 1027
1027 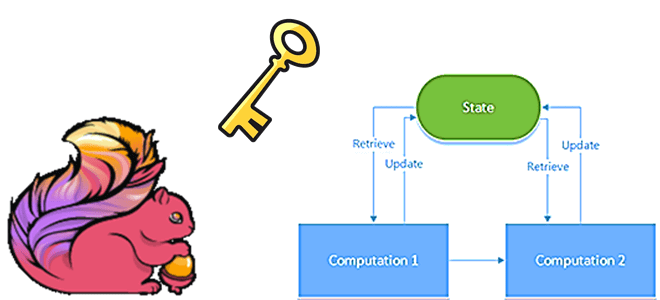
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике.
Состояния в Apache Flink
Apache Flink поддерживает как stateful-, так и stateless-вычисления. Состояния во Flink могут быть 2-х типов: состояние ключа и состояние оператора. Напомним, в Apache Flink 1.14, выпущенном осенью 2021 года, сделан шаг к объединению парадигм потоковой и пакетной обработки информации, о чем мы писали здесь. Flink выполняет пакетные программы как частный случай потоковых, рассматривая пакеты как ограниченные потоки с конечным числом элементов, что мы рассматривали в этой статье.
Состояние Flink может масштабироваться до границ жесткого диска его вычислительного узла с использованием встроенных баз данных, например, RocksDB. Во всех существующих бэкэндах-состояния Flink, оно всегда доступно для выполнения задач локально. Это повышает удобство развертывания, но затрудняет изменения состояний и восстановление после сбоев, приводя к избыточному выделению ресурсов. Поэтому Flink разделяет состояния, используя распределенную базу данных для их хранения.
Состояние с ключом (Keyed State) ограничено ключом и используется в потоке с ключом: например, преобразование keyBy() используется для преобразования потока данных в поток с ключом. Оператор состояния (Operator State) по-другому называется состоянием без ключа и привязано к одному экземпляру параллельного оператора. Именно Operator State используется в коннекторе Flink-Kafka, где каждый параллельный экземпляр потребителя Kafka поддерживает соответствие разделов и смещений топиков в качестве своего оператора состояния. Интерфейсы оператора состояния поддерживают перераспределение состояния между экземплярами параллельного оператора при изменении параллелизма. Чаще всего в stateful-приложении Flink операторы состояния не нужны, а требуются в реализациях источника/приемника и при отсутствии ключа партиционирования состояний. О том, почему в этой ситуации может возникнуть проблема недетерминированного поведения и как с ней бороться, читайте в нашей новой статье.
Оба типа состояний могут существовать в двух формах: необработанное и управляемое. Необработанное состояние рассматривается Flink как необработанные байты с неизвестной структурой данных. Операторы хранят состояние в собственных структурах данных. А управляемое состояние представлено структурами данных, которые контролируются средой выполнения Flink. Рекомендуется использовать управляемое состояние, поскольку в этом случае Flink может автоматически перераспределять его при изменении параллелизма и более эффективно использует память.
Если требуется использовать состояние с ключом, сначала нужно указать ключ в потоке данных DataStream, чтобы обеспечить разделения состояния и самих записей в потоке. Можно указать ключ, используя методы stream.keyBy(KeySelector) в Java/Scala API или stream.key_by(KeySelector) в Python API DataStream. Это создаст поток с ключом KeyedStream, который разрешит операции, использующие состояние с ключом. Функция селектора ключа принимает в качестве входных данных одну запись и возвращает ключ для этой записи. Ключ может быть любого типа и должен быть получен в результате детерминированных вычислений. Модель данных Flink не основана на парах ключ/значение, поэтому не нужно физически упаковывать типы наборов данных в ключи и значения. Ключи здесь являются виртуальными: они определены как функции над фактическими данными для оператора группировки. Подробнее про использование ключей для оконных функций мы рассказываем здесь.
В Apache Flink есть два альтернативных способа определения ключей: ключи кортежа и ключи выражений в Java/Scala API, которое еще не поддерживаются в Python API. Можно указывать ключи, используя индексы полей кортежа или выражения для выбора полей объектов. Рекомендуется применять функцию KeySelector, которая проста при работе с лямбда-выражениями Java и потенциально имеет меньше накладных расходов во время выполнения. Какие бывают типы управляемых состояний с ключом в Apache Flink и как с ними работать, мы рассмотрим далее.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
31 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Типы управляемых состояний с ключом
Интерфейсы с ключевыми состояниями обеспечивают доступ к их различным типам, которые привязаны к ключу текущего входного элемента, позволяя использовать этот тип состояния только в KeyedStream. Apache Flink предлагает следующие типы управляемых состояний с ключом:
- ValueState<T> сохраняет значение, которое можно обновлять и извлекать. Значение, ограниченное ключом входного элемента, можно установить с помощью метода update(T) и получить с помощью value(T). Возможно только одно значение для каждого ключа операции.
