 1033
1033 
Содержание
Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере.
API таблиц Ververica Cloud: создаем внешние источники и приемники данных
Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на базе Apache Flink. Этот полностью управляемый облачный сервис позволяет запускать приложения Apache Flink, в т.ч. на бесплатном тарифе. Чтобы познакомиться с возможностями этой платформы поближе, сегодня рассмотрим пример потоковой агрегации данных в одной из таблиц PostgreSQL. Поскольку источником данных является реляционная СУБД, логично из всех API фреймворка выбрать именно табличный, т.е. Flink SQL. Он позволяет подключиться к внешним системам для чтения и записи как пакетных, так и потоковых таблиц. Таблица-источник обеспечивает доступ к данным, которые хранятся во внешних системах (таких как база данных, хранилище значений ключей, очередь сообщений или файловая система). Таблица-приемник передает таблицу во внешнюю систему хранения. В зависимости от типа источника и приемника API таблиц фреймворка может работать с различными форматами: JSON, CSV, AVRO, Parquet, ORC и пр.
Реализовать такой ETL-конвейер можно с помощью Flink CDC, о чем я рассказываю в новой статье, или средствами коннекторов. Прежде всего, необходимо создать схему источника данных с помощью source-коннектора. В Ververica Cloud это делается в разделе Catalogs.
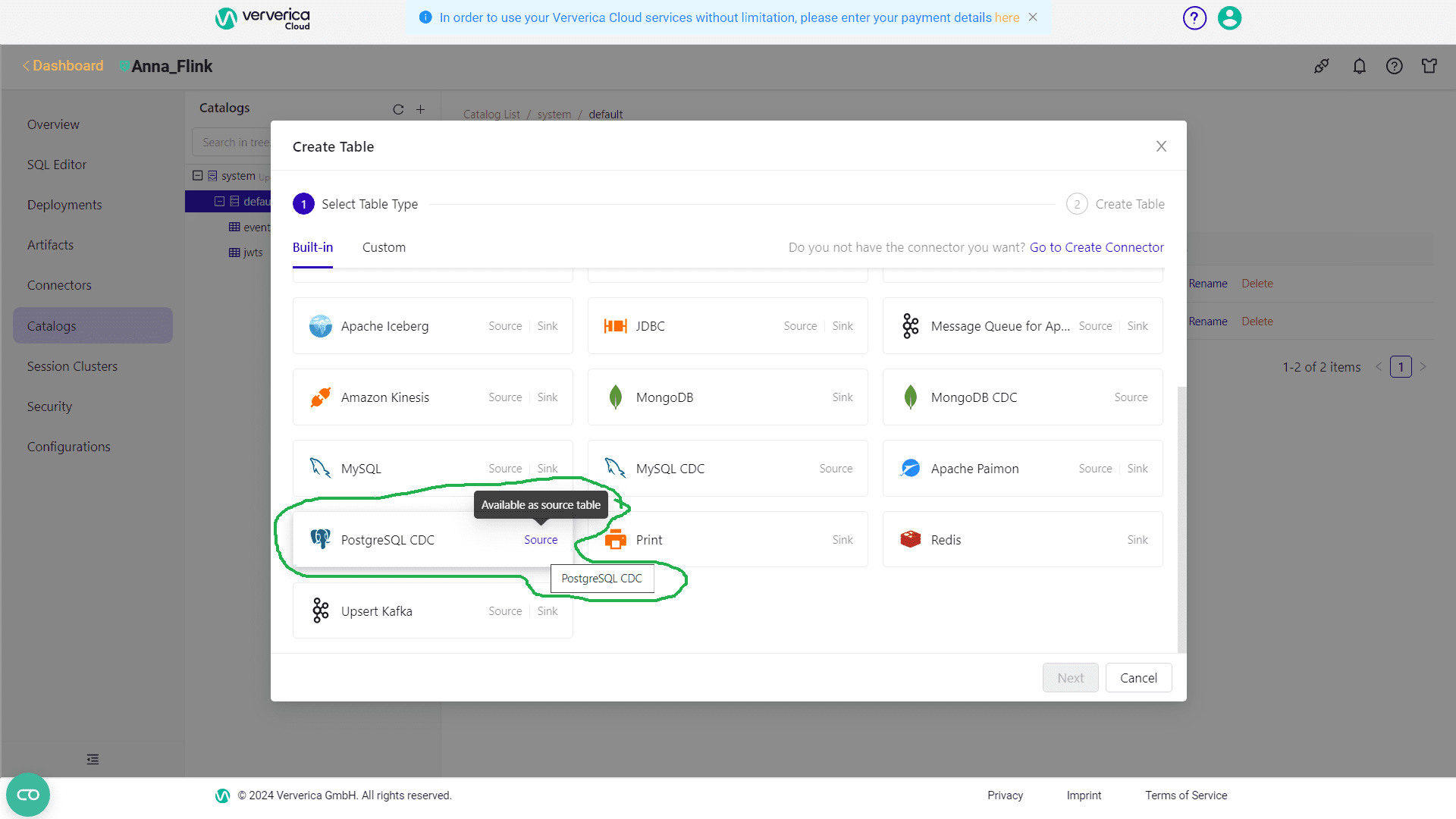
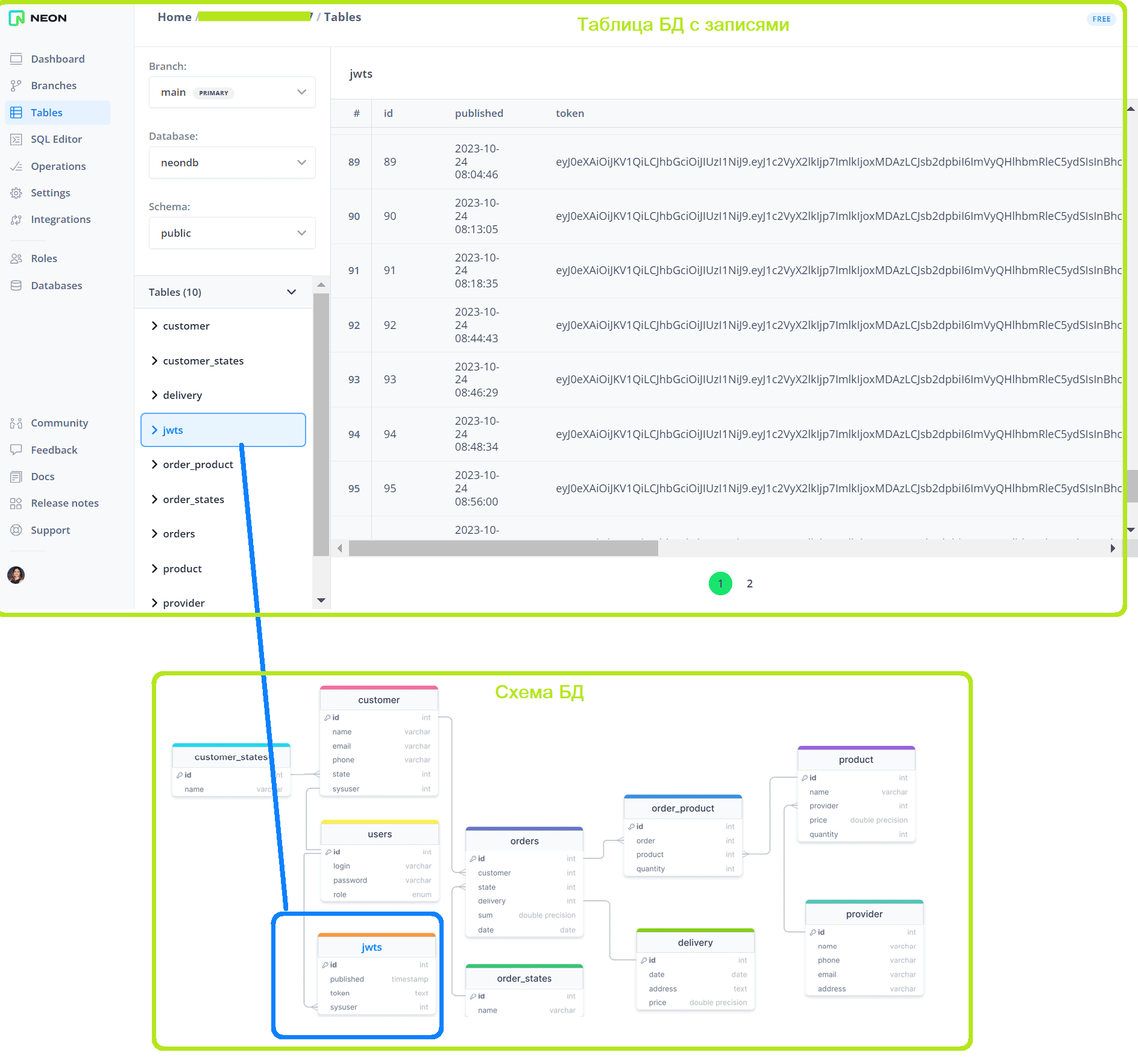
Затем следует задать схему таблицы и учетные данные подключения. Я буду работать с таблицей jwts, где сохраняются JWT-токены, генерируемые для авторизации менеджеров интернет-магазина. О проектировании и реализации этой системы я писала в блоге нашей Школы прикладного бизнес-анализа