 786
786 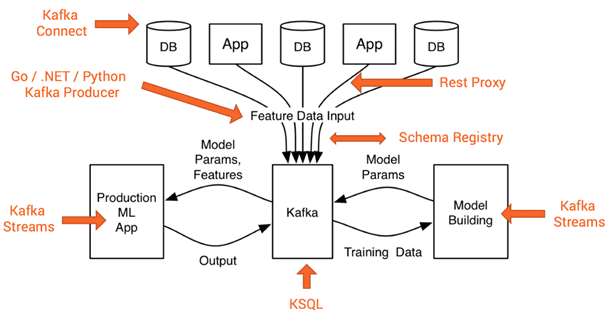
Содержание
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других высоконагруженных средствах обработки и хранения больших данных.
Типовая архитектура Big Data систем с Apache Kafka
Успех современного бизнеса в data-driven мире напрямую зависит от скорости обработки информации и реакции на факты, полученные в результате этого процесса. Например, банку нужно обнаружить мошенничество еще до того, как злоумышленник похитит деньги с кредитной карты клиента, а интернет-магазин стремится предложить посетителю товар, который его заинтересует, только на основании поисковых запросов. Промышленные IoT-платформы с помощью алгоритмов машинного обучения составляют графики профилактического ремонта технологического оборудования, анализируя данные, поступающие со множества датчиков, сенсоров и других smart-устройств.
Таким образом, BI- и ML-системы работают с непрерывными информационными потоками в режиме онлайн, когда источники (приложения, приборы, пользователи) постоянно посылают данные, а сервисы обрабатывают их по мере поступления. В это случае Apache Kafka выполняет роль центрального звена для сбора и агрегации потоковых данных из различных источников. При этом используются специальные программные решения и инструменты Кафка.
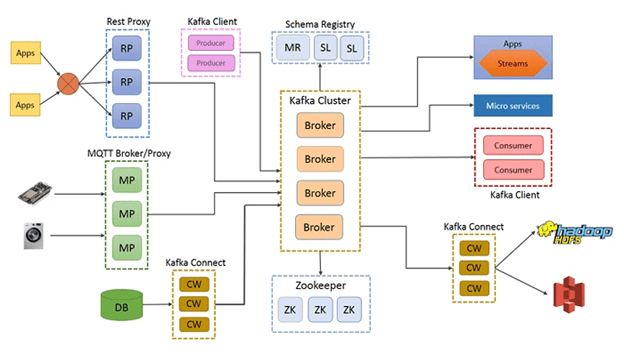
В частности, приложения могут отправлять свои сообщения в кластер Kafka по REST-протоколу, а IoT-устройства – по протоколу MQTT. Подключение к базам данных (реляционным и NoSQL), файловым хранилищам (включая HDFS в Apache Hadoop) и облачным сервисам хранения Big Data (например, Amazon S3) реализуется через фреймворк Kafka Connect [1]. Реестр схем данных (Schema Registry) позволяет работать с различными структурами и форматами представления информации, а для анализа данных в реальном времени, что особенно важно в случае BI-дэшбордов и ML-систем, используется SQL-подобный инструмент KSQL [2].
Централизованное управление всеми распределенными сервисами с гарантированной сохранностью данных и контролем работоспособности каждого узла обеспечивает служба Apache ZooKeeper [3].
Использование Кафка в высоконагруженных ML-системах
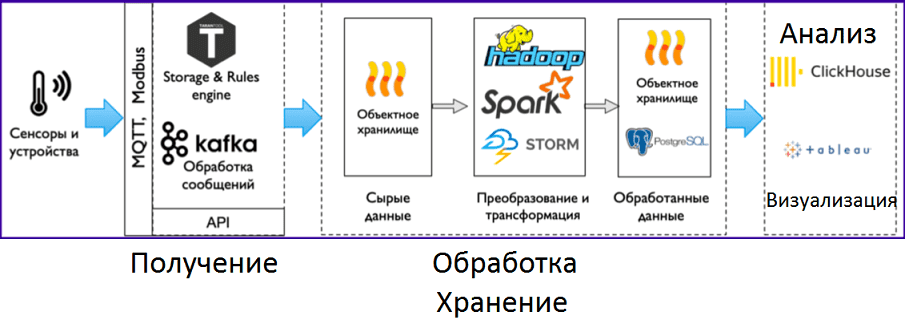
В реальности подобная архитектура реализуется во многих Big Data системах корпоративных и облачных решений. Например, IoT Data Platform на Mail.ru Cloud Solutions использует Kafka на этапе получения сообщений от smart-устройств для последующей их обработки средствами Apache Spark и хранения в Hadoop-кластере. При этом анализ и визуализацию необходимых данных выполняют внешние программные решения – ClickHouse (колоночная аналитическая СУБД от Яндекса) и Tableau (BI-сервис) [4].
Подобным образом с 2014 года Apache Kafka используется сервисом водителей Uber, агрегируя логи (журналы изменений) из реляционных СУБД и нереляционных баз данных типа «ключ-значение» (key-value) с целью ETL-преобразований в рамках BI-аналитики [5].
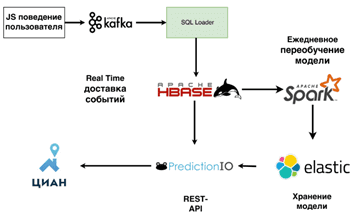
Аналогично Кафка и Apache Spark используются риэлтерской площадкой ЦИАН для сбора данных в режиме реального времени о поведении пользователей с внутренних и внешних источников. После агрегации и соответствующей обработки эта информация используется в моделях машинного обучения для предиктивной и постфактумной BI-аналитики и генерации персонализированных маркетинговых предложений, в частности, рассылок из CRM-системы и онлайн-рекомендаций [6]. Какие именно свойства Кафка используются в этом случае и прочих потребностях обработки данных в Big Data и IoT-системах, читайте в нашей следующей статье.
Узнайте больше про компоненты и средства настройки Apache Кафка на практических курсах Администрирование кластера Kafka в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве.
Источники
- https://www.learningjournal.guru/article/kafka/kafka-enterprise-architecture/
- https://docs.confluent.io/current/schema-registry/schema_registry_tutorial/
- https://ru.bmstu.wiki/Apache_ZooKeeper
- https://mcs.mail.ru/blog/kogda-dannye-slishkom-bolshie/
- https://eng.uber.com/uber-big-data-platform/
- https://www.highload.ru/2017/abstracts/2863/

