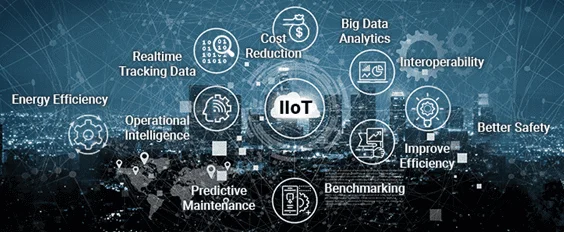
Рассмотрев основные причины задержки активного развития отечественного рынка промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы отметим наиболее значимые факторы роста IIoT-внедрений в России, а также поговорим про тренды этой технологии Industry 4.0, характерные для нашей страны. 7 главных факторов роста отечественного IIoT-рынка Несмотря на то, что доля...

В предыдущей статье мы анализировали текущее состояние промышленного интернета вещей (Industrial Internet of Things, IIoT) на отечественном рынке и рассматривали наиболее перспективные направления развития этого технологического стека. Сегодня мы поговорим про специфические для нашей страны проблемы, которые сдерживают наступление 4-ой промышленной революции (Industry 4.0, I4.0) в России. Основные причины задержки...

Продолжая разговор про мировые тренды развития промышленного интернета вещей (Industrial Internet of Things, IIoT), сегодня мы рассмотрим перспективы отечественного IIoT, а также проанализируем текущее развитие Big Data, Machine Learning и других ключевых технологий 4-ой промышленной революции (Industry 4.0, I4.0) в России. Промышленный интернет вещей в России: 3 главные перспективы Прежде...

В этой статье мы расскажем о 4-ой промышленной революции и прорывных технологиях, показанных на крупнейшей промышленной выставке Hannover Messe-2019: что такое коботы, цифровые близнецы и CMMS-системы, а также как все это связано с Big Data и Industrial Internet of Things. 4-я промышленная революция: что это такое и как она связана...
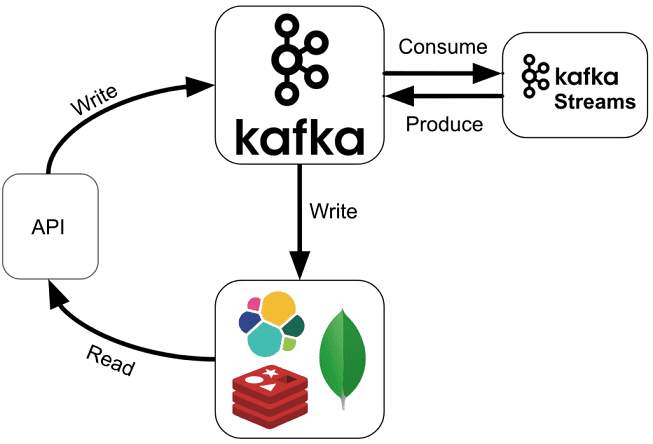
Продолжая разговор про Apache Kafka Streams, сегодня мы расскажем, как API этой мощной библиотеки упрощает жизнь DevOps-инженеру и разработчику Big Data систем. Читайте в нашей статье, как Kafka Streams API эффективно обрабатывать большие данные из топиков Кафка на лету без использования Apache Spark, а также быстро создавать и развертывать распределенные...
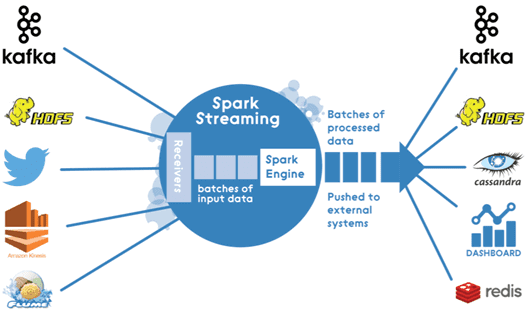
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...
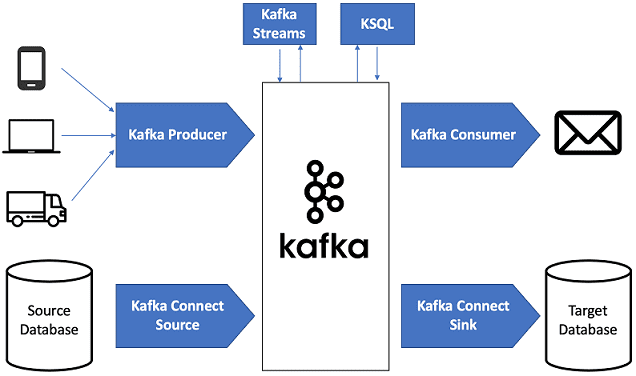
Продолжая разговор про основы Apache Kafka, сегодня мы рассмотрим, почему этот распределённый брокер сообщений стал таким популярным в архитектуре систем Big Data. Читайте в нашей статье, как Кафка обеспечивает высокую производительность процессов сбора и агрегации информационных потоков от множества источников, надежно гарантируя долговечную сохранность сообщений, и эффективно интегрируется с другими...
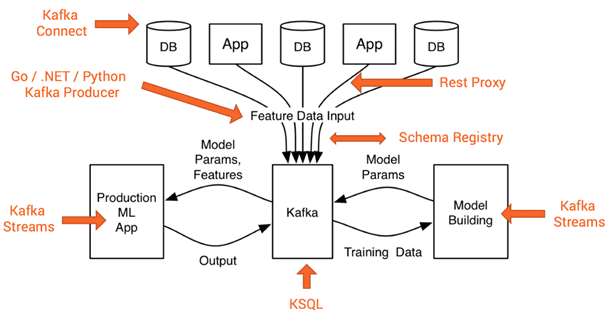
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...

Этой статьей мы продолжаем серию материалов по ИТ-специальностям мира больших данных и начинаем описывать профессиональные компетенции в области Big Data и машинного обучения (Machine Learning). Ищите в сегодняшнем выпуске ответ на главный вопрос новичка Big Data – с чего начать, что нужно знать и уметь, а также где этому учиться...