
Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Недавно мы рассказывали об особенностях запуска приложений Apache Spark в кластере Kubernetes с учетом новшеств релиза 3.1.1, где с этого варианта развертывания снят экспериментальный режим. В дополнение к ранее рассмотренным способам оптимизации Спарк-приложений, сегодня разберем, как инженеру Big Data ускорить их при запуске на платформе K8s. Как ускорить Spark-приложения на...

Вчера мы упоминали, что с марта 2021 года в версии Apache Spark 3.1.1 с развертывания на Kubernetes снят экспериментальный режим, внесено множество улучшений для стабильной работы контейниризованных приложений и добавлены другие полезные обновления. Читайте далее, почему развертывание Spark на Kubernetes стало еще проще, как реализуется плавное завершение работы узла без...

С учетом тренда на контейнеризацию при разработке и развертывании любых технологий, в т.ч. Big Data, сегодня рассмотрим плюсы и минусы совместного использования Apache Spark с Kubernetes. Читайте далее, как отправить Спарк-задание в кластер Кубернетес и почему это сэкономит затраты на вашу инфраструктуру аналитики больших данных, не повысив производительность отдельных приложений,...
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL. Apache Kafka...

Хорошие курсы дата-инженеров предполагают не только изучение теории и практики, но и проверку полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по Apache AirFlow. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного фреймворка для автоматизации batch-заданий обработки и...
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

Вчера мы говорили про сложности развертывания множества stateful-приложений Apache Kafka Streams в кластере Kubernetes и роль контроллера StatefulSet, который поддерживает состояние реплицированных задач за пределами жизненного цикла отдельных подов. В продолжение этой темы, сегодня рассмотрим механизм проб, которые позволяют определить состояние распределенного приложения, развернутого на платформе контейнерной виртуализации. В качестве...
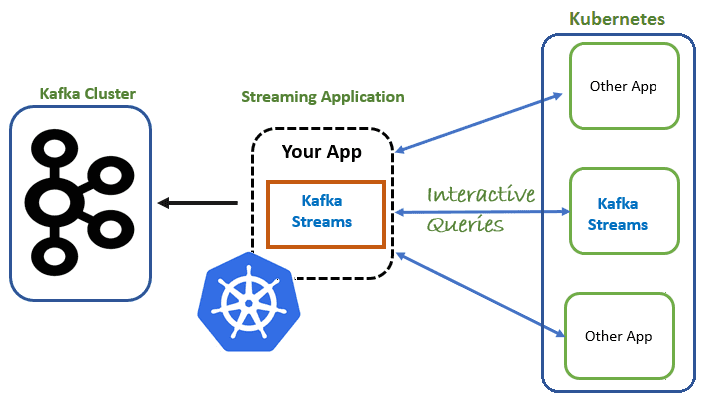
Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet. Что обеспечивает хранение состояний в Apache Kafka Streams Напомним, Kafka Streams – это легковесная...