 663
663 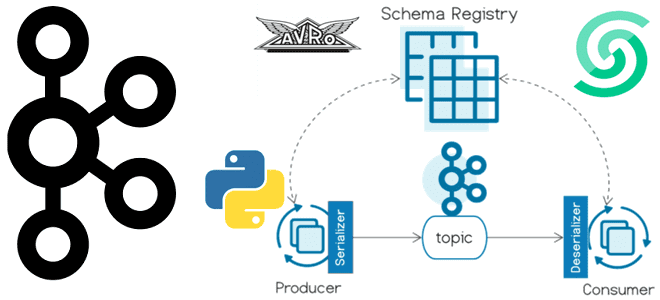
Содержание
Сегодня я покажу пример использования реестра схем для Apache Kafka на платформе Upstash, API которого полностью совместим со Schema Registry от Confluent. Пишем продюсер на Python, используя библиотеку confluent_kafka.
Еще раз о том, что такое реестр схем Kafka и чем он полезен
Реестр схем (Schema Registry) – это модуль Confluent для Apache Kafka, который позволяет централизовано управлять схемами данных полезной нагрузки сообщений в топиках. Приложения-продюсеры и потребители Kafka могут использовать эти схемы для обеспечения согласованности и совместимости данных по мере их эволюционного развития. Можно сказать, что реестр схем — это ключевой компонент управления данными в потоковой системе, помогающий обеспечить их качество, соблюдение стандартов и прозрачность происхождения с поддержкой аудита и совместной работы между разными командами. Определив схемы данных для полезной нагрузки и зарегистрировав ее в реестре, ее можно переиспользовать, частично освобождая приложение-потребитель от валидации структуры данных. Когда продюсер отправляет события в Kafka, схема данных включается в заголовок сообщения, а Schema Registry гарантирует валидность структуры данных для конкретного топика.
Таким образом, реестр схем позволяет продюсерам и потребителям взаимодействовать в рамках четко определенного контракта данных, контролируя эволюционное развитие схемы с помощью четких и явных правил совместимости. Также это оптимизирует полезную нагрузку по сети, передавая идентификатор схемы вместо всего определения схемы. Фактически реестр схемы состоит из REST-сервиса для проверки, хранения и получения схем в форматах AVRO, JSON Schema и Protobuf. Сериализаторы и десериализаторы этих 3-х форматов данных подключаются к клиентам Apache Kafka, т.е. приложениям-продюсерам и потребителям для хранения и извлечения схем полезной нагрузки.
Реестр схем на платформе Upstash, где развернут мой экземпляр Apache Kafka, полностью совместим с реестром схем Confluent. Поэтому его можно использовать с сериализаторами и десериализаторами io.confluent.kafka.serializers.KafkaAvroSerializer/Deserializer и io.confluent.connect.avro.AvroConverter, а также другими UI-инструментами, поддерживающими реестр схем Confluent.
Чтобы показать, как это работает, я написала небольшое Python-приложение, которое рассмотрим далее.
Практический пример на облачной платформе
Приложение-продюсер каждые 3 секунды публикует сообщения формата AVRO в топик Kafka под названием test, используя следующую схему для полезной нагрузки:
{
"type": "record",
"name": "application",
"namespace": "com.upstash",
"fields": [
{"name": "id", "type": "long"},
{"name": "event_time", "type": "string"},
{"name": "client", "type": "string"},
{"name": "email", "type": "string"}
]
}
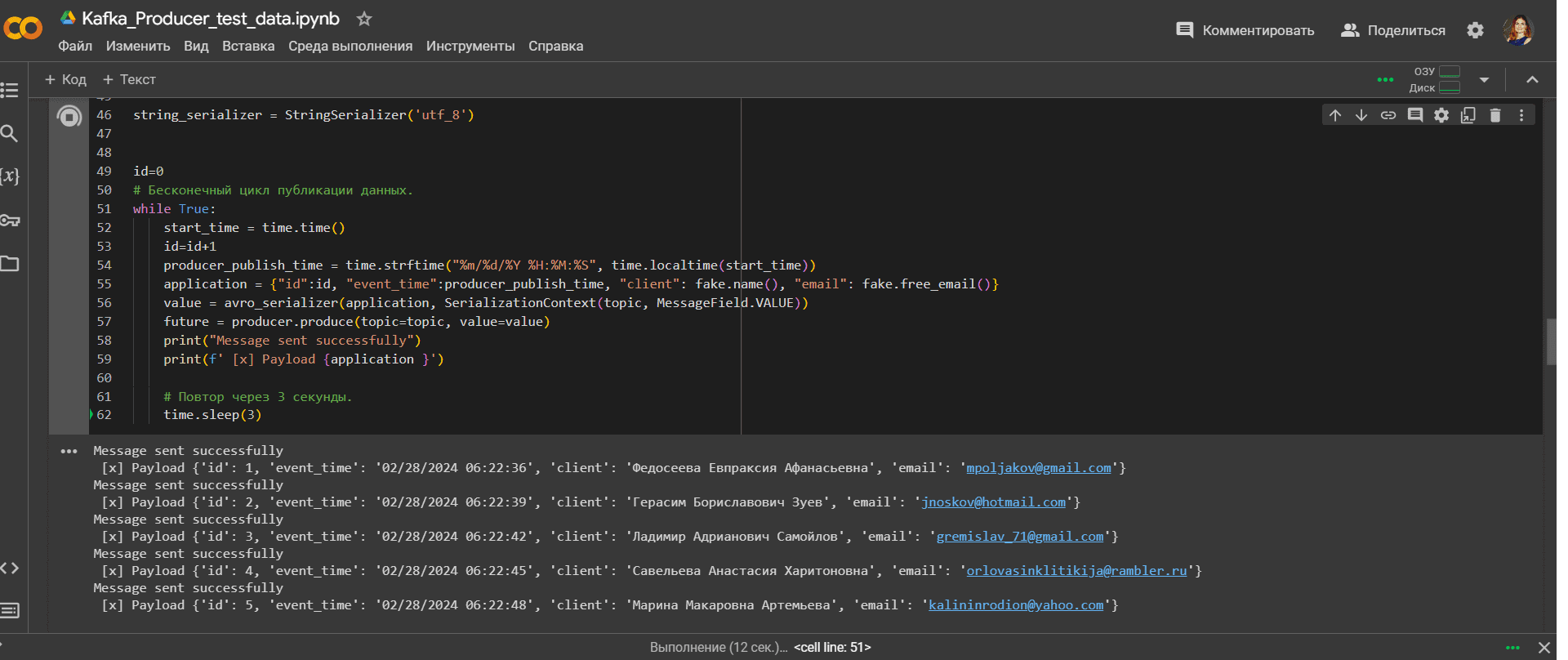
Код приложения, запускаемый в Google Colab, выглядит так:
#установка библиотек
!pip install confluent_kafka
!pip install kafka-schema-registry
!pip install faker
#импорт модулей
import random
from datetime import datetime
import time
from time import sleep
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroSerializer
# Импорт модуля faker
from faker import Faker
# Определение схемы данных
schema = """{
"type": "record",
"name": "application",
"namespace": "com.upstash",
"fields": [
{"name": "id", "type": "long"},
{"name": "event_time", "type": "string"},
{"name": "client", "type": "string"},
{"name": "email", "type": "string"}
]
}
"""
topic='test'
fake=Faker('ru_RU')
#Создание продюсера
producer = Producer({
'bootstrap.servers': kafka_url,
'sasl.mechanism': 'SCRAM-SHA-256',
'security.protocol': 'SASL_SSL',
'sasl.username': username,
'sasl.password': password,
})
schema_registry_client = SchemaRegistryClient({
'url': schemaregistry_url,
'basic.auth.user.info': auths
})
avro_serializer = AvroSerializer(schema_registry_client, schema)
string_serializer = StringSerializer('utf_8')
id=0
# Бесконечный цикл публикации данных.
while True:
start_time = time.time()
id=id+1
producer_publish_time = time.strftime("%m/%d/%Y %H:%M:%S", time.localtime(start_time))
application = {"id":id, "event_time":producer_publish_time, "client": fake.name(), "email": fake.free_email()}
value = avro_serializer(application, SerializationContext(topic, MessageField.VALUE))
future = producer.produce(topic=topic, value=value)
print("Message sent successfully")
print(f' [x] Payload {application }')
# Повтор через 3 секунды.
time.sleep(3)
Запуск этого кода начинает публикацию сообщений в топик Kafka.
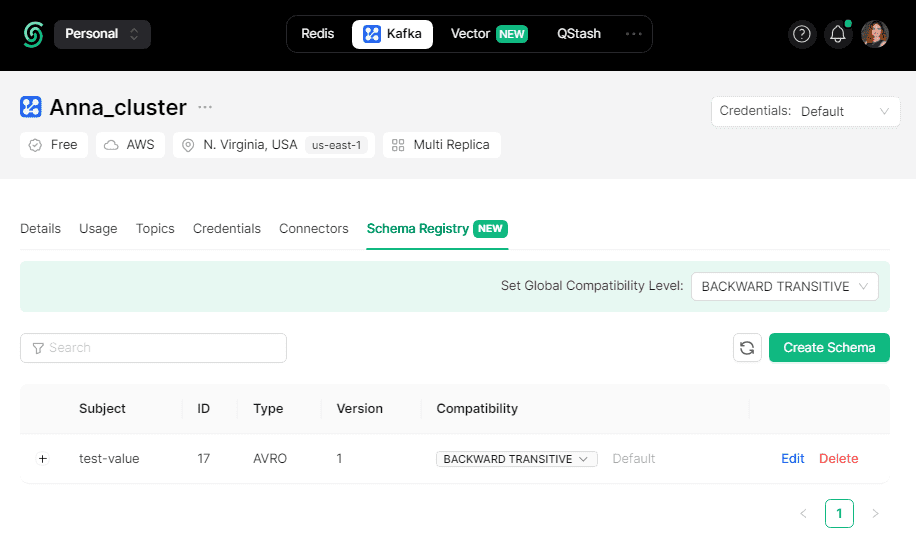
При этом на платформе Upstash создается заданная в коде схема полезной нагрузки сообщения под именем test-value. Это значит, что схема задана для поля значение, т.е. value, полезная нагрузка сообщения, в топике Kafka под названием test.
Справедливости ради стоит отметить, что схема данных будет создана и зарегистрирована в реестре только при отсутствии ошибок, которые чаще всего связаны с использованием не поддерживаемого типа данных. Например, когда я задала integer для поля id вместо long, вышло сообщение об ошибке, т.к. в формате AVRO нет типа данных integer, в отличие от JSON.
Просмотреть созданную схему данных можно также в GUI платформы Upstash.
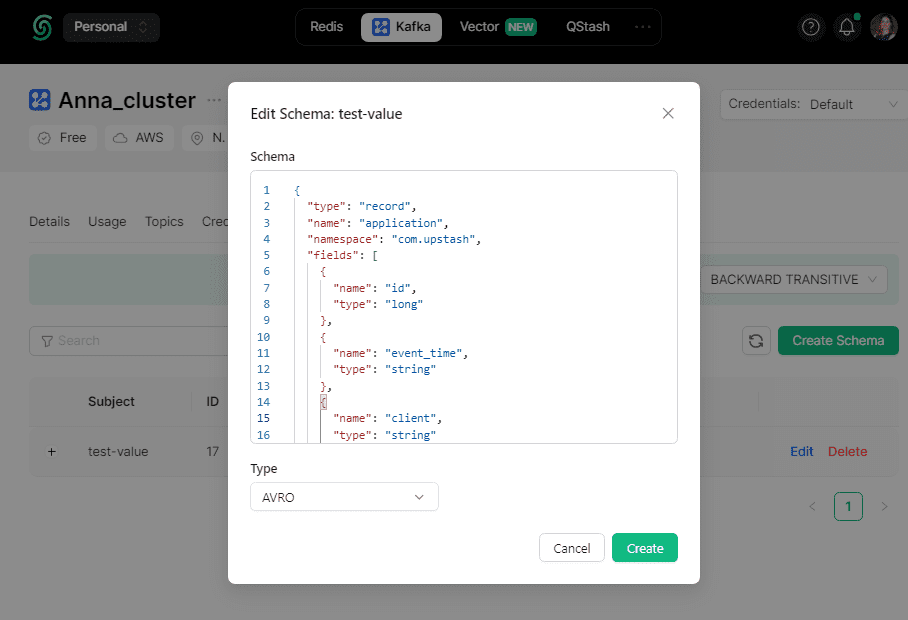
При использовании реестра схемы в Upstash можно выбрать одно из следующих правил совместимости:
- BACKWARD – потребители, использующие новую схему, могут читать данные, опубликованные продюсерами с использованием последней версии схемы, зарегистрированной в реестре;
- BACKWARD_TRANSITIVE – правило совместимости по умолчанию, когда потребители, использующие новую схему, могут читать данные, опубликованные продюсерами с использованием всех ранее зарегистрированных в реестре схем;
- FORWARD – потребители, использующие последнюю зарегистрированную схему, могут читать данные, опубликованные продюсерами, использующими новую версию схемы;
- FORWARD_TRANSITIVE – потребители, использующие все ранее зарегистрированные схемы, могут читать данные, опубликованные продюсерами с использованием новой схемы;
- FULL — новая версия схемы полностью совместима с последней зарегистрированной схемой;
- FULL_TRANSITIVE — новая версия схемы полностью совместима со всеми ранее зарегистрированными схемами;
- NONE — проверки совместимости схемы отключены.
При выборе TRANSITIVE-правил (BACKWARD_TRANSITIVE или FORWARD_TRANSITIVE) схема будет сравниваться со всеми предыдущими версиями, а не только с последней.
