 560
560 
Содержание
Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив.
Фильтрация данных в статике и динамике
Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно бизнес-целям. Эти фильтры называются статистическими, поскольку их нельзя изменить во время выполнения приложения. Однако, некоторые фреймворки позволяют вносить изменения в фильтрацию без перезапуска приложения. В частности, это возможно в Apache Flink. В качестве примера рассмотрим входные данные от датчика со следующими полями:
- SensorID – идентификатор устройства;
- RegionID — идентификатор региона, где установлен датчик;
- timestamp — время измерения;
- dataType — тип измерения, например, температура;
- value — значение измерения, к примеру, 20 градусов.
Предположим, нужны потоки с разными правилами условий для каждого RegionID. Также требуется изменять правила условий в режиме реального времени. Для этого есть два потока:
- поток метрик, содержащий измерения с датчиков;
- поток фильтра с включенным сжатием ключей, содержащий условия фильтрации.
Фильтры поддерживаются приложением, которое отправляет изменения условий отбора данных в поток сообщений. Чтобы упростить рассматриваемую задачу, опустим обработку входных данных за рамки этой статьи и будем использовать простые объекты для работы с потоками. Экземпляр фильтра выглядит так:
- filterID — идентификатор фильтра;
- isActive – активность фильтра (логическая переменная, которая принимает значения True или False);
- timestamp — метка времени изменения фильтра;
- RegionID — регион, где мы применяем фильтр;
- filterDescription – условие фильтрации, например, «ЗНАЧ», «>=», «10.0».
Фильтрация по потокам с ключами
Сперва рассмотрим соединение между двумя потоками с ключами. О том, что это такое, мы подробно рассматривали в этой статье. Этот подход распределяет фильтры и метрики среди рабочих процессов по ключу. Но если распределение ключей неравномерное, возможен сбой на кластере и другие проблемы, связанные с перекосом данных, о чем мы писали здесь и здесь на примере Apache Spark. Как справиться с этим без перезапуска Flink-приложений, читайте здесь.
Flink позволяет реализовать интерфейс, который может обрабатывать такие соединения между двумя потоками. Первый поток содержит правила условий фильтрации, которые применяются ко второму потоку, содержащего значения измерений с датчиков. Таким образом, необходимо использовать ключевое состояние сопоставления, содержащее идентификатор фильтра и условие для каждой отдельной области, т.е. ключа. В Apache Flink для этого нужно реализовать два метода в интерфейсе RichCoFlatMapFunction. Класс RichCoFlatMapFunction представляет преобразование FlatMap с двумя разными входными типами. В дополнение к этому пользователь может использовать функции, предоставляемые интерфейсом RichFunction.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
12 января, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
В рассматриваемом примере один метод (flatMap2) обрабатывает поток фильтров, а другой (flatMap1) – поток метрик. Фильтр с сообщением isActive=False просто удалит условие фильтра из состояния. Фильтр с сообщением isActive=True добавит или заменит текущее условие фильтра в состояние. Сообщение метрики принимает и применяет все доступные условия в состоянии сопоставления региона. Если все фильтры пройдены, метрика собирается и передается через поток.
Эта идея реализована в следующем коде на Java для Flink-приложения:
class FilteringFunction extends RichCoFlatMapFunction[Metric, MetricFilter, Metric] with LazyLogging{
/**
* Applies filtering function to the metric input.
*/
override def flatMap1(value: Metric, out: Collector[Metric]): Unit = {
val filterState = getRuntimeContext.getMapState(FILTER_STATE_DESCRIPTOR)
val conditions = filterState.values().toList
if (conditions.isEmpty || conditions.forall(_(value)))
out.collect(value)
}
/*
* Applies state management for the filter input.
*/
override def flatMap2(value: MetricFilter, out: Collector[Metric]): Unit = {
if (value.isActive) upsertFilter(value) else removeFilter(value)
}
/**
* Removes a filter from the state
*/
private def removeFilter(metricFilter: MetricFilter): Unit = {
val filterState = getRuntimeContext.getMapState(FILTER_STATE_DESCRIPTOR)
if (filterState.contains(metricFilter.filterID)){
filterState.remove(metricFilter.filterID)
logger.info(s"removed filter from the state - $metricFilter")
}else{
logger.info(s"filter not in the state - $metricFilter")
}
}
/**
* Upserts a filter to the state.
