Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня расскажем, что такое KubernetesExecutor: как он устроен и каким образом позволяет работать с Airflow.
Как запустить AirFlow-DAG в Kubernetes: 2 способа
Предположим, имеется batch-процесс обработки Big Data в виде цепочки задач (DAG, Directed Acyclic Graph) в Эйрфлоу. Задачи этой DAG-цепочки необходимо выполнить в среде Kubernetes (K8s), запустив соответствующий Docker-контейнер на доступном рабочем узле кластера Elasticsearch. Это можно сделать следующими способами [1]:
- использовать KubernetesPodOperator, который выполняет конкретную задачу в модуле (pod) внешнего кластера Kubernetes. Это позволяет развертывать произвольные Docker-образы, снижая взаимные зависимости между контейнерами. Об этом мы немного рассказывали здесь.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
2 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
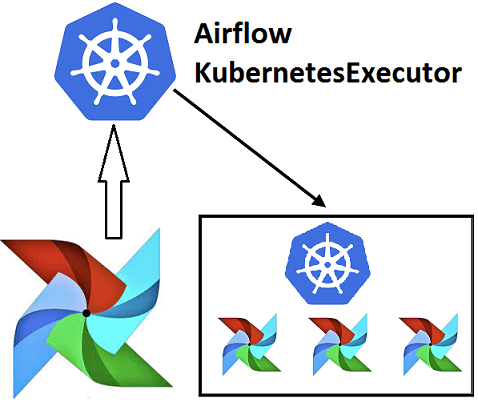
- с помощью KubernetesExecutor, создавая новый pod для каждого экземпляра задачи. В этом случае можно самостоятельно распределить ресурсы, загружая зависимости в Docker-контейнеры. Таким образом, Airflow кластер становится динамичным, не тратя ресурсы на не используемые узлы, в отличие от Celery Executor. Также этот вариант позволяет восстановить состояние кластера, повышая его отказоустойчивость. В этой статье мы рассмотрим подробнее именно данный способ работы с Airflow в K8s.
Напомним, модуль pod — это минимальная единица развертывания в Kubernetes. Этот объект инкапсулирует один или несколько контейнеров с приложениями, ресурсы хранения (общие тома), уникальный сетевой IP-адрес и параметры, определяющие порядок работы контейнеров. Как правило, Kubertenes Pod запускает один Docker-контейнер, соответствующий компоненту конкретного приложения. Таким образом, в связке Airflow и Kubernetes, K8s можно рассматривать как пул ресурсов, дающий простой, но мощный API для динамического запуска сложных развертываний [2].
Чем хорош KubernetesExecutor: 4 полезных факта для DevOps-инженера
Учитывая основное назначение K8s, можно сделать вывод, что KubernetesExecutor решает главную проблему Apache Airflow — динамическое распределение ресурсов. До появления Kubernetes Executor все предыдущие решения включали статические кластеры worker’ов. Поэтому разработчик Data Flow или DevOps-инженер должен был заранее определить, какой размер кластера ему необходим в соответствии с возможными рабочими нагрузками. Такая политика могла привести к чрезмерной или недостаточной подготовке кластера, к потере ресурсов или к снижению производительности. Кроме того, требовалась настройка всех зависимостей worker’ов Airflow, чтобы работать с разнообразными заданиями. В частности, для использования другого исполнителя Эйрфлоу, CeleryExecutors необходимо несколько дополнительных технологий (Celery, RabbitMQ, Redis, Flower и пр.), которые придется контролировать [2]. Подробнее о других исполнителях Эйрфлоу мы расскажем в новой статье.
Таким образом, KubernetesExecutor дает DevOps-инженер следующие преимущества работы с Apache Airflow [2]:
- высокий уровень гибкости, когда кластер Airflow динамически масштабируется в зависимости от рабочей нагрузки, позволит избежать нехватки ресурсов или простаивающих узлов;
- конфигурация подов на уровне задач – поскольку KubernetesExecutor создает новый под для каждого экземпляра задачи, можно точно указать необходимые для конкретного модуля ресурсы (процессор, память и Docker-образ c нужными зависимостями);
- отказоустойчивость, благодаря изоляции задачи в отдельном pod, в случае сбоя она не приведет к выходу из строя целого worker’а Airflow. А при отказе планировщика версионирование ресурсов (функция «resourceVersion») в Kubernetes, позволит быстро вернуться в рабочее состояние.
- упрощенное развертывание, когда можно указать все параметры в одном файле YAML, а зависимости выгружаются в Docker-контейнеры.
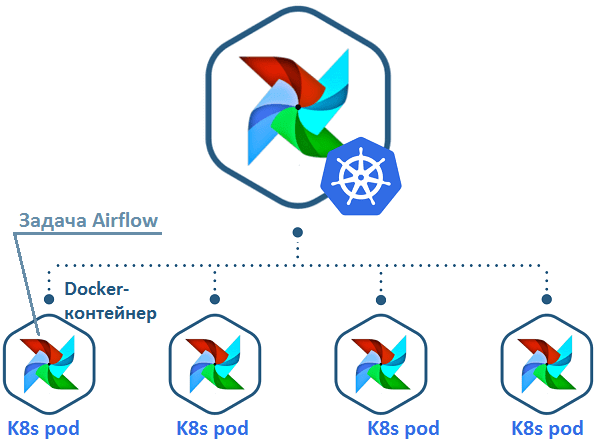
Как запустить KubernetesExecutor в Эйрфлоу
Поскольку по умолчанию Airflow использует только одну папку с файлами DAG, возникает вопрос, как распределить их в кластере K8s. KubernetesExecutor позволяет сделать это 3-мя способами [2]:
- использовать режим Git-init, клонируя Git с Docker-контейнером при инициализации каждого пода;
- работать в постоянном режиме, смонтировав том с DAG-файлами;
- предварительно подготовить Docker-образ с DAG-файлами (режим «pre-bake»).
Код курса
ADH-AIR
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Обычно режимы Git-init и «pre-bake» рекомендуются для разработки и небольших кластеров Эйрфлоу, например, с менее 1000 заданий. Это обусловлено отсутствием распределенных файловых систем в указанных случаях. В свою очередь, режим постоянного тома рекомендуется для больших папок со множеством DAG-файлов [2].
Еще больше практических деталей по работе с Airflow в Kubernetes и не только, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве: