 1116
1116 
Содержание
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven.
Постановка задачи и проектирование конвейера
Как обычно, в качестве практического примера возьму интернет-магазин, о проектировании и реализации которого я писала в блоге нашей Школы прикладного бизнес-анализа здесь и здесь. Аутентификация выполняется путем генерации JWT-токена при входе зарегистрированного пользователя с ролью менеджер в систему. Этот токен с ограниченным сроком действия записывается в cookie-файл заголовка HTTP-запроса, который клиент отправляет на сервер. Сам сохраняется в таблице jwts базы данных PostgreSQL, которая развернута в облачной платформе Neon.
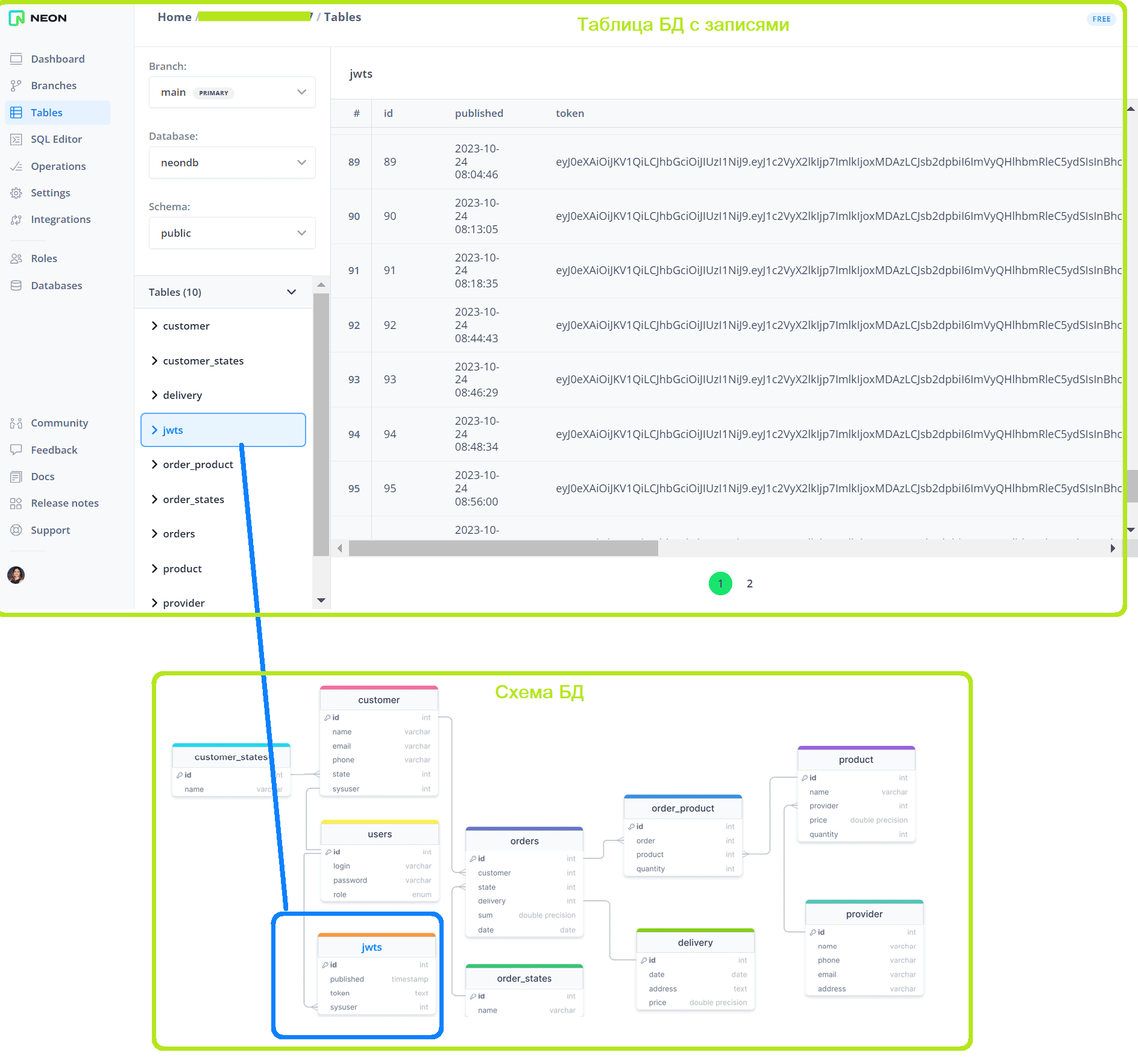
Добавление записи в таблицу jwts свидетельствует о входе нового пользователя. Чтобы анализировать события входа в систему в реальном времени, организуем передачу данных в индекс Elasticsearch, откуда они будут визуализироваться в дэшбордах Kibana. Целиком этот ETL-процесс выглядит так.

