 1194
1194 
Содержание
Apache AirFlow – это не только инструмент планирования batch-процессов, но и средство мониторинга ETL-задач и конвейеров обработки данных. Однако, наблюдать за выполнением data pipeline’а в веб-интерфейсе этого фреймворка не всегда удобно. Читайте далее, с какими проблемами AirFlow сталкиваются дата-инженеры и как альтернативный оркестратор Dagster позволяет решить их.
Проблемы мониторинга data pipeline’ов в Apache Airflow
В идеале оркестратор конвейеров обработки данных должен быть удобным пользовательским инструментом для мониторинга выполнения процессов, позволяя им быстро находить и самостоятельно отлаживать любые неполадки. Однако, пользователи Airflow отмечают, что GUI этого фреймворка имеет ряд ограничений, например, не показывает полную историю происхождения данных и скрывает вычисления внутри DAG (Directed Acyclic Graph). Это затрудняет отладку и мониторинг data pipeline’ов. Именно поэтому дата-инженеры компании Groupon решили кастомизировать веб-GUI этого фреймворка, внеся небольшие изменения в пару настроечных файлов, о чем мы рассказываем в отдельной статье.
Как мы уже отмечали здесь, в Apache Airflow цепочка DAG представляет собой набор задач, связанных через зависимости выполнения, без погружения в суть каждой задачи. При проектировании DAG-графа в Dagster помимо разработки Python-функций, определяющих вычисления и структуру графа, следует подробно объявить входы и выходы узла, требуемую конфигурацию и задать прочие настройки. Airflow, наоборот, практически не погружается в пользовательский код во время выполнения, что отражается на отсутствии поддержки в инструментах для отладки и наблюдения за вычислениями в задачах. Основная возможность, которую этот оркестратор предоставляет, — это лог-журнал необработанного текста, чтобы вручную искать какие-то данные по каждой задаче. На практике просмотр этих неструктурированных журналов в поисках нужной информации занимает у дата-инженера достаточно много времени.
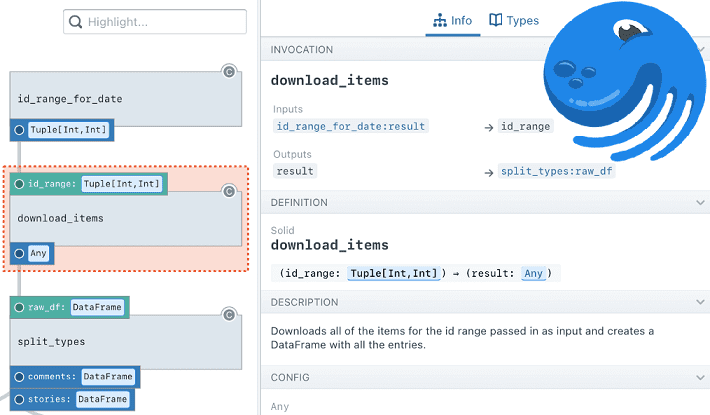
Более того, из-за отсутствия полной структурной истории с неизменными записями некоторые действия приходится повторять несколько раз. В частности, многие оперативные задачи затирают историю и для повторной попытки запуска в определенную дату нужно удалить предыдущий запуск, связанный с ней. AirFlow не сохраняет исторические структуры DAG, поэтому многократный прогон в режиме итеративной отладки невозможен. Альтернатива Apache AirFlow в виде фреймворка Dagster предлагает другой подход, который дает ряд преимуществ, что мы и рассмотрим далее.
Мониторинг исполнения DAG’ов в Dagster
В Dagster мониторинг и наблюдение за выполнением конвейеров обработки данных реализуется через структурированный журнал событий, который является историческим хранилищем неизменных записей вычислений в этом оркестраторе. Журнал управляет реактивными пользовательскими интерфейсами Dagit, формирует каталог ресурсов, поддерживает форматированные трассировки стека и рендеринг разметки непосредственно при просмотре запуска. Каждый выполненный data pipeline и любое созданное событие записываются в этот неизменяемый лог-журнал, позволяя ему служить системной записью для всей платформы данных. Это дает следующие преимущества:
- быстрая навигация — структурированный журнал событий позволяет быстро переходить к важным записям, например, к сообщениям об ошибках. Пользователи могут оперативно найти их с помощью нажатия пары клавиш и увидеть наглядно отформатированную трассировку стека.