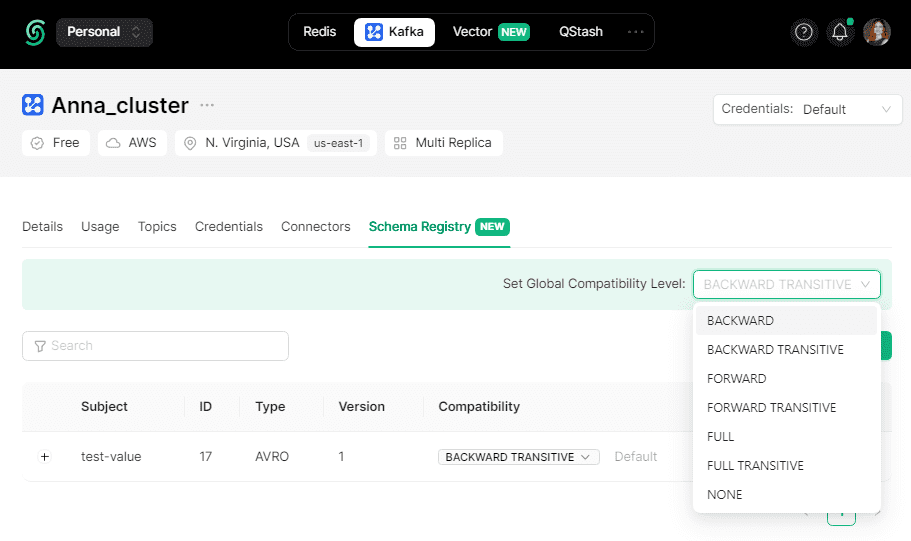
Я оставила правило BACKWARD_TRANSITIVE по умолчанию. Разумеется, можно просмотреть сообщения, опубликованные в топике Kafka:
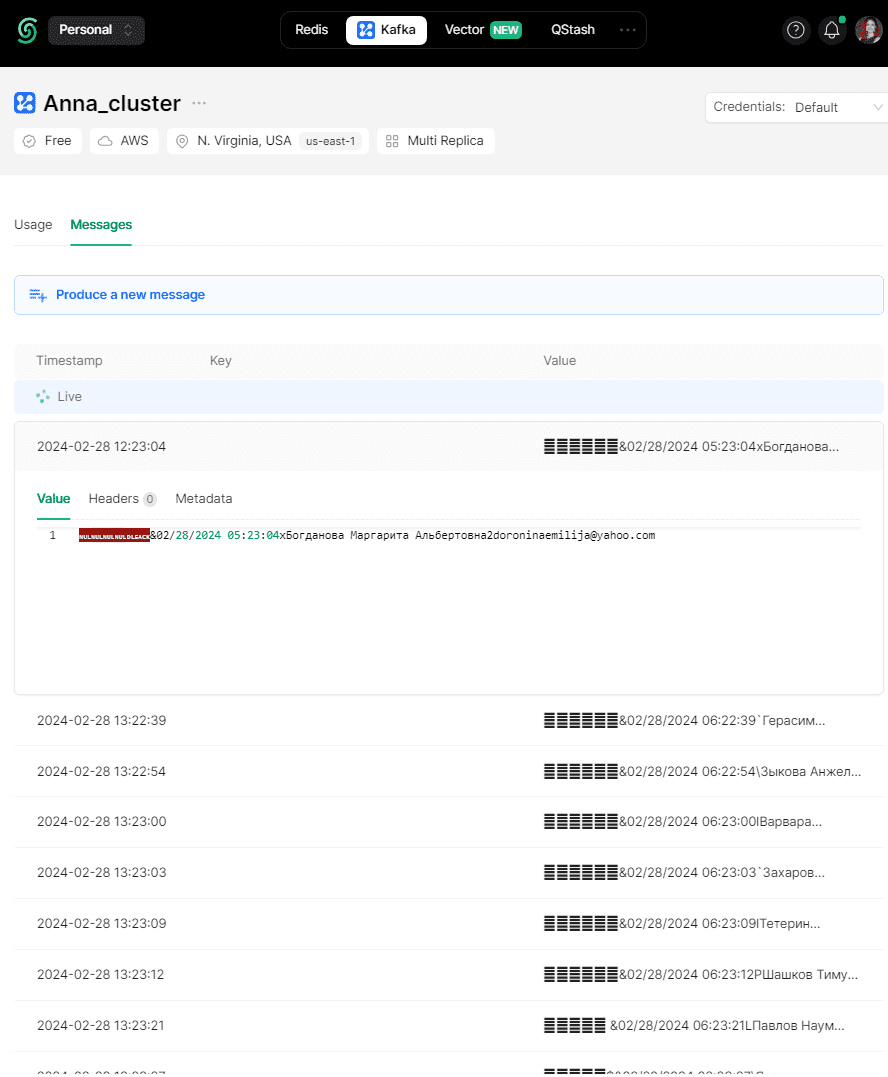
В следующей статье покажу, как использовать реестр схем при потреблении сообщений, написав приложение, которое будет считывать данные из этого топика Kafka, используя зарегистрированную схему.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

