 1476
1476 
Содержание
Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений.
Как работает Apache Kafka
Apache Kafka позволяет в режиме онлайн обеспечить сбор и обработку следующих данных:
- поведение пользователя на сайте;
- потоки информации с множества конечных устройств IoT и IIoT («сырые данные»);
- агрегация журналов работы приложений;
- агрегация статистики из распределенных приложений для корпоративных витрин данных (ETL-хранилищ);
- журналирование событий.
Яркий пример использования Apache Kafka – непрерывная передача информации со smart-периферии (конечных устройств) в IoT-платформу, когда данные не только передаются, но и обрабатываются множеством клиентов, которые называются подписчиками (consumers). В роли подписчиков выступают приложения и программные сервисы. Здесь имеют место отложенные вычисления, когда подписчиков меньше, чем сообщений от издателей – источников данных (producer). Сообщения (messages) записываются по разделам (partition) темы (topic) и хранятся в течении заданного периода. Подписчики сами опрашивают Kafka на предмет наличия новых сообщений, и указывают, какие записи им нужно прочесть, увеличивая или уменьшая смещение к нужной записи. Записанные события могут переигрываться или обрабатываться повторно [1].
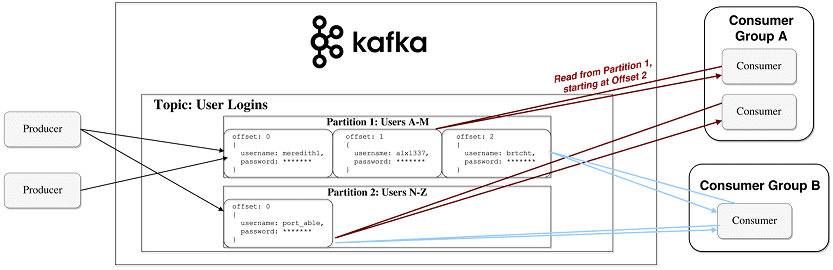
Зачем нужна Кафка в Big Data
Поскольку сообщения скапливаются в топике до их обработки подписчиками, Apache Kafka также называют брокером сообщений и средством для управления очередями в Big Data системах с высокой пропускной способностью сети (сотни тысяч сообщений в секунду). Однако, в отличие от RabbitMQ, другой популярной системы управления очередью сообщений, Apache Kafka является, прежде всего, распределенным реплицированным журналом фиксации изменений [2]. Чем еще отличаются эти брокеры сообщений, читайте в нашей новой статье. Именно с журналированием связаны ключевые сценарии использования Kafka (use-cases) и особенности программной реализации этой системы.
В частности, если необходимо сформировать общий журнал поведения всех пользователей приложения, Кафка поможет собрать и агрегировать логи каждого сеанса от каждого клиента в потоковом режиме (онлайн) [3]. Эта информация, в свою очередь, может использоваться в ETL-процессах (Extract, Transform, Load) для использования в дэшбордах систем интеллектуальной бизнес-аналитики (BI, Business Intelligence) [4].
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Еще один типичный пример Apache Kafka в процессах обработки логов – это сбор и агрегация физических файлов журналов с серверов и помещение их в одном месте, например, в HDFS – файловой системе Apache Hadoop. При этом Кафка обеспечивает чистую абстракцию журнала или событий данных в потоке сообщений. Это значительно снижает задержку обработки Big Data, поддерживая горизонтальное масштабирование с множеством источников данных и распределенными потребителями [5].
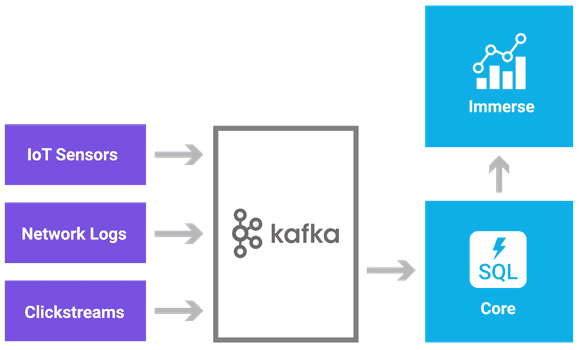
Примеры применения Apache Kafka в Big Data системах
Итак, Кафка позволяет централизовать сбор, передачу и обработку большого количества сообщений в непрерывных информационных потоках, а также хранить эти большие данные, не волнуясь о рисках их потери и производительности системы. С архитектурной точки зрения Apache Kafka может выполнять роль связующего элемента событийно-ориентированной Big Data системы, обеспечивающем взаимодействие отделенных друг от друга микросервисов [1]. Этот факт обусловливает необходимость владения навыками администрирования Apache Kafka для современного DevOps-специалиста, архитектора корпоративной модели данных и инженера Big Data.
С учетом распространения технологий Big Data и цифровизации различных отраслей экономики, в популярность Kafka ИТ-мире растет стремительным образом. Разумеется, наиболее часто эта распределённая, горизонтально масштабируемая система обработки сообщений востребована в организациях, работающих с большими данными.
К примеру, изначально созданный компаний LinkedIn в 2011 году для своих внутренних нужд, Apache Кафка используется этой соцсетью для потоковой передачи данных о деятельности и операционных показателях приложений (LinkedIn News Feed, LinkedIn Today и пр.). Разработчик Big Data систем социальной аналитики, американская компания DataSift, применяет Кафка в качестве коллектора для мониторинга событий и трекера потребления потоков данных пользователями в режиме реального времени. В Twitter Kafka является частью инфраструктуры потоковой обработки.
Foursquare, социальная сеть с функцией геопозиционирования для работы с мобильными устройствами, в т.ч. сотовых телефонов без GPS, использует Apache Kafka для передачи сообщений между онлайн и офлайн-системами, а также для интеграции средств мониторинга в свою Big Data инфраструктуру на базе Hadoop. В корпорации IBM Кафка применяется для обмена сообщениями между микросервисами, обработки событийных и потоковых данных в системах аналитики [5].
В России основными предприятиями, использующими Apache Кафка, являются высокотехнологичные компании финансового сектора, ИТ и телеком: Сбербанк, Тинькофф, Альфа-Банк, Вымпелком, МТС, Ростелеком и прочие организации, работающие с Big Data и Internet of Things. Как именно используется этот брокер сообщений в системах машинного обучения, читайте в нашей следующей статье. А как Кафка используется вместе с другим популярным в мире Big Data DevOps-инструментом, системой автоматизированного управления контейниризованными приложениями, Kubernetes, читайте здесь.
Станьте востребованным специалистом по Apache Кафка на практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
Источники
- https://habr.com/ru/company/piter/blog/352978/
- https://habr.com/ru/company/itsumma/blog/416629/
- https://xdd.silverbulleters.org/t/ta-samaya-kafka-apache-kafka/1984
- https://habr.com/ru/company/ivi/blog/347408
- http://blog.vahan.pro/welcome-to-the-world-of-apache-kafka-part2

