 805
805 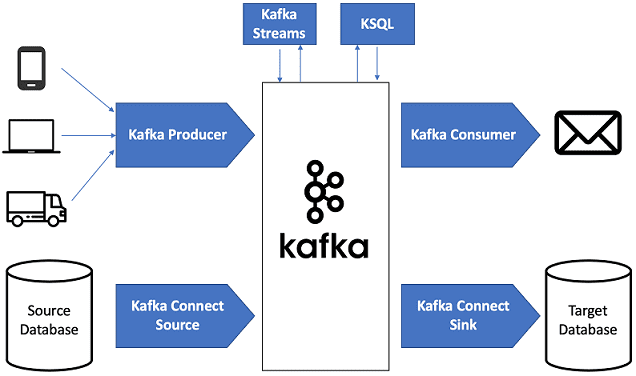
Продолжая разговор про основы Apache Kafka, сегодня мы рассмотрим, почему этот распределённый брокер сообщений стал таким популярным в архитектуре систем Big Data. Читайте в нашей статье, как Кафка обеспечивает высокую производительность процессов сбора и агрегации информационных потоков от множества источников, надежно гарантируя долговечную сохранность сообщений, и эффективно интегрируется с другими хранилищами больших данных.
10 главных преимуществ Apache Kafka в мире Big Data
- Распределенность – отсутствие единой точки отказа за счет распределения данных и программных приложений по узлам кластера.
- Горизонтальная масштабируемость – возможность добавления новых источников данных и узлов с различными характеристиками в единый вычислительный кластер.
- Отказоустойчивость – сохранность сообщений обеспечивается архитектурой master-slave (ведущий-ведомый), механизмом реплицирования и синхронизацией реплик. Потеря сообщений возможна только в случае сбоя ведущего узла и отсутствия участвующих в синхронизации реплик, однако, даже в этом случае есть возможность восстановить смещение необработанного сообщения [1].
- Высокая производительность – Apache Kafka не спроста стала наиболее популярным брокером сообщений в Big Data системах: благодаря своей высокой пропускной способности, возможны чтение и запись более 1 миллиона событий в секунду [2].
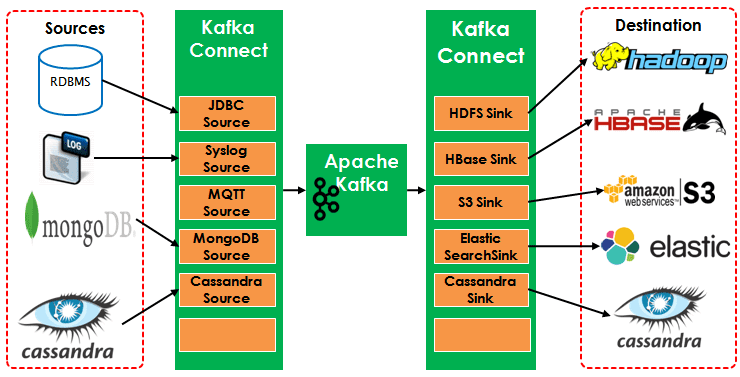
- Интегрируемость – реестр схем данных (Schema Registry) Apache Kafka позволяет работать с различными структурами и форматами представления информации, собственный бинарный протокол на базе TCP дает возможность эффективно взаимодействовать с другими популярными протоколами (REST, HTTP, XMPP, STOMP, AMQP, MQTT) [3], а подключения к базам данных, файловым хранилищам, в т.ч. HDFS Apache Hadoop, и облачным сервисам хранения Big Data реализуются с помощью фреймворка Kafka Connect [4].

Благодаря наличию инструментов обмена данными с другими системами, Apache Kafka легко интегрируется в Big Data инфраструктуру - Долговечность – Kafka гарантирует доставку сообщений путем их сохранения на диске и реплицирования по узлам кластера. Каждое сообщение Apache Kafka хранит в журнале заданный период времени (дни, недели, месяцы) до тех пор, пока он не будет очищен. Частота очитки журнала зависит от объёма данных и дискового пространства, а также схем обмена сообщениями [5].
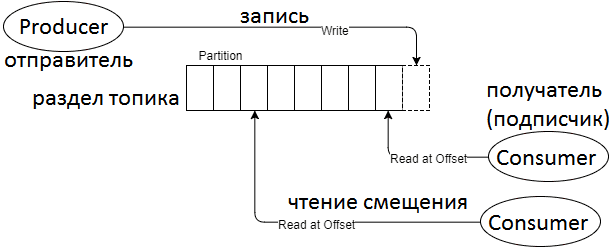
- Надежность – в Кафка присутствует возможность уведомлений о получении сообщений для источников и отслеживание смещения чтения топика для получателей, а также различные стратегии отправки сообщений (строго однократная, как максимум однократная, периодическая, поочередная) [1].
- Достоверность – Kafka сохраняет текущее и прежнее состояние системы, которое можно отследить благодаря механизму смещения в разделах топиков, что обеспечивает достоверность исторических больших данных [5].
- Пакетирование сообщений при поточном режиме работы – благодаря разделению работы по разделам (partition), Кафка эффективно работает с пакетами со стороны получателя [1].
- Безопасность – Apache Kafka предлагает несколько уровней изоляции для транзакций «чтение-обработка-запись». В транзакции могут участвовать сразу несколько топиков (topic) и разделов (partition). Отправитель (producer) начинает транзакцию, создаёт пакет сообщений, завершает транзакцию. Получатель (consumer) может читать сообщения в зависимости от своего уровня изоляции, но независимо от статуса транзакции (завершена, не завершена, отменена). Например, при уровне изоляции «чтение зафиксированного» получатель не видит сообщения, транзакции которых не завершены или отменены, из-за смещения в разделе до первой незавершенной транзакции (Last Stable Offset, LSO) [1]. Подробнее о средствах обеспечения информационной безопасности кластера Apache Kafka читайте в нашей следующей статье.
Как работать с Apache Кафка в production, вы узнаете на практических курсах Администрирование кластера Kafka в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов для руководителей, архитекторов, инженеров, аналитиков Big Data и Data Scientist’ов в Москве.
Источники
- https://habr.com/ru/company/itsumma/blog/437446/
- https://habr.com/ru/company/avito/blog/465315/
- https://kafka.apache.org/protocol
- https://www.learningjournal.guru/article/kafka/kafka-enterprise-architecture/
- https://habr.com/ru/company/itsumma/blog/418389/

