 857
857 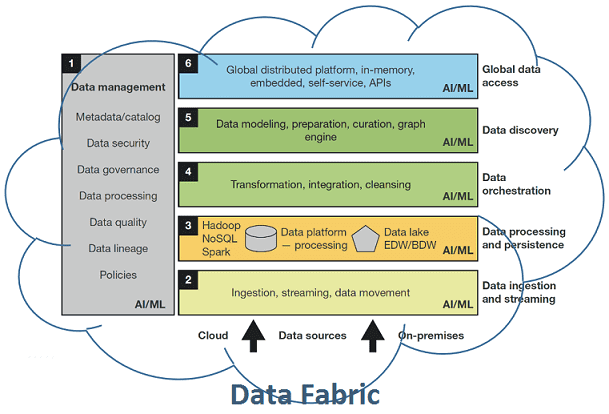
Содержание
Сегодня мы рассмотрим, что такое Data Fabric, почему этот тренд в аналитике больших данных (Big Data) считается одним из самых перспективных в 2020 году, зачем нужна фабрика данных и как она устроена. Читайте в нашей статье, чем Data Fabric отличается от Data Factory, причем тут цифровизация, DataOps и конвейеры по обработке информации.
Что такое Data Fabric
Аналитическое агентство Gartner внесла фабрики данных в ТОП-10 главных трендов 2020 года в области Data Analytics. При этом под «тканью данных» компания подразумевает целую экосистему, которая объединяет повторно используемые сервисы производства данных, конвейеры передачи и обработки информации (data pipelines), а также API-интерфейсы и другие подходов к интеграции данных между различными системами и хранилищами информации для организации беспроблемного доступа и обмен данными в распределенной среде [1].
Отметим различия терминов Data Fabric и Data Factory. Data Factory или фабрика данных от Microsoft Azure — это полностью управляемая облачная ETL-служба с интеграцией данных, которая автоматизирует их перемещение и преобразование, собирая необработанную информацию и трансформируя ее в готовые к использованию сведения с помощью специальных сервисов [2].
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
В свою очередь, согласно Gartner, Data Fabric (DF) – это единая и согласованная архитектура управления данными, которая обеспечивает беспрепятственный доступ к данным и их обработку [3].
Отличительная характеристика современных DF – это активное применение технологий Big Data и искусственного интеллекта (ИИ), в частности, машинного обучения (Machine Learning) для построения и оптимизации алгоритмов управления и практического использования данных. Таким образом, здесь и далее под Data Fabric мы будем понимать именно технологическую экосистему для эффективного использования корпоративной информации, а не конкретную облачную платформу от Microsoft Azure и не офисный «завод» по ручной разметке данных для ИИ, которые сегодня массово появляются в Китае [4].
Почему современным предприятиям нужна Data Fabric
Концепция Data Fabric возникла благодаря активному использованию больших данных в условиях типовых ограничений традиционных процессов управления информацией. В частности, корпоративные Data Lakes на базе Apache Hadoop отлично справляются с хранением множества разрозненных и разноформатных данных. Но эту информацию не просто искать, анализировать и интегрировать с другими датасетами. Это усложняет аналитику больших данных, снижая ценность информации. В свою очередь, интерактивная аналитика и когнитивные вычисления, в т.ч. с помощью методов Machine Learning, требуют высокой скорости доступа к информации, хранящейся в Data Lake. Таким образом, можно сказать, что основными драйверами развития концепции Data Fabric стали потребности в быстрой аналитике Big Data и необходимость распространения BI-подхода на все информационные активы предприятия [5].
Кроме того, для организации, управляемой данными (data-driven) особенно актуальны вопросы обеспечения информационной безопасности. В этом контексте Data Fabric будет обеспечивать защиту данных, реализуя согласованное управление с помощью унифицированных API и настраиваемого доступа к ресурсам. Также ткань данных направлена на поддержку гибкости в прозрачных процессах обновления, аудита, интеграции, маршрутизации и трансформации данных для конкретных бизнес-целей [6].
Ткань данных: цифровизация процессов DataOps
Отметим следующие ключевые характеристики DF [6]:
- использование алгоритмов Machine Learning на каждом этапе работы с информацией: от сбора и очистки данных до оптимизации сценариев их использования;
- сквозная интеграция всех источников и потребителей информации, в т.ч. файловых хранилищ, СУБД и озер данных (Data Lake) в единое информационное пространство с помощью API-интерфейсов;
- микросервисная архитектура вместо монолитных продуктов;
- преобладание облачных решений в корпоративном ИТ-ландшафте;
- оркестрация информационных потоков;
- виртуализация, унификация и повышение качества данных;
- быстрота доступа к разнородным данным, в т.ч. из локальных и облачных СУБД, файловых хранилищ, корпоративных Data Lake на базе Apache Hadoop и пр.;
- безопасный многопользовательский режим работы с информацией с гибкой настройкой прав доступа к данным для каждого пользователя.