*/
private def upsertFilter(filter: MetricFilter): Unit = {
val filterState = getRuntimeContext.getMapState(FILTER_STATE_DESCRIPTOR)
filterState.put(filter.filterID, filter.filterDescription.toCondition)
logger.info(s"upserted filter into state $filter")
}
}
Поток представляет собой то, как Flink распределяет задачи между рабочими потоками. Регион является ключевым для каждого сообщения. Поэтому Flink применяет функции хэширования, фильтры перераспределения и сообщения метрик для рабочих процессов. Сообщения с одним и тем же ключом будут находиться на одном рабочем процессе с изолированным состоянием.
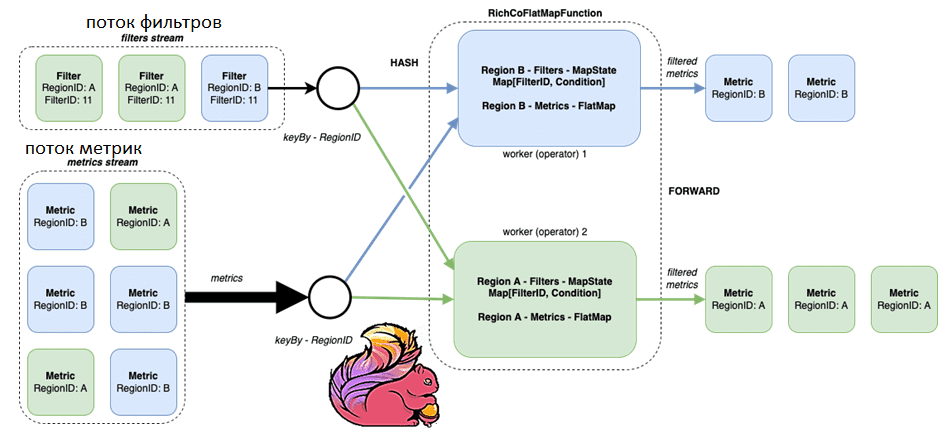
Код на Java для соединения 2-х потоков выглядит следующим образом:
val env = StreamExecutionEnvironment.getExecutionEnvironment val metricsStream = env .addSource(MetricGenerator.getWithPause) // a simple generator .assignAscendingTimestamps(_.timestamp.getTime) val filterStream = env .addSource(FilterGenerator.getWithPause) // a simple generator .assignAscendingTimestamps(_.timestamp.getTime) .keyBy(filter => filter.regionID) // notice keyBy metricsStream .keyBy(metric => metric.regionID) // notice keyBy .connect(filterStream) .flatMap(new FilteringFunction()) .print() env.execute()
В качестве альтернативы рассмотрим фильтрацию с помощью широковещательных потоков.
Широковещательная фильтрация
О том, что такое широковещательное соединение в SQL-запросах и как оно работает, мы подробно рассказывали здесь на примере Apache Spark. Широковещательный подход позволяет избежать повторного разделения данных, сохраняя все фильтры доступными для всех рабочих процессов. Однако это затрудняет управление фильтрами и дублирует все данные фильтров в кластере. Чтобы посмотреть, как это работает, соединим два потока, реализуя интерфейс, который обрабатывает управление фильтрами и их применение. В отличие от предыдущего варианта, здесь будет сохраняться копия условия фильтра для каждого рабочего потока независимо от региона, т.е. широковещательное состояние. Для этого используем интерфейс BroadcastProcessFunction. Этот абстрактный класс расширяет BaseBroadcastProcessFunction и представляет собой функцию, применяемую к BroadcastConnectedStream, которая соединяет BroadcastStream, т. е. поток с широковещательным состоянием, с потоком данных без ключа.
Поток с широковещательным состоянием можно создать с помощью метода DataStream.broadcast(MapStateDescriptor[]) stream.broadcast(MapStateDescriptor)}, реализовав:
- метод processBroadcastElement(Object, Context, Collector), который будет применяться к каждому элементу на broadcast-стороне;
- метод processElement(Object, ReadOnlyContext, Collector), который будет применяться к стороне без широковещательной/ключевой передачи.
Метод ProcessElementOnBroadcastSide() принимает в качестве аргумента контекст, который позволяет ему читать и записывать в состояние вещания, в то время как метод processElement() имеет доступ только для чтения к состоянию вещания.
Таким образом, в нашем случае метод processBroadcastElement реализации интерфейса BroadcastProcessFunction означает обработку предстоящих сообщений фильтра. А другой метод реализации интерфейса BroadcastProcessFunction, processElement представляет фактическую проверку условий фильтрации. Рассмотрим Java-код Flink-приложения:
class BroadcastFilter extends BroadcastProcessFunction[Metric, MetricFilter, Metric] with LazyLogging{
/**
* Gets current filters for a metric key and applies them on metric
*/
override def processElement(value: Metric,
ctx: BroadcastProcessFunction[Metric, MetricFilter, Metric]#ReadOnlyContext,
out: Collector[Metric]): Unit = {
val filters = Option(ctx.getBroadcastState(FILTER_STATE_DESCRIPTOR).get(value.regionID))
filters match {
case Some(filtersMap) => if(filtersMap.values.forall(_(value))) out.collect(value)
case None => out.collect(value)
}
}
/**
* Updates broadcast filter state. Removes filter if it is no longer active.
