
В этой статье для дата-инженеров и разработчиков распределенных приложений разберем кейс американской ИТ-компании FiscalNote, которая использует Apache Flink в качестве движка потоковой обработки информации со сторонних веб-сайтов. Трудности сериализации сообщений из очередей RabbitMQ с разной скоростью поступления Big Data и способы их обхода.
Постановка задачи: требования для Flink-приложения
FiscalNote специализируется на глобальной политике и анализе рынка. Сочетая ИИ-технологии с экспертным анализом законодательных, нормативных и геополитических данных, компания помогает своим клиентам сокращать риски и увеличивать выгоду из возможностей взаимодействия с правительственными организациями.
Для этого команда инженеров данных FiscalNote поддерживает более сотни скрейперов, которые постоянно собирают законодательные и нормативные данные. Причем вместо простой отправки данных парсеры имеют дело лишь с данными в форме, пригодной для независимой обработки. Эта потоковая передача данных на уровне элементов позволяет изолировать ошибки и хорошо подходит для нужных пользователям функций, например, оповещение о найденном объекте, который соответствует заданным критериям поиска. Однако, синтаксический анализ содержимого веб-страниц связан с последующей его семантической обработкой. Но при автоматизации парсинга трудно добиться полноты собранных данных и их оперативного отображения. В частности, существующая система FiscalNote не могла корректно сопоставить данные, нужные для некоторых клиентских аккаунтов или обобщить бизнес-правила из набора неструктурированных законодательных документов.
Поэтому команде требовалась система, которая сможет выполнять следующие функции:
- отделять парсинг от последующей обработки, сохраняя и кэшируя очищенные данные на неопределенный срок;
- повторно обрабатывать отдельные данные по запросу;
- учитывать любые изменения схемы, внесенные между последним получением данных и временем, когда их следует обработать повторно;
- обогащать данные из парсеров с помощью ручного ввода, а также результатов аналитики и обобщений от команды обработки и анализа данных.
Чтобы реализовать эти требования, дата-инженеры FiscalNote разработали распределенное Flink-приложение, управляемое событиями. Как это было сделано и какие рекомендации можно вынести из этого опыта, рассмотрим далее.
Трудности сериализации сообщений и способы их решения
Решение использовать Apache Flink вместо Kafka Streams было вызвано ограничениями текущей ИТ-инфраструктуры компании, где в качестве корпоративной шины сообщений используется не Apache Kafka, а RabbitMQ. Чем отличаются эти фреймворки и что между ними общего, мы писали в статье «Apache Kafka vs RabbitMQ». Кроме того, Flink поддерживает эволюцию схемы состояний stateful-приложения с помощью Plain Old Java Objects (POJO) и Apache Avro, а также распределение задач из одного DAG’а между процессами. API-интерфейсы Flink с ключевыми состояниями, о чем мы писали здесь, идеально подходили FiscalNote для шаблона нужного доступа к данным. А способность Flink масштабироваться до сотен гигабайт ключевых состояний с помощью RocksDB позволяет не ограничивать срок хранения данных. API потока данных Flink, структура сериализации состояний и богатая экосистема коннекторов дают возможность сосредоточиться на реализации декларативного рабочего процесса, который позволяет аналитикам и автоматизированным системам обогащать извлеченные данные.
Возвращаясь к кейсу FiscalNote первичный поток данных постоянно создается парсерами. В другом потоке данных публикуются различные командные сообщения с описанием того, как внешние системы могут декларативно сообщать Flink-заданию, что оно делать с данными. Например, аналитик может добавить сводку аккаунтов или уточнить имя клиента с помощью системы управления контентом (CMS). Информация из CMS преобразуется в командное сообщение и направляется в задание Flink, кэшируется после получения и применяется к нужным данным. На этом этапе приложение фактически выполняет большую часть работы: поиск данных, полученных ранее от RocksDB, их обогащение и пр. После применения всех командных сообщений очищенные данные выдаются и отправляются по конвейеру в нижестоящие системы.
