
24 октября 2023 года вышел очередной релиз Apache Flink. Знакомимся с главными новинками популярного Big Data фреймворка для разработки потоковых stateful-приложений: JDBC-драйвер для SQL-шлюза, хранимые процедуры для коннекторов, расширенная поддержка SQL, динамическое масштабирование с REST API и RocksDB, улучшение пакетных операций, а также другие полезные фичи Apache Flink 1.18. Улучшения...
О важности шифрования чувствительных данных, публикуемых в Apache Kafka, мы недавно писали здесь и здесь. В продолжение этой темы сегодня познакомимся с Kryptonite – open-source библиотекой для сквозного шифрования на уровне полей для Apache Kafka Connect. Шифрование данных вне брокеров Apache Kafka: зачем это нужно Apache Kafka поддерживает несколько функций...
Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...

Продолжая недавний разговор про настройку конвейеров из Flink-приложений, сегодня рассмотрим, почему важна локальность данных, как избежать узких мест в приемниках потоковых данных и чем хорош HybridSource для объединения гетерогенных источников. Обеспечьте локальность данных Хотя распределенные системы обладают большим потенциалом по сравнению с локальными, позволяя обрабатывать больше данных, вычисления не происходят...

10 октября 2023 года вышел очередной релиз самой популярной распределенной платформы потоковой передачи событий. Знакомимся с главными новинками Apache Kafka 3.6.0: промышленная поддержка KRaft вместо ZooKeeper, оптимизация транзакций, повышение производительности памяти и другие фичи свежего релиза для разработчика, дата-инженера и администратора. ТОП-10 новинок выпуска 3.6 Apache Kafka 3.6.0 включает 6...
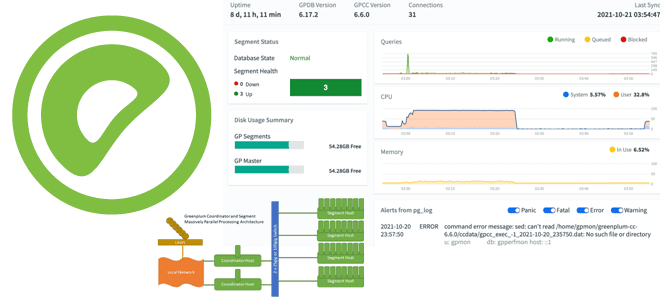
Что такое VMware Greenplum Command Center, как использовать этот инструмент для эффективного управления MPP-СУБД и чем он отличается от Arenadata Command Center для Arenadata DB. Что такое центр управления Greenplum от VMware VMware Greenplum Command Center — это инструмент управления, который отслеживает показатели производительности системы, анализирует состояние кластера и позволяет...
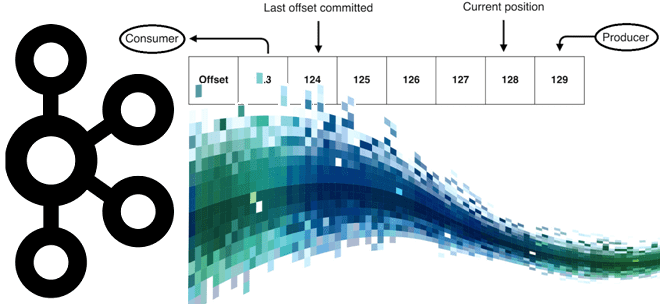
Чем политика сброса смещения earliest отличается от latest в конфигурации auto.offset.reset, зачем устанавливать свойству enable.auto.commit значение false и чем потребитель Java отличается от клиентов на основе librdkafka (C/C++, Python, Go и C#). Конфигурации Apache Kafka для управления смещением Потребитель Apache Kafka — это клиентское приложение, которое подписывается на весь топик...
Для чего разработчику Flink-приложения инструменты профилирования, и почему надо избегать сериализации Kryo и динамической загрузки классов. Используйте инструменты профилирования Разработка и отладка высоконагруженных приложений требует специальных средств, позволяющих понять причины их медленной работы и повысить производительность. Такой анализ работы приложение называется профилированием и выполняется с помощью специальных средств – инструментов...

Продолжая тему недавней статьи про настройки Greenplum 7, сегодня рассмотрим еще несколько конфигураций, которые позволят сделать эту MPP-СУБД еще быстрее и надежнее. Глобальные конфигурации Greenplum для настройки рабочих файлов Параметры глобальной конфигурации пользователя (GUC, Global User Configuration) Greenplum могут быть как глобальными, так и локальными по отношению к экземплярам сегмента. Глобальные...
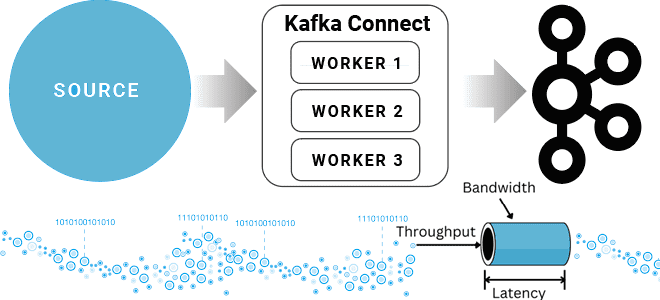
Компоненты платформы Kafka Connect и их настройки для повышения скорости и объема данных, считываемых из внешних источников и публикуемых в топике Kafka. Разбираем на примере JDBC-коннектора для реляционной базы данных. Проблемы и возможности коннекторов Kafka Connect Kafka Connect — это инструмент интеграции данных с открытым исходным кодом, который упрощает процесс...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...
Зачем настраивать конфигурацию конвейера Flink-приложений в зависимости от рабочей нагрузки и как это сделать: примеры и рекомендации. 3 вида рабочей нагрузки в потоковых конвейерах Конвейер потоковой передачи событий может реализовывать различные сценарии: обратная засыпка (backfilling), когда конвейер потребляет все исторические данные, считывая все сообщения, доступные во входных источниках, пока не...