здесь и здесь. Токен имеет ограниченный срок действия, и записывается в cookie-файл заголовка HTTP-запроса, который клиент отправляет на сервер. Сам сохраняется в таблице jwts базы данных PostgreSQL, которая развернута в облачной платформе Neon.
Выполняем запросы Flink SQL
Запрос Flink SQL на создание таблицы-источника данных выглядит так:
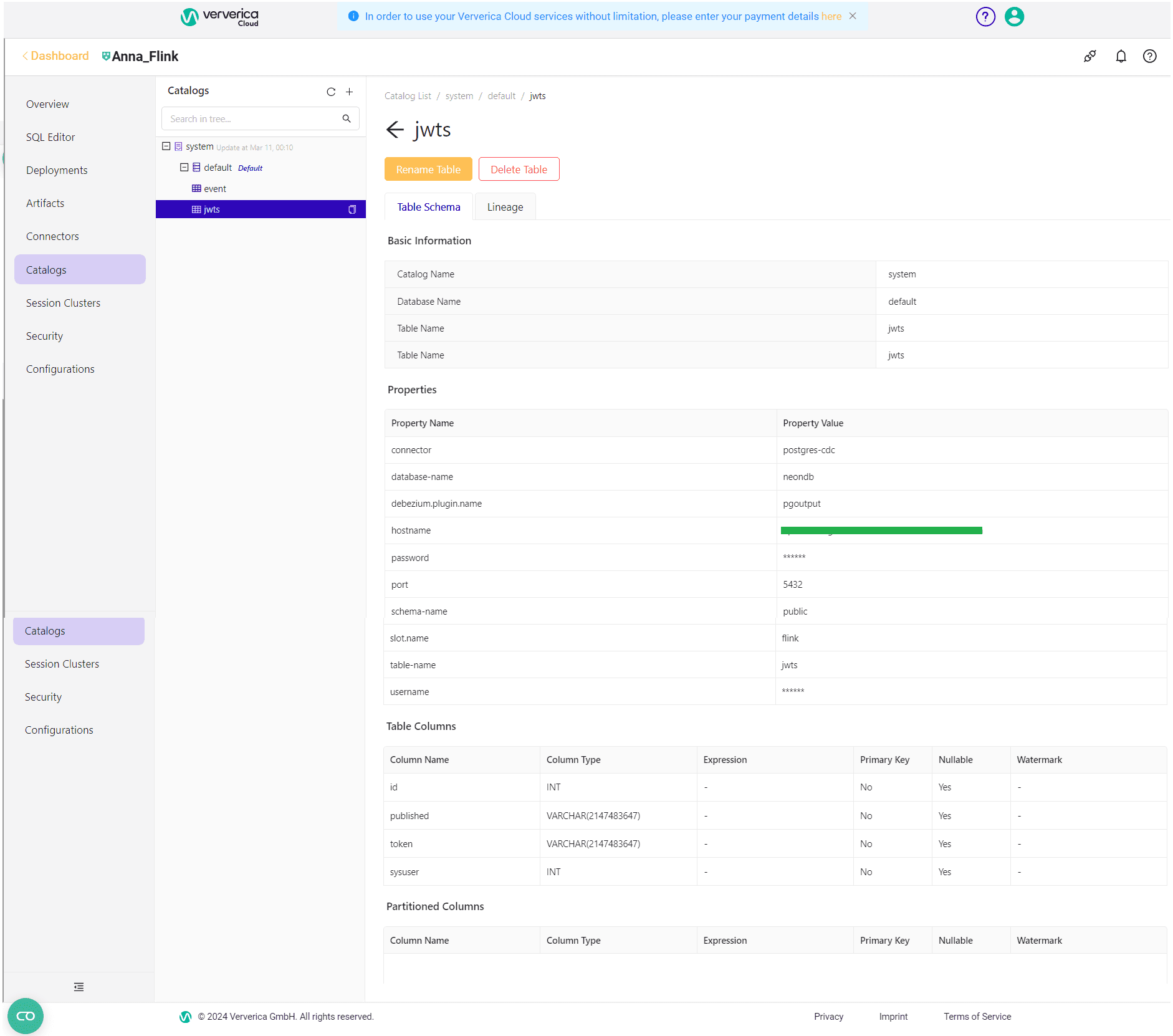
CREATE TABLE `system`.`default`.`jwts` ( `id` INT, `published` VARCHAR(2147483647), `token` VARCHAR(2147483647), `sysuser` INT ) COMMENT 'jwts' WITH ( 'connector' = 'postgres-cdc', 