Напомню, Elasticsearch – это документо-ориентированная NoSQL-СУБД, которая имеет мощный поисковой движок и почти мгновенную индексацию JSON-документов. Kibana – это интерфейс визуализации данных, проиндексированных в Elasticsearch. Kibana позволяет строить наглядные и интерактивные дэшборды.
Реализацию представленного конвейера можно разделить на несколько задач:
- подготовка захвата событий изменения данных из таблицы PostgreSQL, т.е. включение механизма логической репликации на основе журнала упреждающей записи (WAL, Write Ahead Log), создание публикации и слота репликации, что я показывала в прошлой статье;
- создание source-коннектора, который подписывается на созданную публикацию и сам публикует потребленные данные в топик Kafka, что также было рассмотрено здесь;
- создание sink-коннектора, который потребляет данные из топика Kafka и публикует их в Elasticsearch;
- разработка визуализаций и создание дэшборда в Kibana.
Первые 2 задачи подробно рассмотрены в этой статье, а сейчас я покажу, как выполнить оставшиеся. Как обычно, в качестве рабочей среды использую платформу Upstash, где развернут мой экземпляр Apache Kafka.
Создание sink-коннектора Apache Kafka
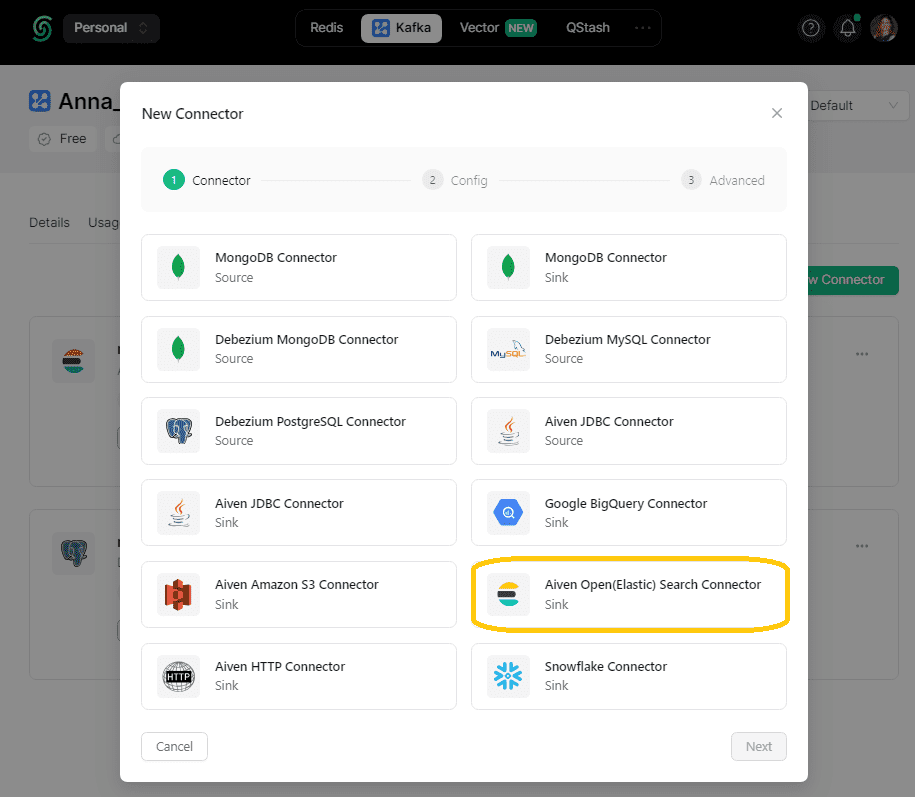
На платформе Upstash создание коннектора сводится к выбору из существующих вариантов. Для загрузки данных в Elasticsearch выбираем sink-коннектор от Aiven.
