некоторые накладные расходы.
Создание отдельной таблицы HBase для каждой индексной таблицы, отсортированной по ключу вторичного индекса, само по себе недостаточно для обеспечения строго согласованной глобальной вторичной индексации в Phoenix. Строгая согласованность означает возвращение одного и того же результата запроса, независимо от источника его обслуживания: таблица данных или индексная таблица. В распределенных системах сохранение содержимого физически разделенных таблиц всегда является согласованным, но обеспечение требуемой производительности и масштабируемости становится проблемой.
Строгая согласованность подразумевает, что Phoenix должен обновлять таблицу данных и ее индексные таблицы атомарно, чтобы поддерживать их согласованность. Таблицы HBase разделены по горизонтали диапазоном ключей строк на регионы, назначенные разным узлам в кластере (региональные серверы), которые обслуживают данные для чтения и записи. Обновление таблицы с одним или несколькими глобальными индексами требует обновления нескольких регионов таблицы HBase, распределенных по разным серверам, усложняя поддержку согласованности между областями таблицы. А для изменяемых таблиц еще необходимо поддерживать вставку и обновления существующих строк. Если обновление существующей строки приводит к изменению вторичного ключа, необходимо удалить существующую строку индекса со старым ключом в дополнение к добавлению новой. Регион таблицы для новой строки индекса может отличаться от области таблицы старой. Поэтому удаление и обновление строк индекса в одной и той же таблице индексов может требовать обработки на разных региональных серверах HBase, ответственных за эти регионы таблицы.
Чтобы решить эти проблемы, инженеры Salesforce решили перепроектировать глобальные вторичные индексы, поскольку некоторые их бизнес-сценарии требуют более высокого уровня согласованности вторичных индексов, чем предлагает Phoenix. Как именно это было реализовано, мы рассмотрим в следующий раз.
Освоить все тонкости работы с Apache HBase для эффективной аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