- ListState<T> сохраняет список элементов, где T — это тип возможных значений. Значение может быть добавлено к списку с помощью методов add(T) или addAll(List<T>) и итеративно извлечено через Iterable<T> get(). Существующий список можно обновить методом update(List<T>). ListState может быть состоянием списка с ключом или состоянием списка операторов. В первом случае ключ автоматически предоставляется системой, поэтому функция всегда видит значение, сопоставленное с ключом текущего элемента и может согласованно обрабатывать потоки с разделами состояния. В случае состояния списка операторов, список представляет собой набор элементов состояния, которые независимы друг от друга и могут быть перераспределены между экземплярами операторов в случае изменения их параллелизма.
- ReducingState<T> сохраняет одно значение как совокупность всех значений, добавленных к состоянию. Это похоже на ListState, но элементы, добавленные к состоянию, будут объединены с помощью Reduce-функции. Элементы могут быть добавлены с помощью метода add(T) и извлечены через get(T).
- AggregatingState<IN, OUT> также сохраняет одно значение, представляющее совокупность всех значений, добавленных к состоянию. Это похоже на ListState, но добавленные элементы будут предварительно агрегированы с использованием указанной функции агрегации. В отличие от ReducingState<T>, AggregatingState<IN, OUT> тип агрегата может отличаться от типа элементов, добавляемых в состояние. Элементы добавляются с помощью метода add(IN) и извлекаются с помощью get(OUT).
- MapState<UK, UV> хранит список сопоставлений в виде пары ключ/значение, которую можно добавлять, обновлять и получать. Добавление элементов делается с помощью метода put(UK, UV) или putAll(Map<UK, UV>). Метод isEmpty() поможет проверить наличие сопоставления ключ/значение, а contains(UK) – его существование. Значение, связанное с ключом пользователя, можно получить с помощью get(UK). Итерируемые представления для сопоставлений, ключей и значений могут быть получены с помощью методов entries(), keys()и values() соответственно. А remove(UK) позволит удалить сопоставления для данного ключа.
Все состояния могут быть доступны и изменены пользовательскими функциями, а система может согласованно устанавливать контрольные точки как часть распределенных snapshot’ов. Также все типы состояний также имеют метод clear(), который очищает состояние для текущего активного ключа входного элемента. Все эти объекты состояния используются только для взаимодействия с ним. Состояние может находиться на диске или в другом месте. Значение, получаемое из состояния, зависит от ключа входного элемента. Поэтому значение, полученное при одном вызове пользовательской функции, может отличаться от значения при вызове с другим ключом.
Чтобы получить дескриптор состояния, следует создать объект StateDescriptor, который содержит уникальное имя состояния и тип хранимых значений. Также можно указать пользовательскую функцию, например, Reduce. В зависимости от типа состояния создается ValueStateDescriptor, ListStateDescriptor, AggregatingStateDescriptor, ReducingStateDescriptor или MapStateDescriptor.
Доступ к состоянию осуществляется через RuntimeContext, что возможно только в расширенных функциях (RichFunction) через следующие методы:
- ValueState<T> getState(ValueStateDescriptor<T>)
- ListState<T> getListState(ListStateDescriptor<T>)
- ReducingStat <T> getReducingState(ReducingStateDescriptor<T>)
- AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT>)
- MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
Бэкенды состояния хранят метку времени последней модификации вместе со значением пользователя, увеличивая объем, потребляемый хранилищем состояний. Бэкэнд кучи хранит в памяти дополнительный объект Java со ссылкой на объект состояния пользователя и примитивное long-значение. Бэкэнд RocksDB добавляет 8 байтов на сохраненное значение, запись списка или сопоставления. Каким образом американская ИТ-компания FiscalNote использовала API-интерфейсы Flink с ключевыми состояниями, читайте в нашей новой статье. А про опыт индийской компании Wynk мы рассказываем здесь.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
в любое время
Продолжительность
40 ак.часов
Стоимость обучения
89 600
Больше практических примеров по администрированию и эксплуатации Apache Flink для разработки распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