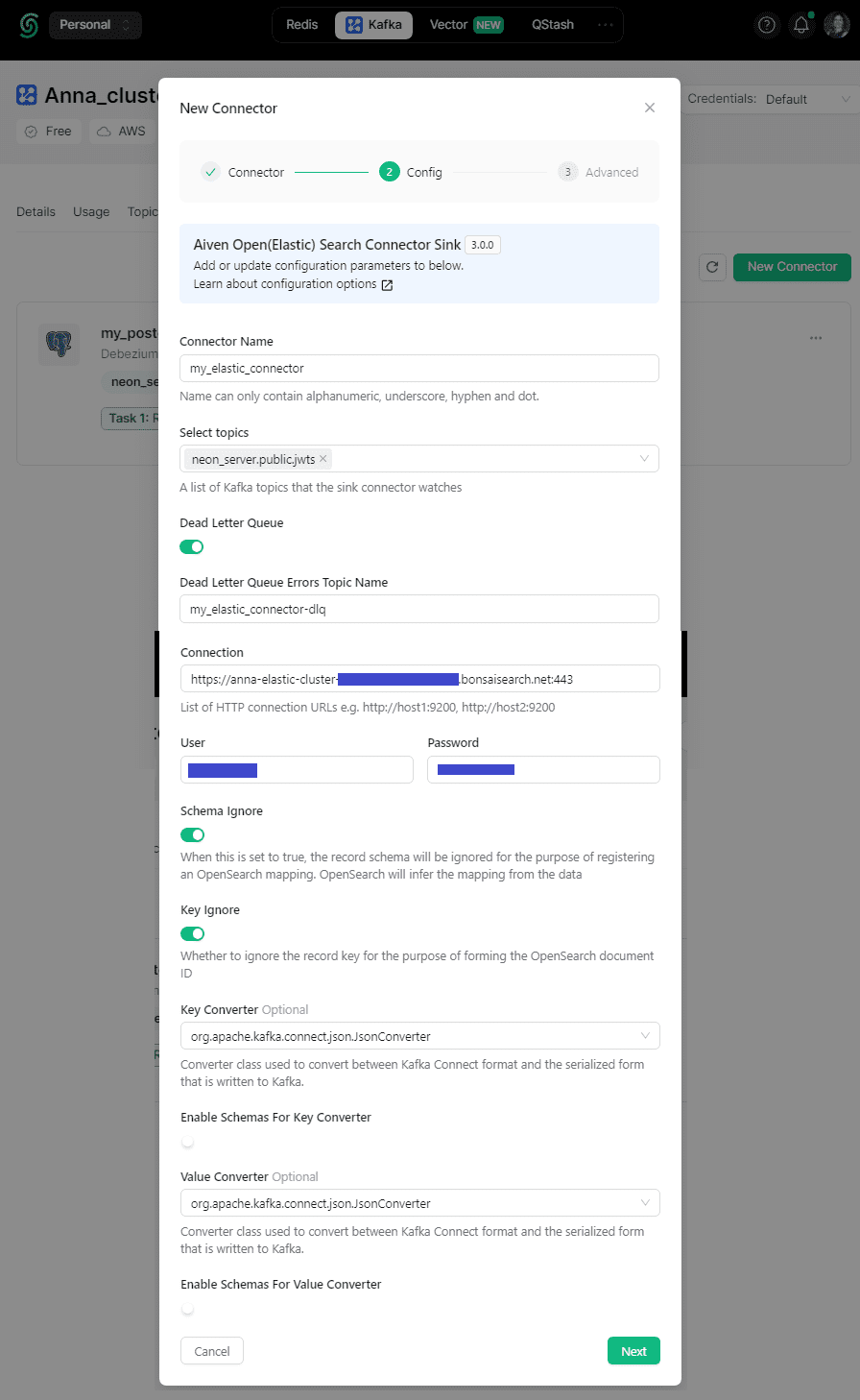
Затем нужно его настроить, задав учетные данные подключения к внешнему NoSQL-хранилищу. В этот раз я отключила встраивание схемы в JSON-документ, чтобы сделать его лаконичнее.
После успешного создания коннектора он отобразится в общем списке.
