
Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache Kafka, NiFi, AirFlow, Greenplum, MongoDB, Tarantool, Kubernetes и прочих технологий Big Data.
Где товар или постановка задачи от бизнеса: проблемы, возможности и ограничения
Проблема оперативной инвентаризации товаров, доступных для продажи прямо сейчас, актуальна для любого торгового предприятия. В Леруа Мерлен она усугублялась тем, что помимо сети крупных супермаркетов, в компании также есть склады и так называемые дарксторы. Заказы из интернет-магазинов могут собираться из всех трех торговых баз (супермаркет, склад, даркстор). Но на практике с целью оптимизации доставки, 98% заказов, сделанных на сайте, собираются из торговых залов офлайн-магазина. При этом очень часто пользователи сайта и сборщики заказов сталкиваются с тем, что товар отображается в наличии, хотя на самом деле он уже недоступен для продажи. Например, лежит в корзине у покупателя, находится не на своем месте в торговом зале, спрятан, украден, пропал и т.д. В любом случае, быстро найти нужную вещь из 40 тысяч товаров на 8 000 квадратных метрах, не всегда получается. Поэтому было принято решение показывать в интернет-магазине количество товара, которое чуть меньше того, что есть в действительности, чтобы гарантировать клиенту наличие товара и возможность доставить его в срок. При этом требовалось сократить количество несобранных заказов, не уменьшив общее число заказов и сохранить товарооборот в интернет-магазине. На этапе анализа данных выяснилось, что расхождение между реальным и фактическим количеством товаров возникает по следующим причинам [1]:
- некорректное внесение информации о выставочных образцах (Экспо), которые помечены как доступные к продаже. Однако на самом деле гарантия на них не распространяется, магазин не может их продать, поэтому клиент не должен иметь возможность заказать их. Например, в поле «Экспо» отмечено 0, а в поле «Доступный для продажи» — 1, хотя в на самом деле все наоборот.
- обратная ситуация, когда у товара слишком много выставочных образцов и мало доступных для продажи.
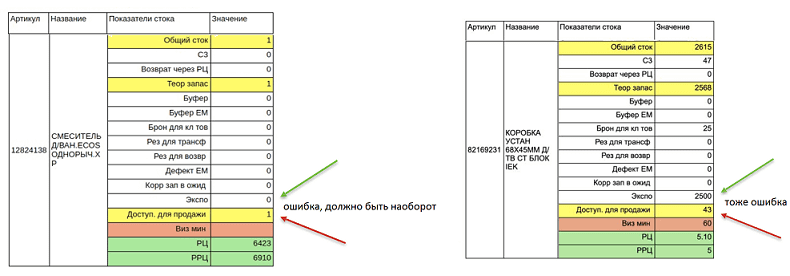
Как Machine Learning ищет аномалии в товарных остатках
Было решено находить аномальные значения и делать поправку на них перед публикации данных о количестве товаров на сайте. С учетом большого числа магазинов (107 на июль 2020 года) и огромного разнообразия товаров, линейные алгоритмы не справлялись бы такой задачей. Поэтому была разработана модель машинного обучения, которая определяет вероятность некорректных данных о товарных остатках в каждом магазине. Отметим некоторые особенности реализации такого алгоритма Machine Learning [1]:
- для предсказаний используется метод градиентного бустинга на деревьях решений с помощью CatBoost – open-source библиотеки машинного обучения от Яндекса [2];
- в качестве обучающей выборки используются результаты ежедневной и ежегодной инвентаризаций, а также данные по отмененным заказам;
- модель использует около 70 предикторов, среди которых данные о последних движениях данного товара в магазине, продажах, возвратах и заказах, номенклатуре, характеристиках товара;
- для проверки качества и подбора геперпараметров модели, данные были разбиты на тестовую и валидационную выборки в соотношении 80/20. При этом модель обучалась на исторических данных, а проверялась на новых;
- сама модель Machine Learning и данные для ее обучения версионируются и хранятся в облачном хранилище Amazon
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
