
Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Развивая наши курсы по Apache AirFlow для дата-инженеров и администраторов, сегодня рассмотрим, как автоматизировать обслуживание этого фреймворка, запуская поддерживающие операции как рабочие задачи по расписанию. В этой статье разбираем опыт дата-инженеров американской ИТ-компании Clairvoyant, предложивших сообществу 3 разных DAG по обслуживанию Apache AirFlow в виде open-source проектов, доступных для свободного...

Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....

В сферу ответственности дата-инженера входит не только проектирование быстрых и производительных конвейеров обработки данных, но обеспечение их надежности, в т.ч. с точки зрения информационной безопасности. Сегодня рассмотрим, как управлять чувствительной информацией (секретами) в Apache AirFlow, каких видов они бывают, где хранятся и что нужно сделать, чтобы не отображать их в...
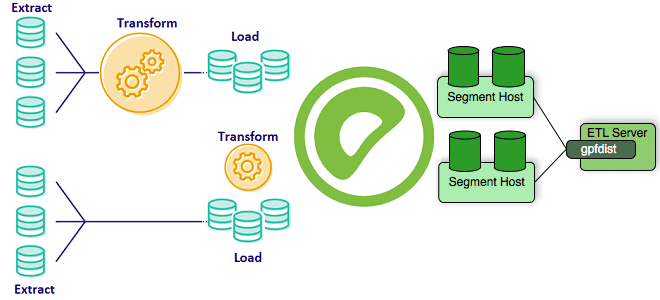
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...
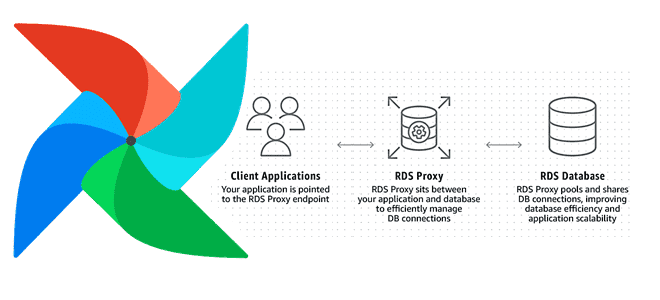
Увеличение пропускной способности и повышение скорости обработки данных на любой Big Data платформе при приемлемых затратах – одна из главных задач дата-инженера. Сегодня мы рассмотрим, как улучшить производительность множества экземпляров Apache AirFlow с помощью прокси-сервера Amazon RDS и сколько это стоит в денежном выражении: кейс компании Datafy. Больше не значит...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...

Apache AirFlow – это не только инструмент планирования batch-процессов, но и средство мониторинга ETL-задач и конвейеров обработки данных. Однако, наблюдать за выполнением data pipeline’а в веб-интерфейсе этого фреймворка не всегда удобно. Читайте далее, с какими проблемами AirFlow сталкиваются дата-инженеры и как альтернативный оркестратор Dagster позволяет решить их. Проблемы мониторинга data...

Продолжая сравнивать Apache AirFlow с Dagster, сегодня рассмотрим особенности развертывания и эксплуатации этих оркестраторов ETL-процессов и конвейеров обработки данных. Читайте далее о плюсах изоляции процессов, отделения системных служб от пользовательского кода, сложностях планирования и запуска задач, а также способах их решения с помощью современных инструментов дата-инженера. В изолятор: как развернуть...

Apache AirFlow – один из самых популярных инструментов современного дата-инженера для планирования и оркестрации batch-процессов. Повторить успех этого фреймворка стремятся многие компании и Big Data энтузиасты: недавно мы рассказывали про ViewFlow от DataCamp, а также писали про Luigi, Argo, MLFlow и KubeFlow. Сегодня рассмотрим Dagster – еще одну альтернативу Apache...