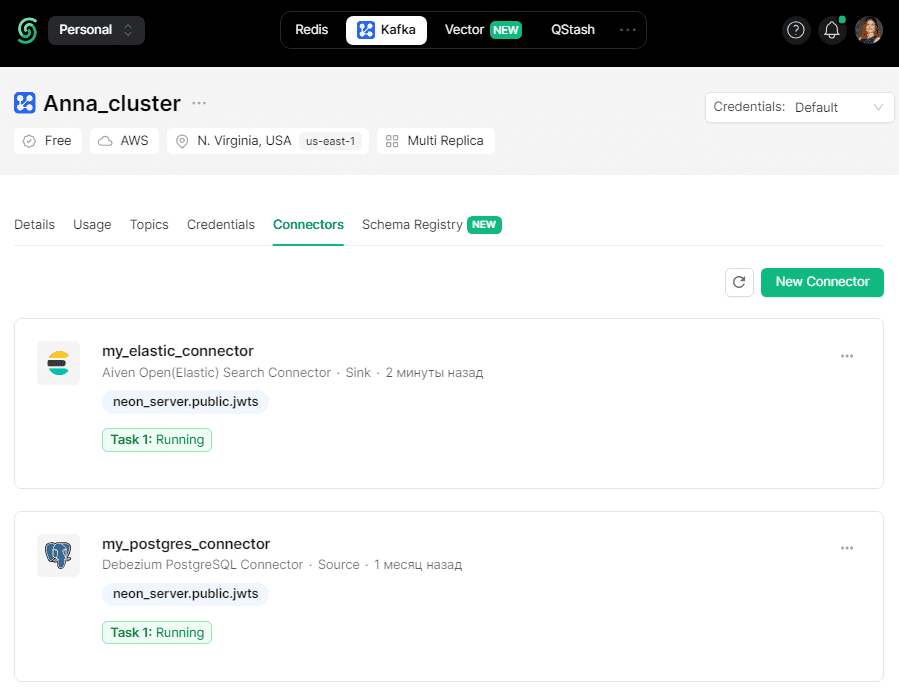
Конфигурация созданного sink-коннектора следующая:
{
"connection.password": "my-passoword",
"connection.url": "https://my-elastic-host:my-port",
"connection.username": "my-username",
"connector.class": "io.aiven.kafka.connect.opensearch.OpensearchSinkConnector",
"errors.deadletterqueue.topic.name": "my_elastic_connector-dlq",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"key.ignore": true,
"schema.ignore": true,
"topics": "neon_server.public.jwts",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false
}
При отсутствии ошибок после запуска коннектора в Elasticsearch появится индекс, куда будут записываться события об изменениях таблицы PostgreSQL с JWT-токенами в виде JSON-документов. Проще