26 мая, 2025
Продолжительность
24 ак.часов
Стоимость обучения
54 000
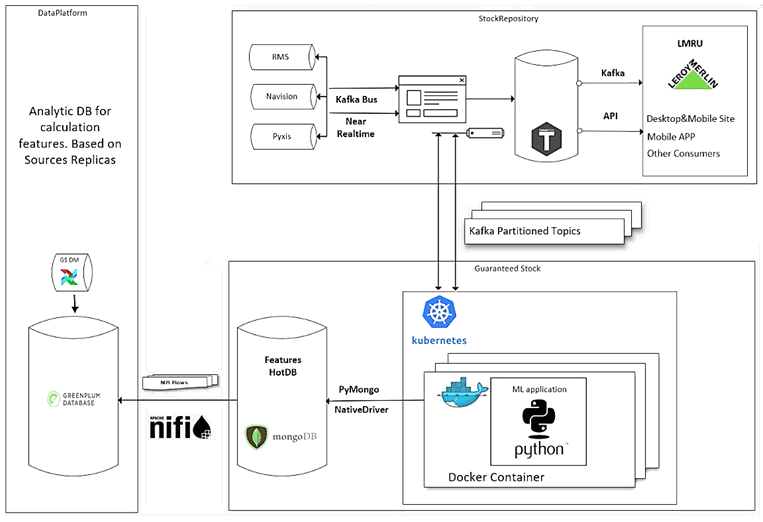
Архитектура системы: Apache Kafka, NiFi, AirFlow, Tarantool, Greenplum и другие Big Data фреймворки
Обучение модели Machine Learning проводится на датасете, который сформирован из показателей операционных и продуктовых систем компании. Эта информация хранится в корпоративном озере данных (Data Lake), развернутом на СУБД Greenplum. На основе этих данных рассчитываются предикторы для машинного обучения, которые хранятся в СУБД MongoDB. Эта документо-ориентированная NoSQL база данных позволяет организовать быстрый доступ к нужной информации. Обмен данными между Greenplum и MongoDB организован с помощью пакетных и потоковых ETL-инструментов Apache AirFlow и NiFi.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
7 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Сама модель Machine Learning реализована в виде Python-приложения, Docker-контейнер которого которое развернут в Kubernetes. Информация о текущем состоянии запасов товара в магазине поступает из прикладных систем в Apache Kafka. Из топиков Кафка алгоритмы машинного обучения считывают данные и обрабатывают их. Кроме роли брокера сообщений, Kafka также используется в качестве корпоративной шины (ESB, Enterprise Serial Bus), объединяя разные приложения-источники данных. Также в рассматриваемой Big Data системе используется резидентная СУБД Tarantool, которая поддерживает SQL-запросы и ACID-транзакции, обеспечивая высокую скорость распределенных вычислений. Именно Tarantool является хранилищем результатов ML-моделирования, предоставляя их для конечных пользователей сайта и мобильного приложения Леруа Мерлен [1].
Тестирование рассмотренной системы на базе технологий Big Data и Machine Learning в 6 разных магазинах торговой сети показало следующие результаты [1]:
- сокращение количества несобранных заказов на 12%;
- рост товарооборота и количества заказов на сайте;
- обученная модель подходит не только для редактирования сведений о товарных остатках перед их публикацией на сайте, но и для оперативной инвентаризации. В частности, она позволяет проверить наличие конкретных товаров для каждого отдела любого магазина, за которыми должны прийти клиенты.
Подробно этот кейс рассмотрен в видеозаписи доклада Марины Калабиной, которая выполняла обязанности product-owner’а в данном проекте [3]. Сам доклад был представлен 30 июня 2020 года на онлайн-митап Avito.Tech для аналитиков [4]. Другой пример применения технологий Big Data в российском отделении Леруа Мерлен читайте в нашей новой статье. Завтра мы продолжим разговор про аналитику больших данных и машинное обучение на производстве и рассмотрим кейсы нефтехимической компании СИБУР.
Как на практике использовать Apache Kafka, NiFi, AirFlow и Greenplum для эффективной аналитики больших данных с помощью моделей Machine Learning в рамках проектов цифровизации своего бизнеса, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Аналитика больших данных для руководителей
- Greenplum для инженеров данных
- Эксплуатация Apache NIFI
- Data Pipeline на Apache Airflow
- Apache Kafka для разработчиков
- Потоковая обработка в Apache Spark
А освоить Python для прикладных Data Science проектов вы сможете на наших новых корпоративных курсах для разработчиков Big Data и аналитиков больших данных:
- Подготовка данных для Data Mining на Python
- Введение в машинное обучение на Python
- Введение в Нейронные сети на Python
Источники

