 1113
1113 
Содержание
Пример выявления финансового мошенничества при скимминге банковских карт в банкоматах с помощью технологий Big Data. Как Apache Kafka, Flink и HBase помогут обнаружить злоумышленников в режиме реального времени.
Что такое скимминг, как это работает и чем опасно
Скимминг является одним из частых видов мошенничества с банковскими картами, представляющий собой считывание информации с их магнитной полосы с помощью скиммера — специального технического устройства, которое позволяет злоумышленникам узнать чужой пин-код, чтобы затем скопировать карту и незаконно вывести с нее деньги. Скиммеры (переносные считыватели магнитной полосы) крепятся непосредственно к банкомату и/или к картоприемнику. Чаще всего скиммер включает считывающую магнитную головку, преобразователь, который переводит информацию в цифровой код, а также накопитель, записывающий его на носитель данных. Обычно скиммеры выглядят как специальная накладка на считыватель карт и питаются от миниатюрных батареек. Одни скиммеры накапливают информацию о разных пользователях, а другие сразу передают данные о банковских картах мошенникам с помощью радиоканала или через встроенную сим-карту по сотовой связи.
На практике этот вид мошенничества достаточно распространен, поскольку банкоматы расположены во множестве разных мест, где не всегда присутствует сотрудник службы безопасности или видеокамера. Однако, обнаружить скимминг банковских карт можно даже в режиме реального времени с помощью соответствующих технологий Big Data.
В общем случае алгоритм скиммингового мошенничества с банковскими картами выглядит следующим образом:
- мошенник помещает скимминговое устройство в выбранный банкомат;
- скиммер копирует данные карты, пока она подключена к банкомату;
- после незаконного получения данных о достаточном количестве карт злоумышленник освобождает банкомат от скиммера;
- максимум через 6 месяцев мошенник быстро снимает сумму по каждой карте в другом банкомате подальше от того, где изначально был установлен скиммер, примерно на расстоянии более 1 км.
В соответствии с этим алгоритмом мошенничества можно сделать следующие выводы:
- финансовых потерь при непосредственном скимминге карт в банкоматах нет;
- когда именно будут сняты деньги со скомпрометированных карт, точно неизвестно;
- скимминг и снятие денег выполняются в разных банкоматах, расположенных на определенном расстоянии друг от друга;
- мошенники копируют данные многих карт одновременно;
- злоумышленники пытаются снять деньги с более, чем с одной скомпрометированной карты одновременно в одном и том же банкомате;
- в каждом банкомате одновременно может быть совершена не более одной транзакции;
- информация о карте при скиминге и изъятии средств идентична, то есть опустошенные карты являются подмножеством скопированных карт;
- само скимминговое устройство находится в банкомате не менее чем на один час.
Если бы каким-то образом запомнить комбинации карт из фазы скимминга, то можно было сгенерировать предупреждение о возможном мошенничестве, когда те же комбинации появляются во время снятия средств. Но для обнаружения мошенничества в режиме реального времени можно рассмотреть скользящее окно в один час при просмотре комбинаций карт. Вероятность встретить одних и тех же X человек у разных банкоматов в разное время в течение одного часа уменьшается по мере увеличения значения X.
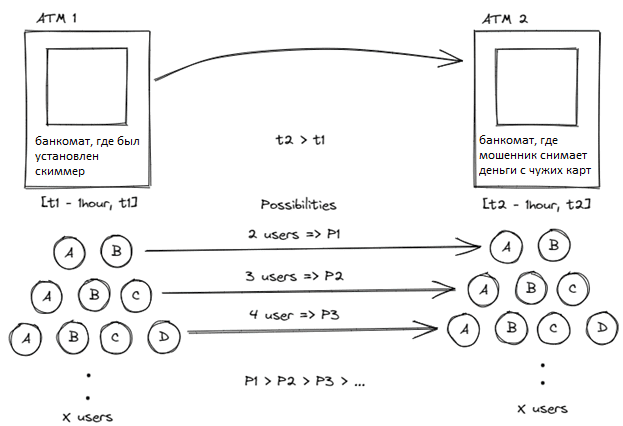
Нет необходимости искать комбинации карт более высокого порядка. Обнаружить мошенничество можно, даже если рассматривать всего три комбинации карт, т.к. на самом деле злоумышленник копирует гораздо больше, чем 3 карты подряд и затем пытается снят деньги с каждой. Таким образом, можно поймать мошенничество на 3-й карте после того, как преступник начнет снимать деньги.
Как реализовать эти идеи выявления мошеннических операций с помощью технологий Big Data, мы рассмотрим далее.