Таким образом, можно сделать вывод, что фабрика данных является средством реализации процессов современной концепции DataOps, обеспечивая оперативное реагирование на события, высокий уровень прогнозируемости, оптимизации обработки и обслуживания ресурсов [7]. В свою очередь, DataOps можно рассматривать как один из инструментов цифровизации бизнеса для перевода предприятия в режим data-driven.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
24 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как устроена ткань данных: Big Data и не только
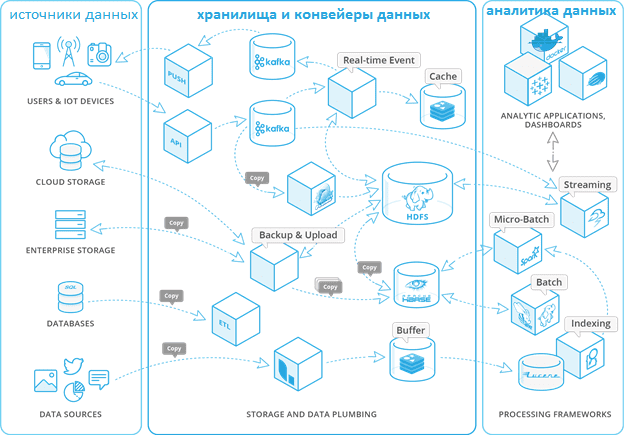
На текущий момент Data Fabric – это тренд в области Big Data и корпоративного ИТ-сектора, а не готовые технологические решения. На практике сегодня для сквозной интеграции и ETL/ELT-процессов используется вся мощь технологий Big Data: Apache Kafka, Spark, Hadoop, Hive, NiFi, AirFlow и прочие средства для сбора, обработки, маршрутизации и преобразования пакетных и потоковых данных в различных форматах.
Помимо упомянутых и других инструментов Big Data, а также базовых положений DataOps, концепция Data Fabric еще дополнена семантическими графами, которые позволяют определять, стандартизировать и согласовывать значение всех входящих данных в бизнес-терминах, понятных для конечных пользователей [5]. Примечательно, что графовую аналитику Gartner также относит к наиболее перспективным трендам 2020 года [1].
Наконец, ткань данных по максимуму использует весь потенциал облачных технологий, виртуализируя все компоненты ИТ-инфраструктуры, от наборов информации до программных приложений [8]. Подобная сервисная модель соответствует DevOps-подходу, а потому инструменты контейнеризации (Docker, Kubernetes) также относятся к средствам Data Fabric.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
24 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, для развертывания уникальной DF, а также создания непрерывных конвейеров автоматического сбора и обработки информационных пакетов и потоков необходимы совместные усилия всех профильных ИТ-специалистов по большим данным. Потребуется целая команда администраторов Data Lakes, локальных и облачных кластеров, разработчиков распределенных приложений, инженеров и аналитиков данных, а также специалистов по методам Machine Learning.
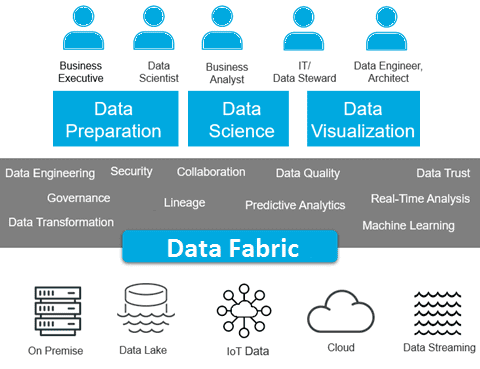
Чем Data Fabric отличается от Data Mesh, читайте здесь и здесь. А освоить все эти подходы на практике для цифровизации своих бизнес-процессов и аналитики больших данных, вы сможете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends/
- https://docs.microsoft.com/ru-ru/azure/data-factory/frequently-asked-questions
- https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo
- https://hightech.plus/2018/11/26/kak-rabotayut-kitaiskie-fabriki-dannih-gde-treniruyut-ii
- https://www.computerweekly.com/blog/Data-Matters/The-Enterprise-Data-Fabric-an-information-architecture-for-our-times
- https://tdwi.org/articles/2018/06/20/ta-all-data-fabrics-for-big-data.aspx
- https://www.itweek.ru/bigdata/article/detail.php?ID=210273
- https://blog.cloudera.com/conquering-hybrid-and-multi-cloud-with-big-data-fabric/

