
Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...
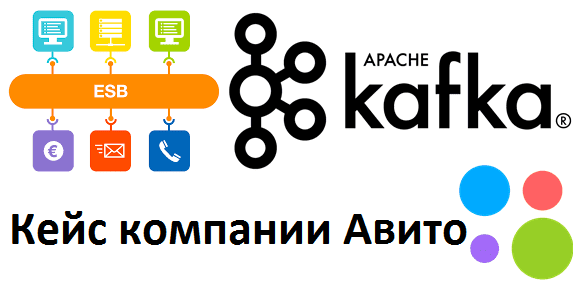
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

Вчера мы рассказывали про самые известные утечки Big Data с открытых серверов Elasticsearch (ES). Сегодня рассмотрим, как предупредить подобные инциденты и надежно защитить свои большие данные. Читайте в нашей статье про основные security-функции ELK-стека: какую безопасность они обеспечивают и в чем здесь подвох. Несколько cybersecurity-решений для ES под разными лицензиями...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...
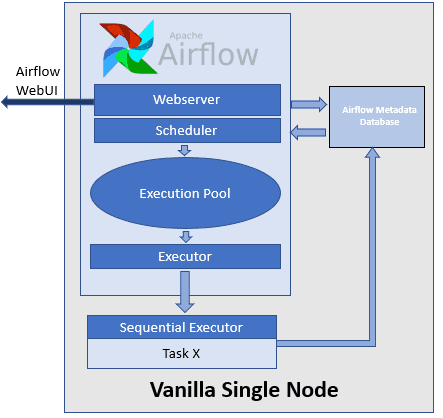
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
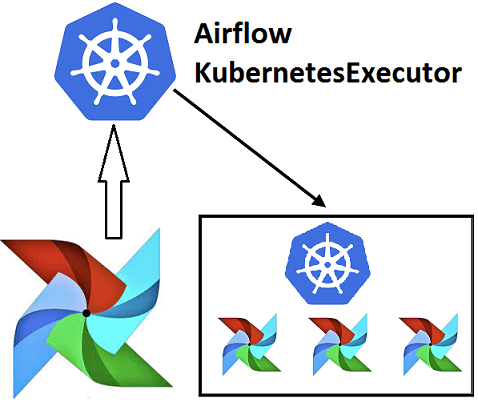
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....
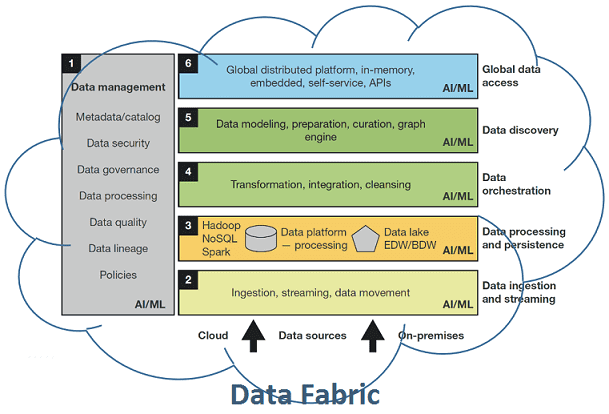
Сегодня мы рассмотрим, что такое Data Fabric, почему этот тренд в аналитике больших данных (Big Data) считается одним из самых перспективных в 2020 году, зачем нужна фабрика данных и как она устроена. Читайте в нашей статье, чем Data Fabric отличается от Data Factory, причем тут цифровизация, DataOps и конвейеры по...