Что настроить в Greenplum 7, чтобы сделать эту MPP-СУБД еще эффективнее. Обзор наиболее популярных параметров конфигурации и рекомендации по установке их значений. Ограничения подключений и выполнения SQL-запросов: 6 параметров с перезагрузкой системы Будучи зрелой системой со множеством настроек, Greenplum предоставляет администратору и дата-инженеру широкие возможности по адаптации этой СУБД к...

С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog. Что такое Apache Datasketches и зачем это нужно В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения...
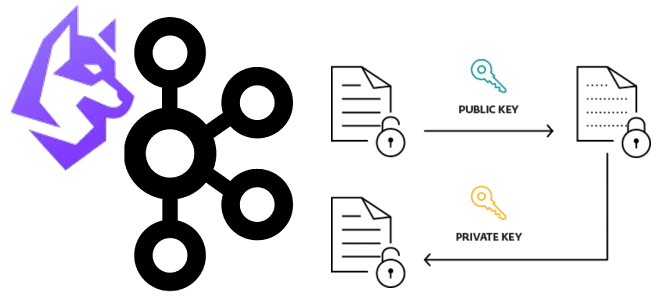
Недавно мы рассматривали пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровку на потребителе Apache Kafka. Такой примитивный способ подходит для интеграции нескольких приложений, но в больших масштабах становится очень неудобным. Читайте, как Conduktor Gateway для Apache Kafka поможет выйти из этой ситуации, обеспечив защиту конфиденциальных...

Как использовать Greenplum в проектах машинного обучения: знакомимся с расширением PostgresML и модулем pgvector. Возможности и ограничения плагинов, превращающих MPP-СУБД в полноценный MLOps-инструмент. Как превратить Greenplum в векторную базу данных с расширением pgvector Будучи вариацией PostgreSQL с механизмами массово-параллельной загрузки, Greenplum отлично справляется с огромным объемом данных. Однако, к хранилищам...
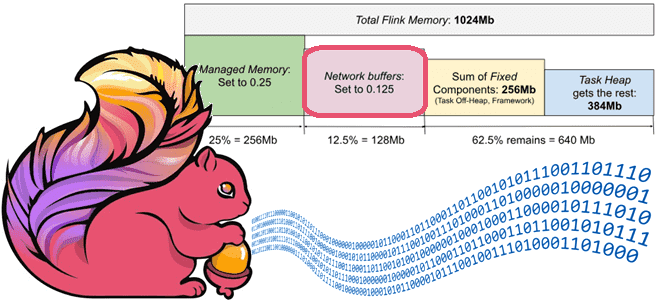
Как Apache Flink обеспечивает стабильно высокую пропускную способность потоковой обработки данных с помощью сетевых буферов и контрольных точек, каковы возможности и ограничения этих механизмов и какие конфигурации надо настроить для их эффективного использования. Зачем Apache Flink нужны сетевые буферы Каждая запись в Flink отправляется следующей подзадаче вместе с другими записями...
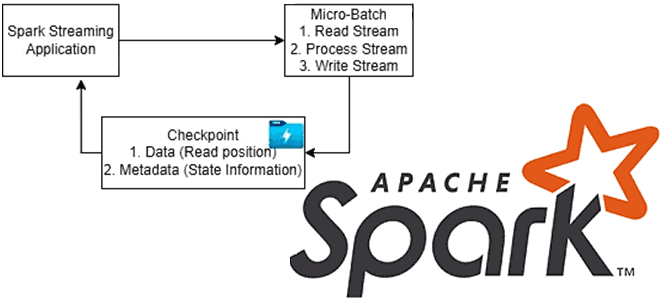
Чтобы обеспечить отказоустойчивость потоковых приложений, Apache Spark использует механизм контрольных точек. Какие они бывают, когда их включать и как настроить для эффективной работы. Что такое checkpoint в Apache Spark и зачем он нужен Чтобы приложение потоковой передачи было устойчиво к сбоям по внешним причинам, например, отказ JVM, Spark Streaming сохраняет...
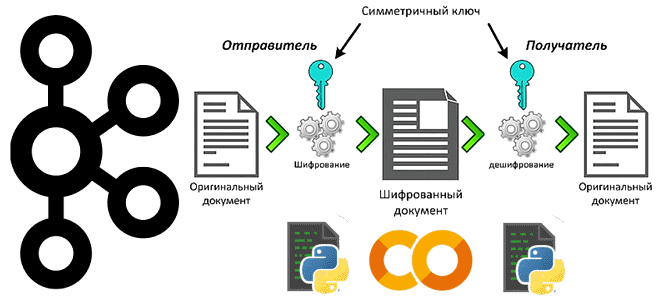
Простой пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровка на потребителе Apache Kafka: пишем и запускаем Python-код в Google Colab. Публикация данных в Kafka: шифрование на стороне продюсера Apache Kafka часто используется для обмена данными между несколькими системами внутри предприятия. Однако, даже при работе во...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...