Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet.
Что обеспечивает хранение состояний в Apache Kafka Streams
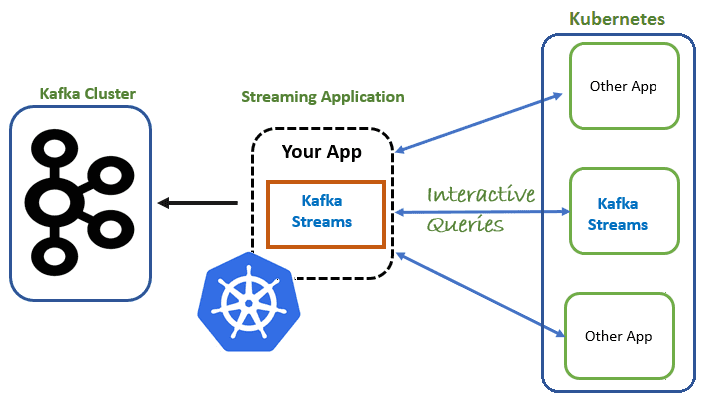
Напомним, Kafka Streams – это легковесная клиентская библиотека, которую можно встроить в любое приложение Java или микросервис, где входные и выходные данные хранятся в кластерах Kafka. Он не имеет внешних зависимостей от других систем, кроме Apache Kafka, обеспечивая горизонтальное масштабирование потоковой передачи данных при сохранении строгих гарантий обработки сообщений в порядке их появления. Kafka Streams поддерживает отказоустойчивое локальное состояние, обрабатывая по одной записи за раз практически в режиме реального времени. Благодаря наличию хранилищ состояний и интерактивных запросов Kafka Streams позволяет разрабатывать stateful-приложения, получая данные об их состоянии извне, что очень востребовано в потоковой обработке Big Data и при взаимодействии с СУБД. Подробнее об отличиях stateful и stateless приложений для аналитики больших данных мы писали в этой статье.
Масштабирование приложений Kafka Streams реализуется через развертывание нескольких его экземпляров. Поскольку каждый экземпляр формирует данные из одного или нескольких разделов топика Kafka, то состояние каждого экземпляра, сохраняется локально, если не используется API GlobalKTable. Kafka Streams поддерживает обработку с отслеживанием состояния с помощью хранилищ состояний: встроенной базы данных RocksDB, хэш-карты в памяти или пользовательской реализации, подключаемую через API процессора. Для всех этих хранилищ состояний Kafka Streams обеспечивает отказоустойчивость, копируя его содержимое в реплицированный топик с сжатым журналом. При сбое одного из экземпляров приложения Kafka Streams, можно восстановить текущее состояние из топика Kafka и продолжить обработку [1].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Для эффективного развертывания и автоматизированного запуска распределенных приложений, в т.ч. Kafka Streams, в лучших традициях DevOps сегодня активно используются технологии контейнерной виртуализации. Наиболее популярной из них является Kubernetes – платформа управления контейнерами, которая позволяет параллельно запускать множество задач, распределённых по тысячам приложений (микросервисов) на разных кластерах в публичном облаке, собственном датацентре, клиентских серверах и пр. О преимуществах развертывания Apache Kafka в кластере Kubernetes мы рассказывали здесь, а как они реализуются технически для stateful-приложений потоковой обработки Big Data, рассмотрим далее.