всего обнаружить это, просмотрев список индексов с помощью GET-запроса к маршруту /_cat/indices. Слова green и open перед названием индекса означают, что он работает без отказов и открыт для операций записи/чтения.

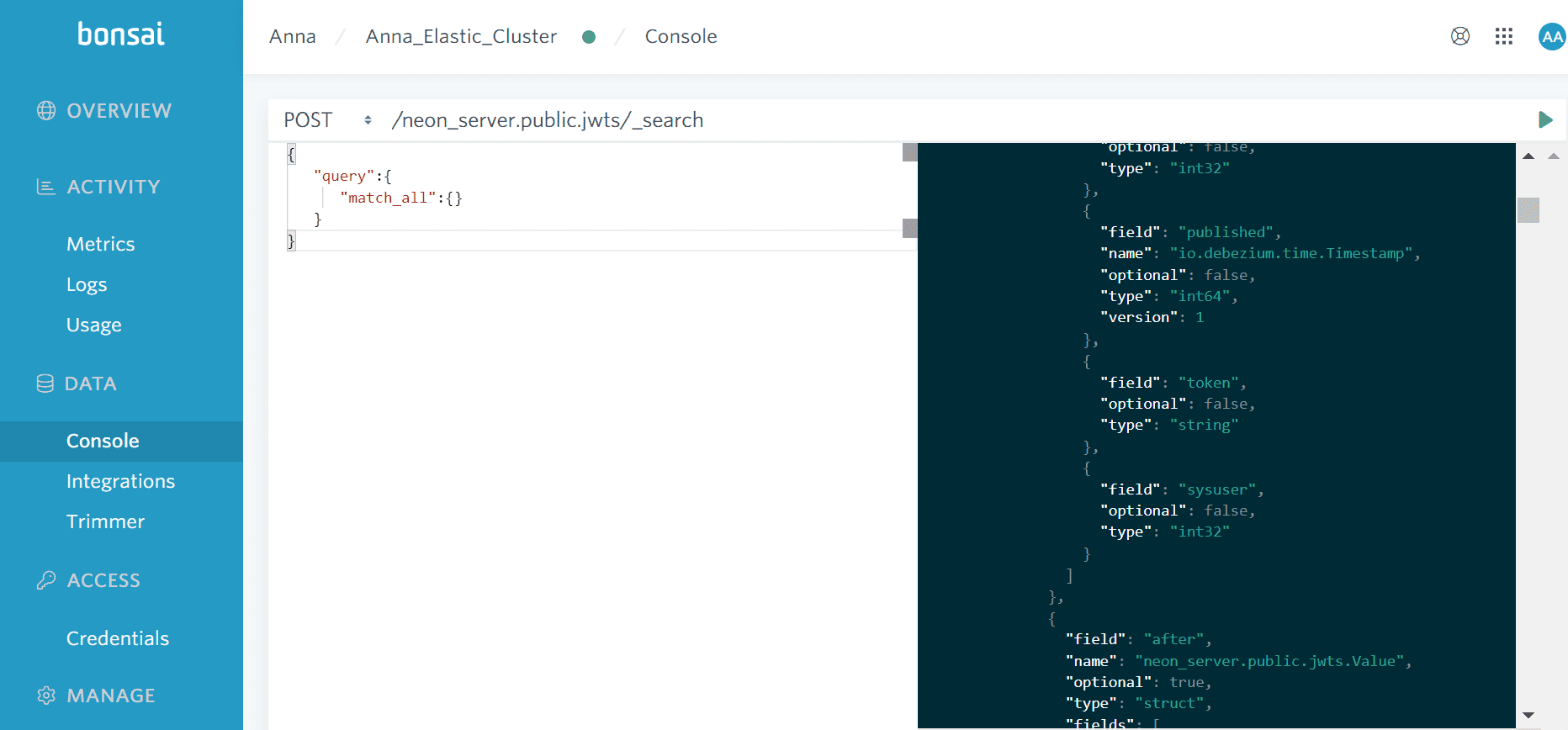
После изменения таблицы с JWT-токенами в PostgreSQL события об этом публикуются source-коннектором Debezium в топик neon_server.public.jwts, откуда потребляются sink-коннектором Aiven и записываются в Elasticsearch. Это можно посмотреть с помощью API поиска _search, сделав POST-запрос к индексу Elasticsearch с телом
{
"query":{
"match_all":{}
}
}
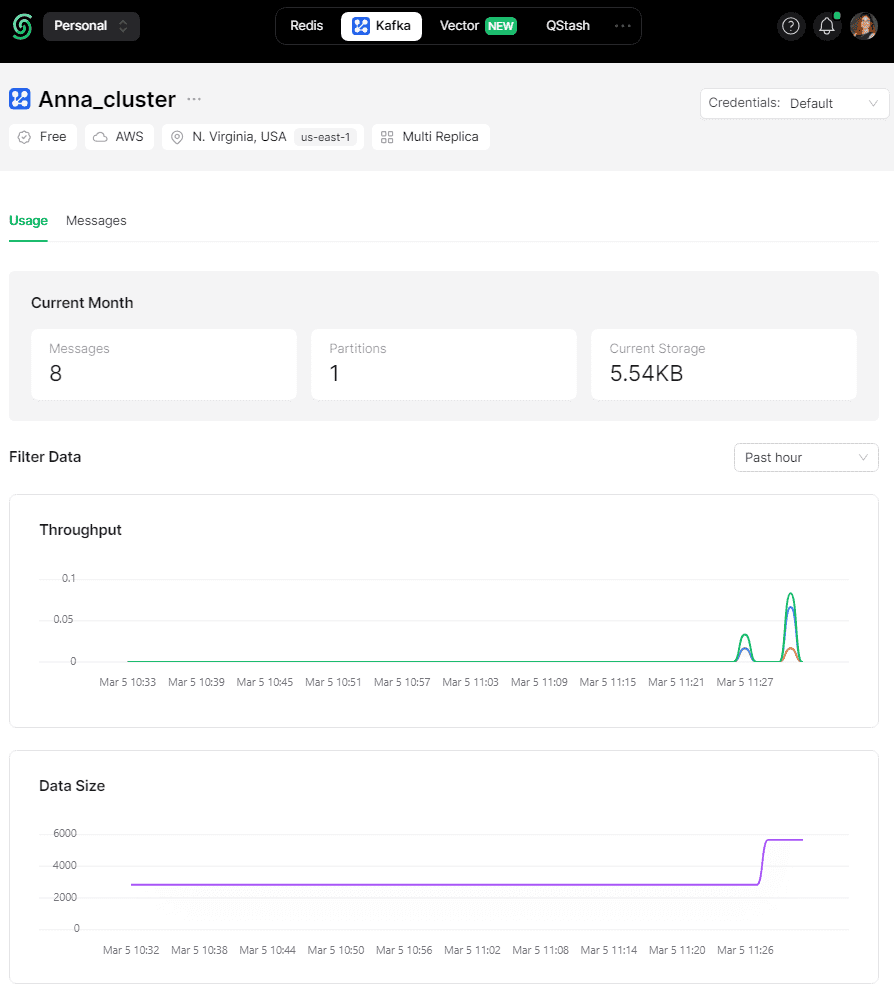
Публикация и потребление событий изменения отслеживаемой таблицы отображаются в топике Kafka.