Антискимминг c Apache Kafka, Flink и HBase
Чтобы обнаружить скимминговое мошенничество в режиме реального времени, понадобятся соответствующие технологии потоковой передачи событий. В частности, можно использовать Apache Kafka в качестве источника потоковой передачи набора данных транзакций, Flink для обработки потоковых данных и HBase для хранения состояний в реальном времени. Потенциально, можно вместо HBase использовать собственный механизм хранения состояний Flink, о котором мы писали здесь и здесь. Но, поскольку количество троек карт, которые нужно хранить, будет довольно большим, HBase отлично подходит в качестве постоянного хранилища.
Напомним, Apache HBase является мощным NoSQL-хранилищем, которое позволяет работать с ключами-значениями быстро в режиме реального времени с помощью вычислительного движка Flink или Spark. Вместо с HBase приложение Flink будет просто обрабатывать потоки, не увеличивая потребление памяти.
Таким образом, упрощенный код Flink-приложения для обнаружения скимминговых мошенничеств с банковскими картами можно представить следующим образом:
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.co.RichCoFlatMapFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
import org.apache.flink.util.Collector
import org.apache.hadoop.conf.{Configuration => HadoopConf}
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, Get, Put}
import play.api.libs.json._
import scala.collection.JavaConverters._
import scala.util.{Failure, Success, Try}
// Getting transactions from each Atm.
case class AtmTransaction(
ATMID: Long,
CARD_NO: String,
TIMESTAMP: Long
)
// Getting each Atm information
case class Atm(
ATMID: Long,
LATITUDE: Double,
LONGITUDE: Double
)
// A triple card combination on an Atm.
case class AtmUsage(
ATMID: Long,
LATITUDE: Double,
LONGITUDE: Double,
CARDS: List[String]
)
// Two same card combinations are found for different Atms.
case class AtmAlert(
UUID: String,
TIMESTAMP: Long,
ATMID: Long,
PREV_USAGE: AtmUsage,
CURR_USAGE: AtmUsage
)
object AtmCardSkimmingDetection extends App {
// We create a Flink runtime environment.
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// Consume atm transactions from kafka. In scala, ??? indicates something will be implemented.
val atmTrxSource: DataStream[AtmTransaction] = ??? // env.fromSource(???)
// Consume atm information from kafka.
val atmSource: DataStream[Atm] = ??? // env.fromSource(...)
// Scala Json to case class transformations using play-json library.
implicit val readsAtmUsage: Reads[AtmUsage] = Json.reads[AtmUsage]
implicit val writesAtmUsage: Writes[AtmUsage] = Json.writes[AtmUsage]
// Hbase connection configurations.
val hbaseConf: HadoopConf = HBaseConfiguration.create
val connection: Connection = ConnectionFactory.createConnection(hbaseConf)
val hbaseTableName: String = ???
val tripleCardsTable = connection.getTable(TableName.valueOf(hbaseTableName))
class AtmTrxTripleFlatMap extends RichCoFlatMapFunction[AtmTransaction, Atm, AtmAlert] {
private var atmTrxList: ValueState[List[AtmTransaction]] = _
private var atm: ValueState[Atm] = _
private val modColFamily: Int = ??? // hbase colFamily identifier
override def open(parameters: Configuration): Unit = {
// initialize keyed states.
atmTrxList = getRuntimeContext.getState(new ValueStateDescriptor("atmTrxList", createTypeInformation[List[AtmTransaction]]))
atm = getRuntimeContext.getState(new ValueStateDescriptor("atm", createTypeInformation[Atm]))
}
// Checks whether new atm trx cardno is already in the buffer or not.
private def isCardExist(cardNo: String): Boolean = atmTrxList.value.exists(_.CARD_NO == cardNo)
// flatMap1 is being called for each keyed atm trx.
override def flatMap1(value: AtmTransaction, out: Collector[AtmAlert]): Unit = {
atmTrxList.value match {
case null => atmTrxList.update(List(value))
case _ =>
Try(atm.value.ATMID) match {
case Failure(_) =>
// we need to atm information to calculate distances. If 'atm' state is null yet, just skip.
println(s"Atm: ${value.ATMID} isn't available!")
case Success(_) =>
val _atm: Atm = atm.value
val hourAgo: Long = ??? // calculate 1 hour ago from latest trx.
if (value.TIMESTAMP >= hourAgo) {
if (isCardExist(value.CARD_NO)) { // value is already in buffer, just filter state and update buffer.
atmTrxList.update(atmTrxList.value.filter(_.TIMESTAMP >= hourAgo))
} else {
// new trx value is not in buffer yet.
// so, get binary card combinations from atmTrxList state and append new trx to each combination to get triple combinations.
val distinctTriples: List[(List[String], Get, Put)] = atmTrxList
.value
.filter(_.TIMESTAMP >= hourAgo)
.toSet
.subsets(2)
.map(l => l.+(value).toList.sortBy(_.CARD_NO)) //append new trx to each subset.
