В этой статье поговорим про Viewflow: что такое, как устроено, чем полезно аналитикам данных и Data Scientist’ам. Встречайте новый фреймворк на базе Apache AirFlow от DataCamp – американского edu-стартапа в области ИИ, который упрощает создание и управление материализованными представлениями на SQL, R и Python в концепции low code, т.е. практически...

Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим некоторые особенности хранения данных в этой MPP-СУБД, а также разберем связанные с ними лучшие практики ее администрирования. Читайте далее про важность RAID-массивов, механизмы дублирования кластеров, утилиты резервного копирования и восстановления данных в Greenplum. RAID-массивы и зеркалирование жестких дисков...
Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и...
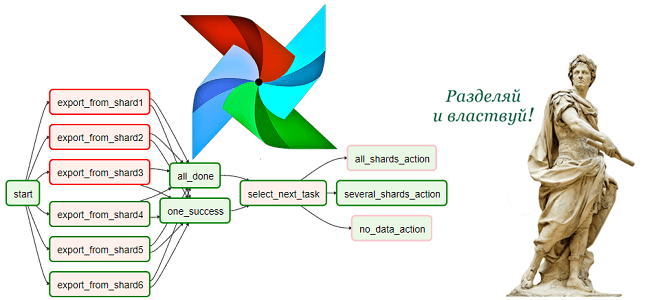
Чтобы сделать обучение дата-инженеров еще более полезным, сегодня мы рассмотрим проблему управления взаимозависимыми цепочками задач в Apache AirFlow. Читайте далее, как бразильская ИТ-компания QuintoAndar разработала промежуточный компонент Mediator на базе одноименного шаблона архитектурного проектирования ПО, чтобы облегчить взаимодействие между разными DAG’ами в конвейерах обработки больших данных. Проблема взаимозависимых DAG’ов в...

Практическое обучение дата-инженеров – это не просто курсы по основам Big Data, а полезные рекомендации с реальными примерами. Поэтому сегодня рассмотрим, как работать с DAG в Apache AirFlow еще эффективнее с помощью параметров конфигурации, плагинов, меток, шаблонов, переменных и еще 10 различных инструментов. 15 лучших практики для DAG в Apache...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

Чтобы добавить в наши обновленные авторские курсы для дата-инженеров по Apache AirFlow еще больше интересного, сегодня продолжим разбирать полезные дополнения релиза 2.0 и поговорим, почему разделение фреймворка на пакеты делает его еще удобнее. Также рассмотрим практический пример создания общедоступного провайдера из локального Python-пакета с собственными операторами, хуками и прочими компонентами....

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

В феврале 2021 года разработчики корпоративной версии Apache Kafka с коммерческой поддержкой, компания Confluent, выпустили премиум-коннектор к Oracle – одной из главных реляционных баз данных мира enterprise. Разбираемся, кому и зачем это нужно, а также как устроена такая интеграция SQL-СУБД и потоковой аналитики Big Data с применением CDC-подхода. Реляционный монолит...

В продолжение вчерашней статьи о победителях российского ИТ-конкурса «Проект Года» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», сегодня мы рассмотрим корпоративную платформу управления данными ПАО «Газпром нефть», реализованную на базе продуктов отечественного разработчика Big Data решений: Arenadata Hadoop и MPP-СУБД Arenadata DB (Greenplum). Зачем ПАО «Газпром нефть»...