'database-name' = 'neondb', 'debezium.plugin.name' = 'pgoutput', 'hostname' = 'my-host', 'password' = 'my-pass', 'port' = '5432', 'schema-name' = 'public', 'slot.name' = 'flink', 'table-name' = 'jwts', 'username' = 'my-user' )
После его выполнения будет создана таблица источника данных.
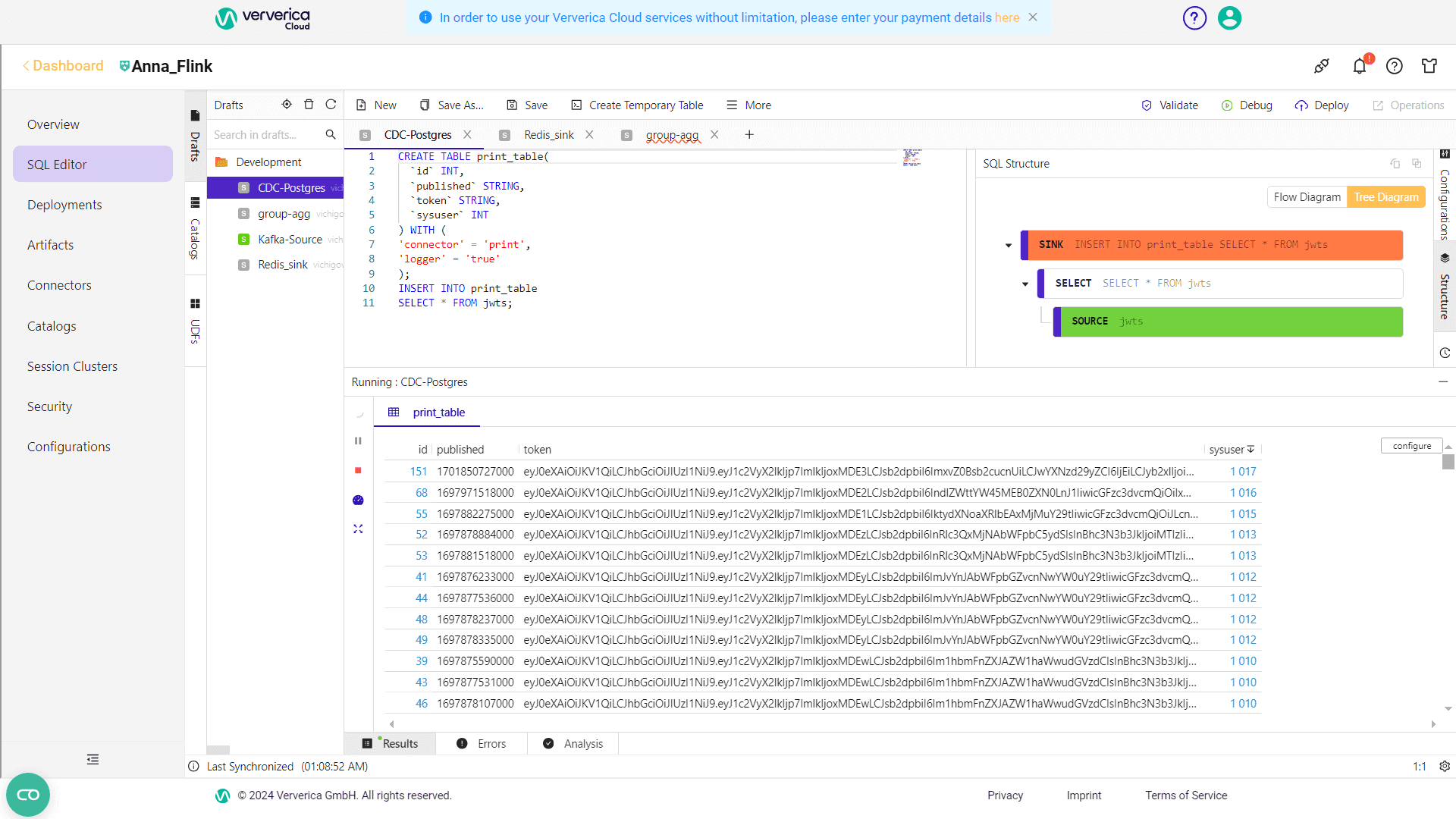
Чтобы посмотреть ее содержимое средствами Flink SQL, надо задать следующий запрос уже в разделе SQL Editor:
CREATE TABLE print_table( `id` INT, `published` STRING, `token` STRING, `sysuser` INT ) WITH ( 'connector' = 'print', 'logger' = 'true' ); INSERT INTO print_table SELECT * FROM jwts;