Другой пример с этим коннектором смотрите в новой статье. А сейчас, чтобы наглядно посмотреть аналитику по выгруженным в Elasticsearch CDC-событиям, я сделала небольшой дашборд в Kibana, о чем расскажу далее.
Аналитика данных с Kibana: как создать свой дашборд
Чтобы просматривать JSON-документы в Kibana, сперва следует создать шаблон индекса, в который они входят в Elasticsearch. На облачной платформе bonsai.io, где развернут мой экземпляр Elasticsearch и веб-интерфейс Kibana, это делается в разделе управление стеком (Stack Management).
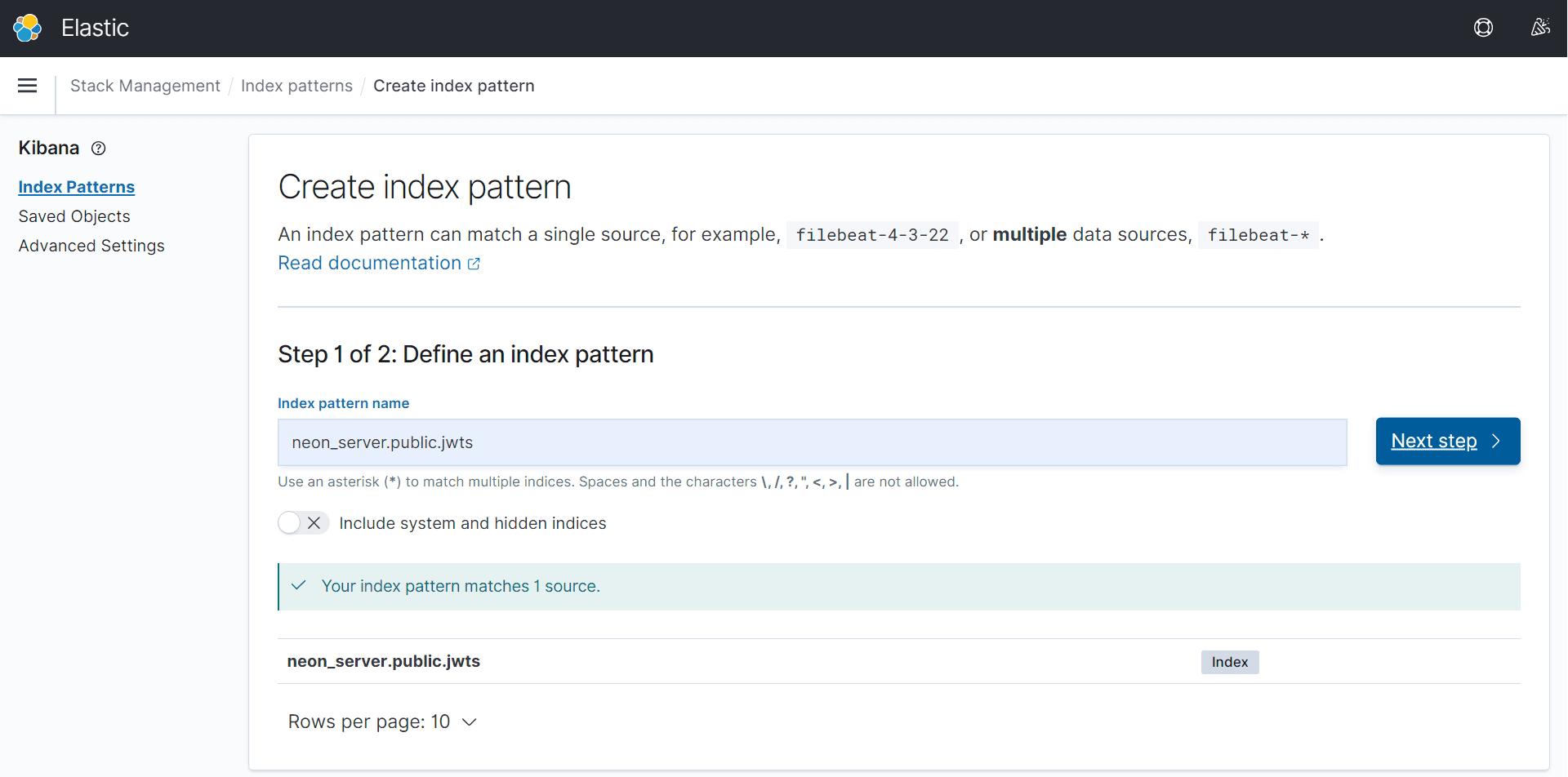
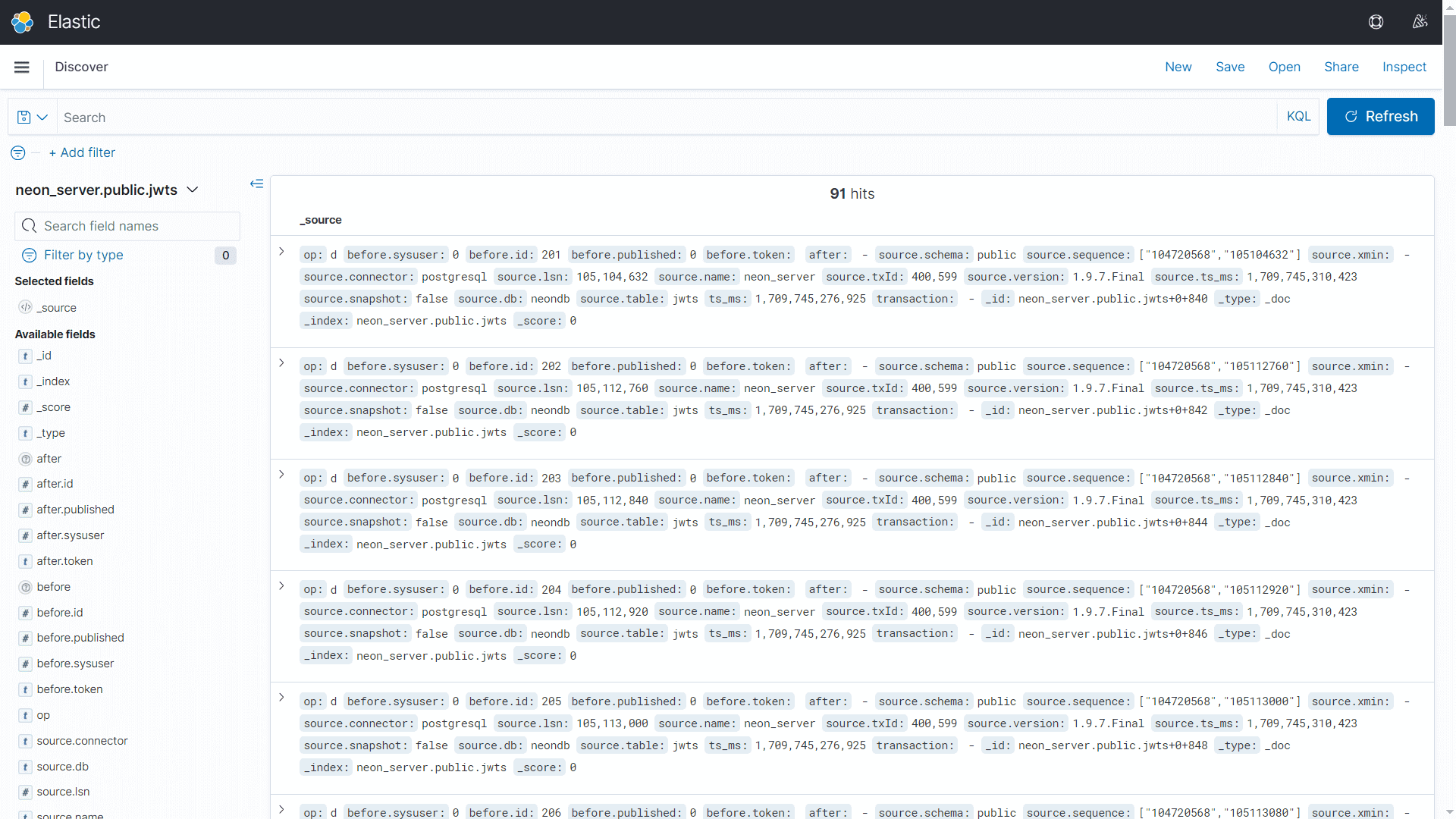
После добавления индекса можно просмотреть загруженные данные в исходном виде с помощью раздела Discover.
