
Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
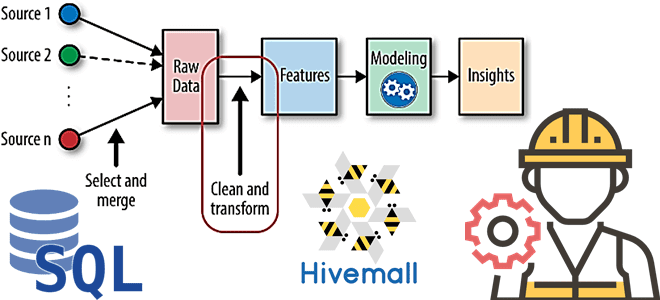
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...

Недавно мы рассказывали про оптимизацию SQL-запросов в PXF – интеграционном фреймворке Greenplum. Сегодня рассмотрим, как этот способ обращения к внешним источникам данных можно применить к задачам машинного обучения на примере распознавания изображений. Platform Extension Framework как инструмент извлечения и преобразования изображений из облачных объектных хранилищ для обучений глубоких нейросетей с...
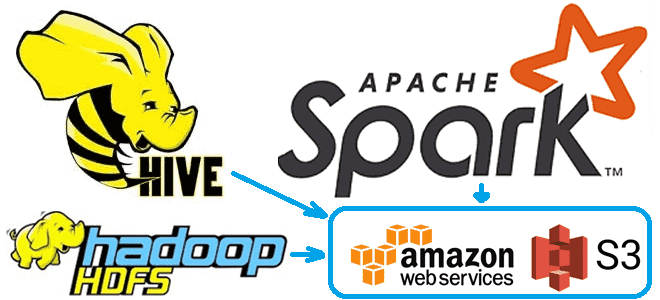
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...
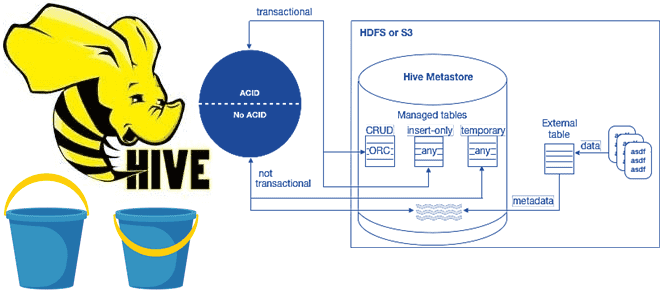
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...
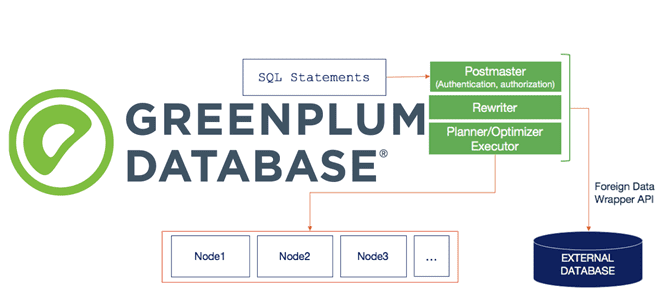
Сегодня продолжим разбираться с интеграционным фреймворком Greenplum и рассмотрим, как PXF реализует SQL-запросы к различным OLAP и OLTP-источникам, поддерживая разные форматы данных. Зачем создавать внешнюю таблицу для Greenplum и какие параметры при этом указывать, а также чем хороша технология оптимизации pushdown. SQL и PXF: интеграция Greenplum с внешними источниками на...
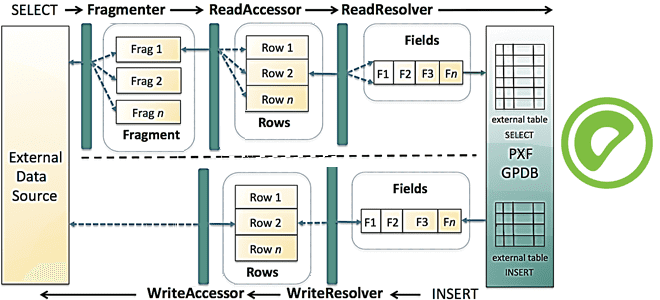
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. Что PXF и зачем...
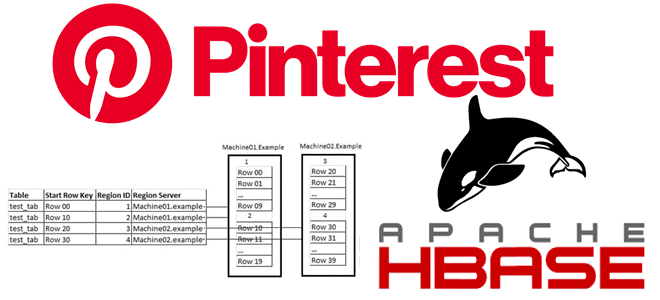
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...