Для выполнения потоковых агрегаций над этой таблицей необходимо создать новый запрос. Чтобы вычислить, сколько раз каждый пользователь входил в систему необходимо сделать группировку по полю sysuser. Для этого запрос будет следующим:
CREATE TABLE print_table( `sysuser` INT, `q` BIGINT NOT NULL ) WITH ( 'connector' = 'print', 'logger' = 'true' ); INSERT INTO print_table SELECT sysuser, COUNT(*) FROM jwts GROUP BY sysuser;
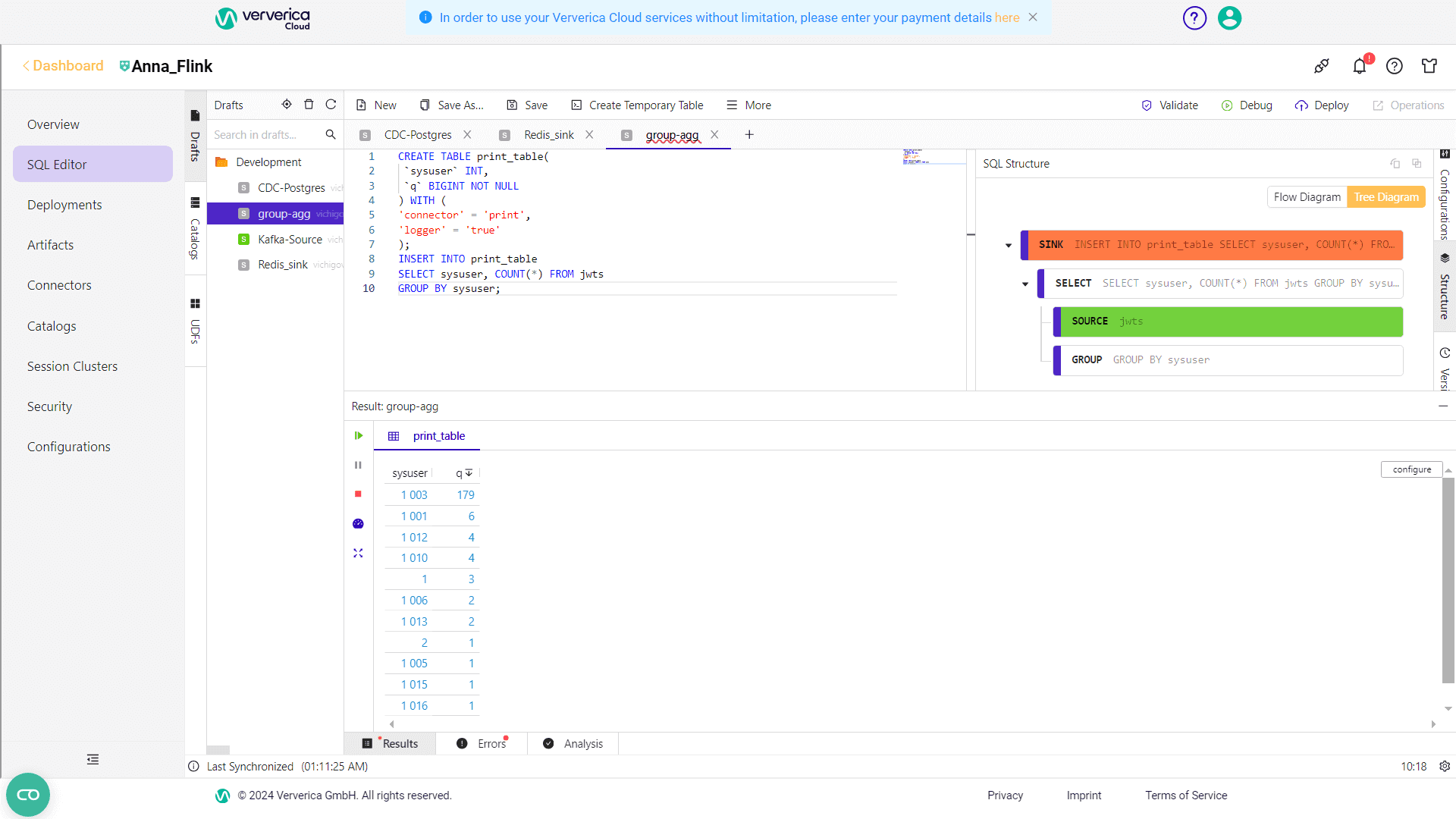
Таким образом, пользователь с id 1003 входил в систему чаще всего.