*/
override def processBroadcastElement(value: MetricFilter,
ctx: BroadcastProcessFunction[Metric, MetricFilter, Metric]#Context,
out: Collector[Metric]): Unit = {
if(value.isActive) upsertFilter(value, ctx) else removeFilter(value, ctx)
}
/**
* Removes inactive filter from the filter broadcast state.
*/
private def removeFilter(metricFilter: MetricFilter,
ctx: BroadcastProcessFunction[Metric, MetricFilter, Metric]#Context): Unit = {
val filterState = ctx.getBroadcastState(FILTER_STATE_DESCRIPTOR)
val conditions = Option(filterState.get(metricFilter.regionID))
conditions match {
case Some(filterMap) =>
val newFilterMap = filterMap - metricFilter.filterID
if (newFilterMap.isEmpty){
filterState.remove(metricFilter.regionID)
} else{
filterState.put(metricFilter.regionID, newFilterMap)
}
logger.info(s"removed filter from the state - $metricFilter")
case None => logger.info(s"filter is not in the state - $metricFilter")
}
}
/**
* Upserts a filter into broadcast state.
*/
private def upsertFilter(filter: MetricFilter,
ctx: BroadcastProcessFunction[Metric, MetricFilter, Metric]#Context): Unit = {
val filterState = ctx.getBroadcastState(FILTER_STATE_DESCRIPTOR)
val filterMap = Option(filterState.get(filter.regionID)).getOrElse(Map())
val newFilterMap = filterMap + (filter.filterID -> filter.filterDescription.toCondition)
filterState.put(filter.regionID, newFilterMap)
logger.info(s"upserted filter into state $filter")
}
}
Flink будет транслировать каждый фильтр каждому доступному рабочему потоку и не будет инициировать перераспределение для предстоящих потоков метрик.
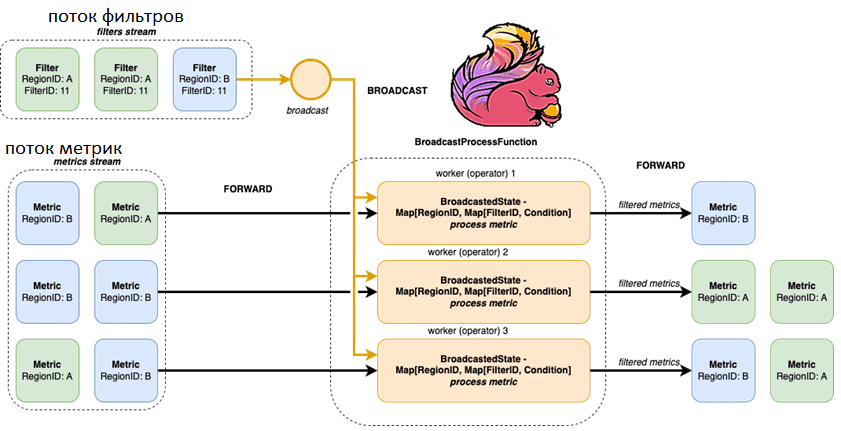
По аналогии с предыдущим подходом вместо keyBy используем широковещательную рассылку для фильтрации потоков:
val env = StreamExecutionEnvironment.getExecutionEnvironment val metricsStream = env .addSource(MetricGenerator.getWithPause) //a simple data generator .assignAscendingTimestamps(_.timestamp.getTime) val filterStream = env .addSource(FilterGenerator.getWithPause) // a simple data generator .assignAscendingTimestamps(_.timestamp.getTime) .broadcast(BroadcastFilter.FILTER_STATE_DESCRIPTOR) // notice we define broadcast state for filters metricsStream .connect(filterStream) //there is no keyBy anymore .process(new BroadcastFilter()) .print() env.execute()
В заключение отметим, что оба рассмотренных варианта не обязательно использовать для только фильтрации как таковой. А как справиться с неравномерным распределением данных в этих кейсах без перезапуска Flink-приложений, читайте в нашей новой статье.
Больше подробностей про администрирование и эксплуатацию Apache Flink и Spark, а также другие технологии потоковой обработки событий для распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Hadoop для инженеров данных
- Потоковая обработка в Apache Spark
[elementor-template id=»13619″]
Источники