- расширенные метаданные — пользователь может встраивать произвольные структурированные метаданные в журнал событий, чтобы отслеживать свойства с течением времени в т.ч. с помощью расширенных параметров отображения;
- реактивные пользовательские интерфейсы — события представляют собой неизменяемый поток журнала, UI которого можно обновлять онлайн;
- воспроизводимая история – можно повторно воспроизвести любой исторический прогон или структуру DAG, независимо от изменений в системе.
Data-driven подход: получайте нужные данные без погружения в конвейеры
Таким образом, в отличие от Airflow, который ничего не знает об активах, создаваемых DAG’ами, структурированный журнал Dagster включает информацию о потоке управления вычислениями — успехах, неудачах, повторных попытках и о результатах вычислений: какие ресурсы они производят и какие тесты качества данных проходят.
В Apache AirFlow добавление внешней системы для индексирования активов потребует интеграции и дополнительного кода. А в Dagster оркестратор осведомлен об информационных активах, что отражается в каталоге активов — принципиально новом представлении о работе оркестратора, который связывает ресурсы с вычислениями, которые их производят. Пользователи могут перемещаться в оркестратор, выполняя поиск созданных ресурсов, а не только конвейеров обработки данных, что их произвели. Это меняет парадигму дата-инженерии, отражая клиентский подход к данным, а не к конвейерам их создания и обработки, и дает следующие преимущества:
- навигация, ориентированная на активы – различные категории пользователей могут поименно индексировать в оркестраторе активы рабочих процессов, не погружаясь в детали конвейера для получения конечного результата. Имена и структуры data pipeline’ов становятся особенностями реализации, которые не нужны конечному потребителю.
- продолжительные и подробные просмотры — пользователи могут отслеживать и просматривать свойства, например, количество строк, время создания конкретного актива и прочие характеристики, включая их динамику их изменения;
- интегрированное происхождение активов — каталог активов поддерживает сведения об их происхождении, в т.ч. информацию о зависимостях данных и граф происхождения;
- активы как интерфейс между командами – взаимодействие через продукты данных, а не конвейеры их создания/обработки. Формальное моделирование датчиков и активов – это мощное средство объединения команд: в Dagster датчики/сенсоры создаются на основе активов, а не существуют отдельно от них, как в AirFlow.
Приме этом разработчики Dagster не стремятся заменить им все инструменты каталогизации данных, а рассматривают каталог ресурсов как средство вертикальной интеграции с оркестратором и источник достоверной информации о взаимосвязях между активами и вычислениями. Таким образом, Dagster расширяет и дополняет Apache AirFlow, предоставляя дата-инженеру и пользователям реализацию DataOps-идей. Как это реализуется на примере упрощения процессов тестирования и отладки Spark-приложений, читайте в нашей новой статье.
Наконец, Dagster может служить альтернативой или заменой Apache Airflow и других оркестраторов рабочих процессов, выполняя основную функцию планирования, упорядочивания и мониторинга вычислений. Но этот фреймворк выходит за рамки традиционного определения оркестратора, переосмысливая весь непрерывный процесс создания и запуска приложений данных. Таким образом, Dagster можно рассматривать как:
- многофункциональную среду для создания и тестирования приложений данных на Python;
- масштабируемую систему разработки, которая растет вместе с потребностями дата-инженера, от однопользовательской IDE до многопользовательской платформы данных корпоративного уровня;
- средство мониторинга исполнения data pipeline’ов с набором инструментов для разных категорий пользователей, поддержкой операции самообслуживания, быстрой отладки и отслеживание активов.
Благодаря этому Dagster становится очень перспективным фреймворком для дата-инженера и Data Science специалиста, предоставляя разным категориям пользователей нужные им функции, чтобы устранить недостатки Apache Airflow и расширить его возможности.
Больше подробностей про дата-инженерию и практическое использование Apache AirFlow для разработки сложных конвейеров аналитики больших данных с Hadoop и Spark вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/dagster-io/moving-past-airflow-why-dagster-is-the-next-generation-data-orchestrator-e5d297447189
- https://dagster.io/
- https://github.com/dagster-io/dagster