Чтобы поэкспериментировать с sink-коннектором, я решила записать в NoSQL-хранилище типа key-value Redis JWT-токены, выдаваемые пользователям. Ключом будет id пользователя, т.е. поле sysuser, а значением – сам токен. Поскольку Redis позволяет задать разные типы данных для значений, лучше всего для этого случая подходит хэш-массив, где к одному ключу можно записать разные поля. Хэши Redis — это типы записей, структурированные как коллекции пар поле-значение. Для этого создала следующий запрос Flink SQL:
CREATE TABLE redis_sink (
rkey INT,
rvalue STRING
) with (
'connector' = 'redis',
'mode' = 'hashmap',
'host' = 'my-host',
'port' = 'my-port',
'password' = 'my-password'
);
INSERT INTO redis_sink
SELECT sysuser, token
FROM jwts;
Результат выполнения запроса отображается в интерфейсе Flink SQL.
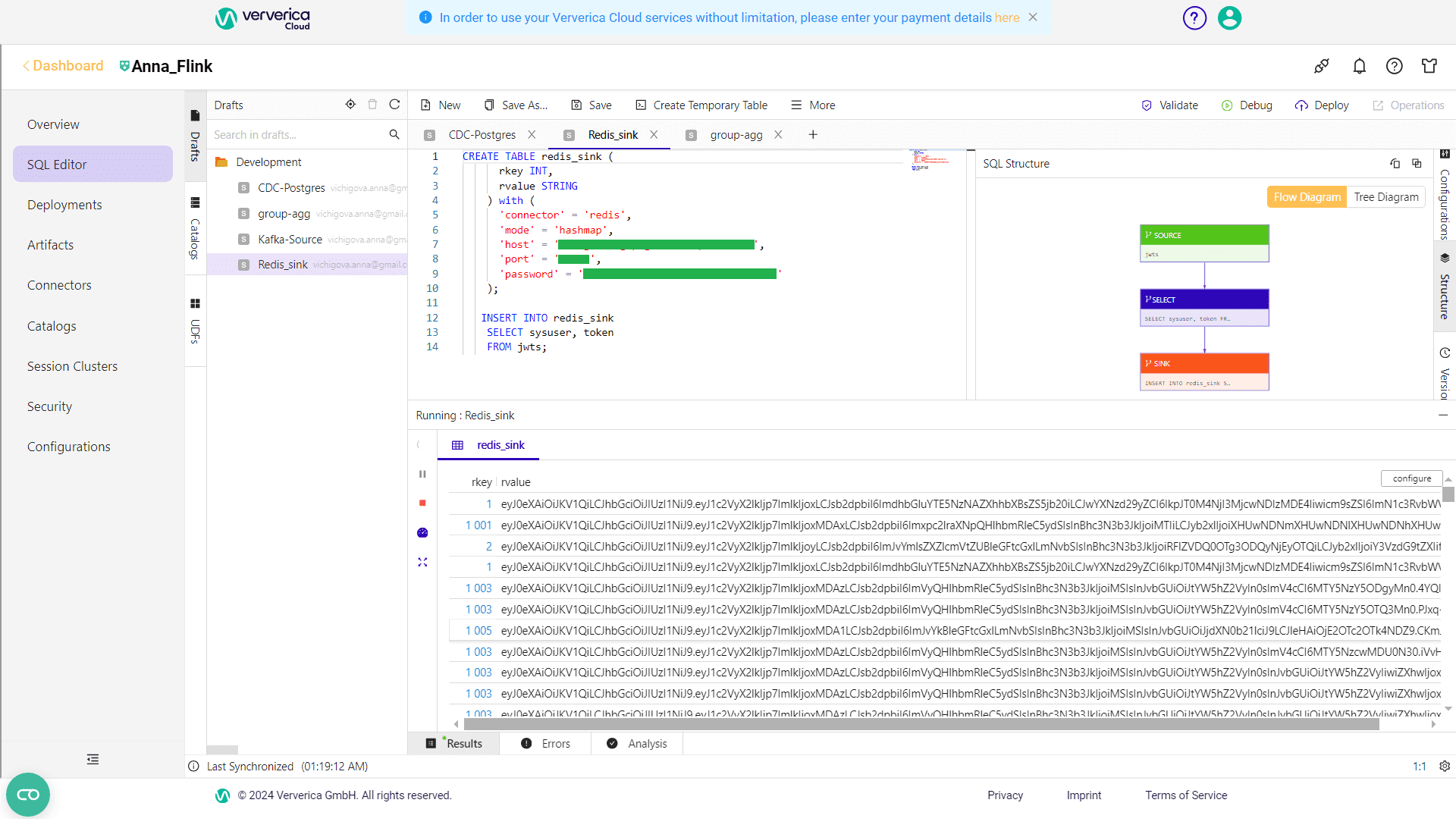
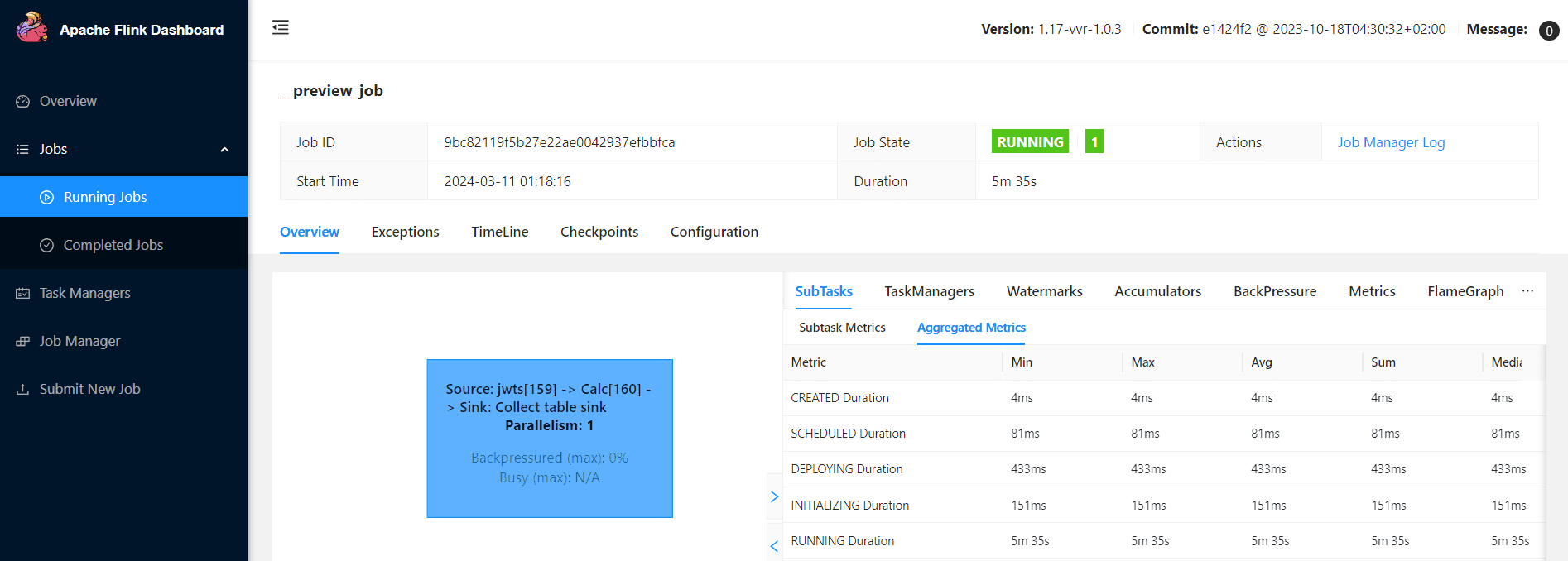
Однако, в самом хранилище этих данных не оказалось. Как это исправить, расскажу в следующий раз. В заключение отмечу, что выполнение каждой задачи и задания Flink со всеми системными метриками можно посмотреть в GUI фреймворка.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