.map { triple =>
val rowId: Array[Byte] = triple.map(_.CARD_NO.takeRight(2)).mkString.getBytes // get last 2 characters of each cardNo
val colFam: Array[Byte] = (triple.map(_.CARD_NO.takeRight(2).toInt).sum % modColFamily).toString.getBytes // sum last 2 characters of each cardNo, take mod
val colName: Array[Byte] = triple.map(_.CARD_NO).mkString.getBytes // col name => card1card2card3
(
triple.map(l => l.CARD_NO), // card list
new Get(rowId).addColumn(colFam, colName),
new Put(rowId).addColumn(colFam, colName,
Json.toJson[AtmUsage](AtmUsage(value.ATMID, _atm.LATITUDE, _atm.LONGITUDE, triple.map(l => l.CARD_NO))).toString.getBytes
)
)
}
.toList
// Card triples are ready, query HBase for each triple.
Try(
tripleCardsTable.get(distinctTriples.map(_._2).asJava) // try to get triples from hbase
) match {
case Success(tripleCards) =>
tripleCards
.toList
.zip(distinctTriples.map(_._1)) // zip each triple result with their cardList.
.filter(!_._1.isEmpty) // filter empty result, if result is not empty, then triple has a previous usage.
.map(l => (
Json.fromJson[AtmUsage](Json.parse(l._1.value.map(_.toChar).mkString)).get, // parse HBase GET result to case class.
l._2 // cardList
))
.filter(l => l._1.ATMID != value.ATMID) // fraudster withdraws cards usually at a distant atm.
.map(l => AtmAlert(
java.util.UUID.randomUUID.toString, // alert UUID
System.currentTimeMillis, // alert timestamp
value.ATMID, // alert atmid
l._1, // previous card triple on atm 1
AtmUsage(value.ATMID, _atm.LATITUDE, _atm.LONGITUDE, l._2) // current card triple on atm 2
))
.foreach(l => out.collect(l))
case Failure(exception) => println(s"Can't reach to HBase while GET -> $exception")
}
// Put new card triple combinations to HBase.
Try(
tripleCardsTable.put(distinctTriples.map(_._3).asJava)
) match {
case Success(_) => // everything is fine, do nothing.
case Failure(exception) => println(s"Can't PUT triples to HBase -> $exception")
}
// add new atm trx to state
atmTrxList.update(atmTrxList.value.:+(value))
}
}
}
}
}
// flatMap2 is being called for each atm.
override def flatMap2(value: Atm, out: Collector[AtmAlert]): Unit = {
atm.update(value) // take atm information from control stream.
}
}
// Alert producer to kafka.
val producer: FlinkKafkaProducer[AtmAlert] = ???
/*
We have two different source => atmTrxSource and atmSource.
we need to do keyBy partitioning on ATMID to join each atm trx with the atm information.
*/
atmTrxSource.keyBy(_.ATMID)
.connect(atmSource.keyBy(_.ATMID))
.flatMap(new AtmTrxTripleFlatMap) // Then for each atm trx we apply extended RichCoFlatMapFunction.
.addSink(producer) // Publish alerts to kafka
// Start flink application
env.execute("flink-atm-skimming")
}
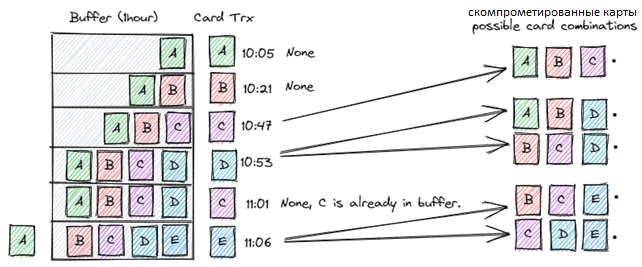
А принцип хранения банковских карт в HBase можно визуализировать так:

В заключение отметим, что потенциально вместо Apache Flink можно использовать другой популярный вычислительный движок – Spark. Хотя Spark, в отличие от Flink, работает не совсем в режиме реального времени, а использует микропакетную технологию Structured Streaming, он тоже позволяет реализовать изложенные идеи.
Читайте в нашей новой статье, можно ли повысить производительность Apache HBase, разместив несколько региональных серверов на одном узле кластера.
Больше подробностей про администрирование и эксплуатацию Apache HBase, Kafka, Flink и Spark, а также другие технологии потоковой обработки событий для распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop для инженеров данных
- Apache Kafka для инженеров данных
- Интеграция Hadoop и NoSQL
- Потоковая обработка в Apache Spark
[elementor-template id=»13619″]
Источники
- https://trends.rbc.ru/trends/industry/612d019d9a79470c54677745
- https://medium.com/@ahmetgurbuz1/fraud-detection-on-atm-card-skimming-a-case-study-a6462d9e48d4