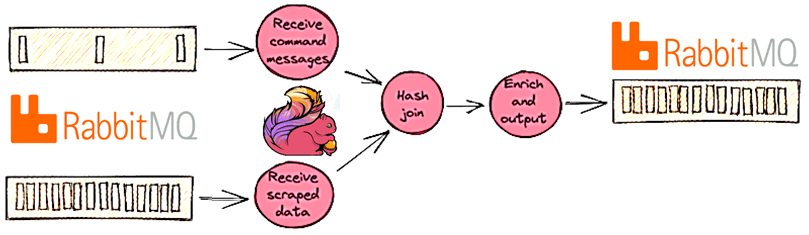
Однако, разная скорость поступления сообщений в поток данных может вызвать проблемы. Автоматизированные парсеры работают и производят данные непрерывно, а люди-аналитики – нет, но именно они чаще всего становятся источниками изменений. Такая непредсказуемость выявила непреднамеренное поведение в коннекторе Flink-RabbitMQ, из-за чего команда остановки Flink зависала на неопределенный срок, если сообщение не поступало в очередь RabbitMQ, используемую заданием Flink, после подачи команды остановки. В результате обновления с отслеживанием состояния невозможны без отправки контрольных значений в медленные потоки данных. С помощью команды разработчиков Flink эта ошибка была исправлена в FLINK-22698. Ранее в потоковом задании с несколькими источниками данных в виде очередей RabbitMQ (RMQSource) запрос остановки с точкой сохранения вел себя непредсказуемо. Хотя обычные контрольные точки и точки сохранения выполнялись успешно, такое поведение наблюдалось только при запросе остановки с точкой сохранения, хотя ожидалось, что запрос остановки с точкой сохранения остановит Flink-задание в состоянии FINISHED. Решением могла стать отправка контрольного значения в каждую из очередей, используемых заданием, которое схема десериализации проверяет в своем методе isEndOfStream(). Этот обходной путь слишком громоздкий и затрудняет обновление с отслеживанием состояния, требуя координации с другой системой. Поэтому в июне 2021 года этот баг был исправлен разработчиками самого фреймворка для версий Apache Flink 1.14.0, 1.12.5, 1.13.2. Также дата-инженеры FiscalNote столкнулись с особенностями сериализации сообщений в Apache Flink, что мы рассмотрим далее.
Сериализация сообщений в Apache Flink
Почти каждое задание Flink должно обмениваться данными между своими операторами. Поскольку эти записи могут быть отправлены не только другому экземпляру в той же JVM, но и отдельному процессу, их необходимо сначала сериализовать в байты. Бэкенд состояния вне кучи основан на локальном встроенном экземпляре RocksDB, который реализован в собственном коде C++. Поэтому серверная часть также требует преобразования в байты при каждом доступе к состоянию. Но некорректная сериализация сильно снижает производительность Flink-заданий, активно потребляя ресурсы ЦП. Flink обрабатывает типы данных и сериализацию с помощью собственных дескрипторов типов, извлечения общих типов и инфраструктуры сериализации типов. Так фреймворк пытается вывести информацию о типах данных задания для сериализации состояний и возможности применять операции группировки, объединения и агрегирования, ссылаясь на имена отдельных полей, например, stream.keyBy(«ruleId») или dataSet.join(other).where(«name»).equalTo(«personName»). Это позволяет оптимизировать формат сериализации и сократить количество ненужных десериализаций, особенно в некоторых пакетных операциях и API-интерфейсах SQL/Table.
Готовую сериализацию Apache Flink можно условно разделить на следующие группы:
- встроенные специальные сериализаторы для базовых типов данных, таких как примитивы Java, массивы, составные типы (кортежи, case-классы Scala, строки) и нескольких вспомогательных типов (Option, Choose, Lists, Maps);
- POJO – общедоступный автономный класс с публичным конструктором без аргументов и всеми нестатическими, непереходными полями в иерархии классов, общедоступными методами получения и установки;
- общие типы данных, определяемые пользователем, которые не распознаются как POJO и сериализуются с помощью Kryo.
Также можно зарегистрировать собственные сериализаторы для пользовательских типов данных, включая интеграцию других систем сериализации типа Google Protobuf или Apache Thrift, через Kryo. Однако, разработчики FiscalNote не использовали резервный Flink-сериализатор Kryo, выбрав встроенный класс PojoTypeInfo для поддержки трассировки сообщений в общем виде.
Парсеры прикрепляют закодированные в JSON метаданные об извлеченном элементе через заголовки RabbitMQ. Эти метаданные позволяют связать ошибки, которые происходят далее по конвейеру с очищенным элементом данных, вызвавшим проблему. Внедряя Flink в существующие парсеры и системами, дата-инженерам FiscalNote пришлось придумать способ поддержки передачи этих метаданных всем операторам в задании Flink. Причем требовался универсальный способ с возможностью повторного применения в разных заданиях Flink, которые обрабатывают разные данные. Кроме того, даже в рамках одного задания Flink операторы могли выполняться в разных процессах на разных машинах.
Решение состояло в разработке универсального класса-контейнера, который сообщал Flink, как сериализовать и десериализовать данные с помощью пользовательского объекта TypeInformation, использующего существующий класс PojoTypeInfo. При этом разработчикам FiscalNote даже не пришлось создавать собственный сериализатор благодаря поддержке эволюции схемы сериализатора POJO, т.к. для любого задания Flink экземпляры универсального класса-контейнера фактически являются POJO.
В целом Apache Flink оправдал ожидания разработчиков и дата-инженеров FiscalNote, позволив реализовать все их идеи для построения комплексного конвейера автоматического сбора данных с веб-страниц, их парсинга, обогащения и быстрого интеллектуального анализа Big Data.
Узнайте больше про администрирование и эксплуатацию Apache Flink для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

