
Пример выявления финансового мошенничества при скимминге банковских карт в банкоматах с помощью технологий Big Data. Как Apache Kafka, Flink и HBase помогут обнаружить злоумышленников в режиме реального времени. Что такое скимминг, как это работает и чем опасно Скимминг является одним из частых видов мошенничества с банковскими картами, представляющий собой считывание...

Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив. Фильтрация данных в статике и динамике Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно...
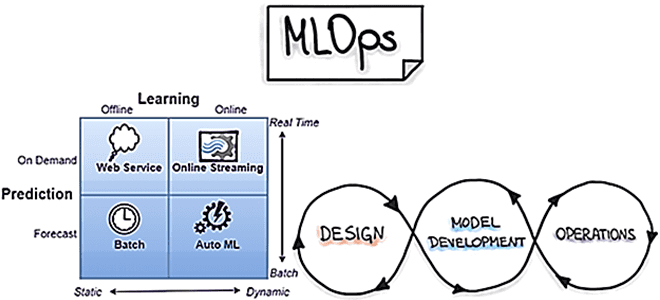
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов. Пакетное прогнозирование и веб-сервисы для MLOps Это...

В этой статье для инженеров данных и разработчиков Hadoop-приложений рассмотрим опыт индийской компании Wynk по применению Apache Flink в качестве средства потоковой аналитики больших данных пользовательского поведения в мобильных приложениях прослушивания музыки. Особое внимание уделим вопросу формирования и обработки пользовательских сессий. Постановка задачи и выбор решения Wynk Music является одним...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...

Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим практический пример построения инфраструктуры для автоматической диагностики и исправления ошибок пакетной и потоковой обработки данных в Netflix. Комплексная система на базе Apache Spark, Kafka, Flink, Druid, сервисов AWS и других технологий Big Data. Предыстория: зачем Netflix разработал Pensive Обработка...

В этой статье для дата-инженеров и разработчиков распределенных приложений разберем кейс американской ИТ-компании FiscalNote, которая использует Apache Flink в качестве движка потоковой обработки информации со сторонних веб-сайтов. Трудности сериализации сообщений из очередей RabbitMQ с разной скоростью поступления Big Data и способы их обхода. Постановка задачи: требования для Flink-приложения FiscalNote специализируется...

Разбираемся с механизмами отказоустойчивости Flink-приложений. Что такое контрольные точки (Checkpoint), чем они отличаются от точек сохранения (Savepoint) и что между ними общего. А также при чем здесь snapshot, что выбирать в разных случаях и как это использовать для отказоустойчивости stateful-приложений Apache Flink. Snapshot как механизм обеспечения отказоустойчивости приложений Apache Flink...
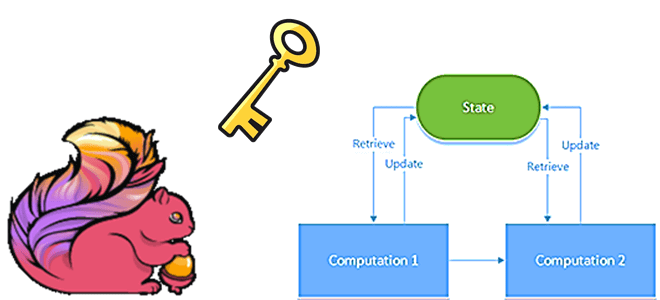
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...