Зачем нужен контроллер StatefulSet: запуск stateful-приложений в Kubernetes
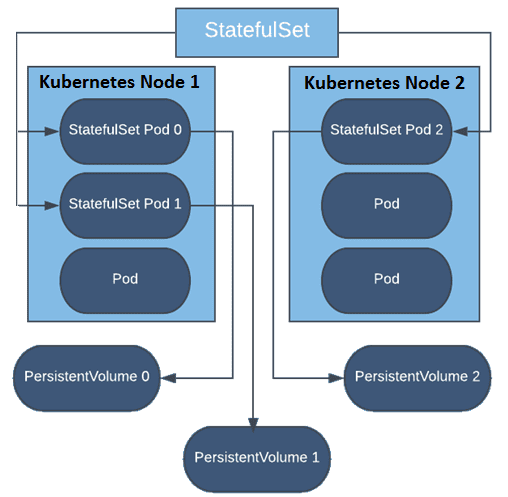
Рассмотрим пример микросервисной Big Data системы, которая включает несколько экземпляров stateful-приложений Kafka Streams. Каждый экземпляр обрабатывает данные из одного или нескольких разделов топика и локально сохраняет связанное состояние в постоянное хранилище (Persistent Volume). Отказоустойчивость обеспечивается за счет описанной выше репликации содержимого каждого хранилища состояний в логах (журналах топиков) Kafka. Однако, в случае сложной топологии вычислений и конвейера обработки данных состояний приложения будет очень много. Поэтому процесс восстановления или обновления состояния из топика резервного копирования Kafka становится весьма затратным с точки зрения времени, пропускной способности сети и пр. Таким образом, нужен способ, который будет гарантировать, что у каждого пода Kubernetes, на котором развернуто приложение Kafka Streams, есть стабильный носитель данных о состоянии приложения. Это означает, что после перезапусков и обновлений приложения его состояние уже присутствует локально на диске, требуется только получить данные о его изменении из топика Kafka. Таким образом, восстановление состояния будет намного быстрее или может даже не потребоваться [1].
Напомним, в Kubernetes применяется концепция контроллеров – контуров управления, которые следят за состоянием кластера и при необходимости вносят или запрашивают изменения, чтобы приблизить текущее состояние к желаемому. Контроллер развертывания (Deployment) использует планировщик (Scheduler) Kubernetes для выполнения указанного количества реплик в любом доступном узле с достаточными ресурсами. Такой подход возможен для приложений без отслеживания состояния (stateless), но непригоден в случае stateful, когда требуется поддерживать постоянные имена или хранилищ для приложений, реплики которых должны существовать в каждом узле или в определенном наборе узлов кластера. В работе со stateful-приложениями в Kubernetes пригодятся его следующие контроллеры [2]:
- StatefulSet для поддержания состояние приложений за пределами жизненного цикла отдельных модулей (pod), например, для хранилища;
- DaemonSet, которые обеспечивают запуск экземпляров на каждом узле с самых ранних этапов начальной загрузки Kubernetes.
Следует только определить приложение в формате YAML с помощью kind:StatefulSet, и контроллер StatefulSet возьмет на себя развертывание требуемых реплик, а также управление ими. Данные сохраняются в постоянном хранилище, которое существует даже после удаления StatefulSet. В StatefulSet каждый под Kubernetes уникален, и это сохраняется при перезапусках, обновлении расписания, сбоях кластера и прочих изменениях.
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
2 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Таким образом, как и контроллер развертывания StatefulSet управляет модулями, основанными на идентичной спецификации контейнера. Но, в отличие от Deployment, StatefulSet поддерживает постоянную идентификацию для каждого пода, созданного на основе одной и той же спецификации. Поды не являются взаимозаменяемыми: у каждого есть постоянный идентификатор, который он поддерживает при любом изменении расписания. Если вы хотите использовать тома хранения для обеспечения устойчивости вашей рабочей нагрузки, вы можете использовать StatefulSet как часть решения. Хотя отдельные модули в StatefulSet подвержены сбоям, постоянные идентификаторы модулей упрощают сопоставление существующих томов с новыми модулями, которые заменяют все вышедшие из строя [3].
Тем не менее, StatefulSet не решает проблему зависания stateful-приложений Kafka Streams при перебалансировке его экземпляров в кластере Kubernetes, о чем мы поговорим завтра.
Подробнее об особенностях администрирования кластеров и разработки Kafka-приложений для аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