Создать наглядный дашборд с визуальными диаграммами в Kibana можно двумя способами:
- сперва создать необходимые визуализации, т.е. диаграммы, а затем объединить их в дэшборд;
- поступить наоборот: сперва создать дэшборд, а потом добавить к нему визуализации.
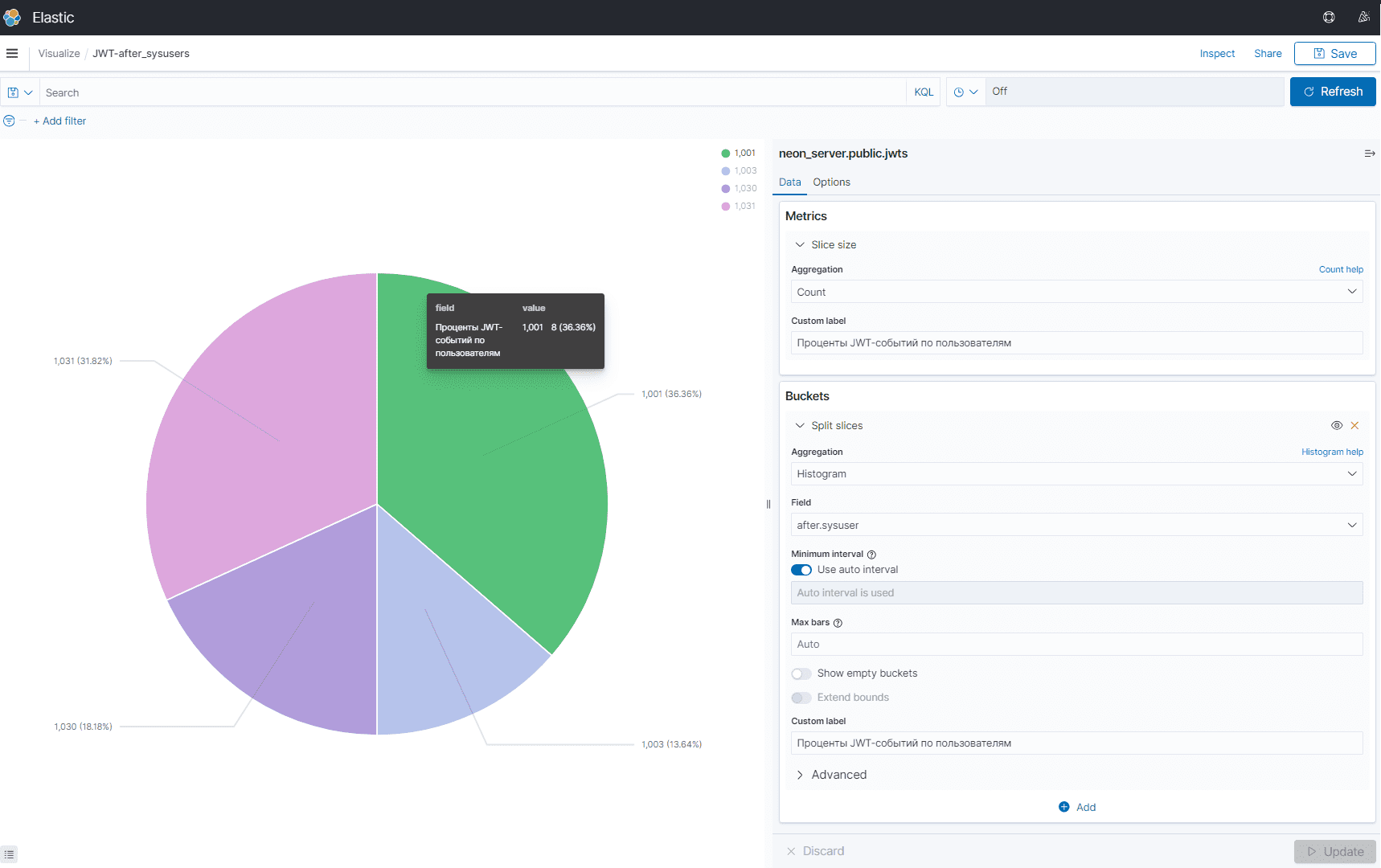
В любом случае, дашборд состоит из визуализаций. Например, следующая визуализация в виде круговой диаграммы показывает распределение JWT-событий по пользователям.
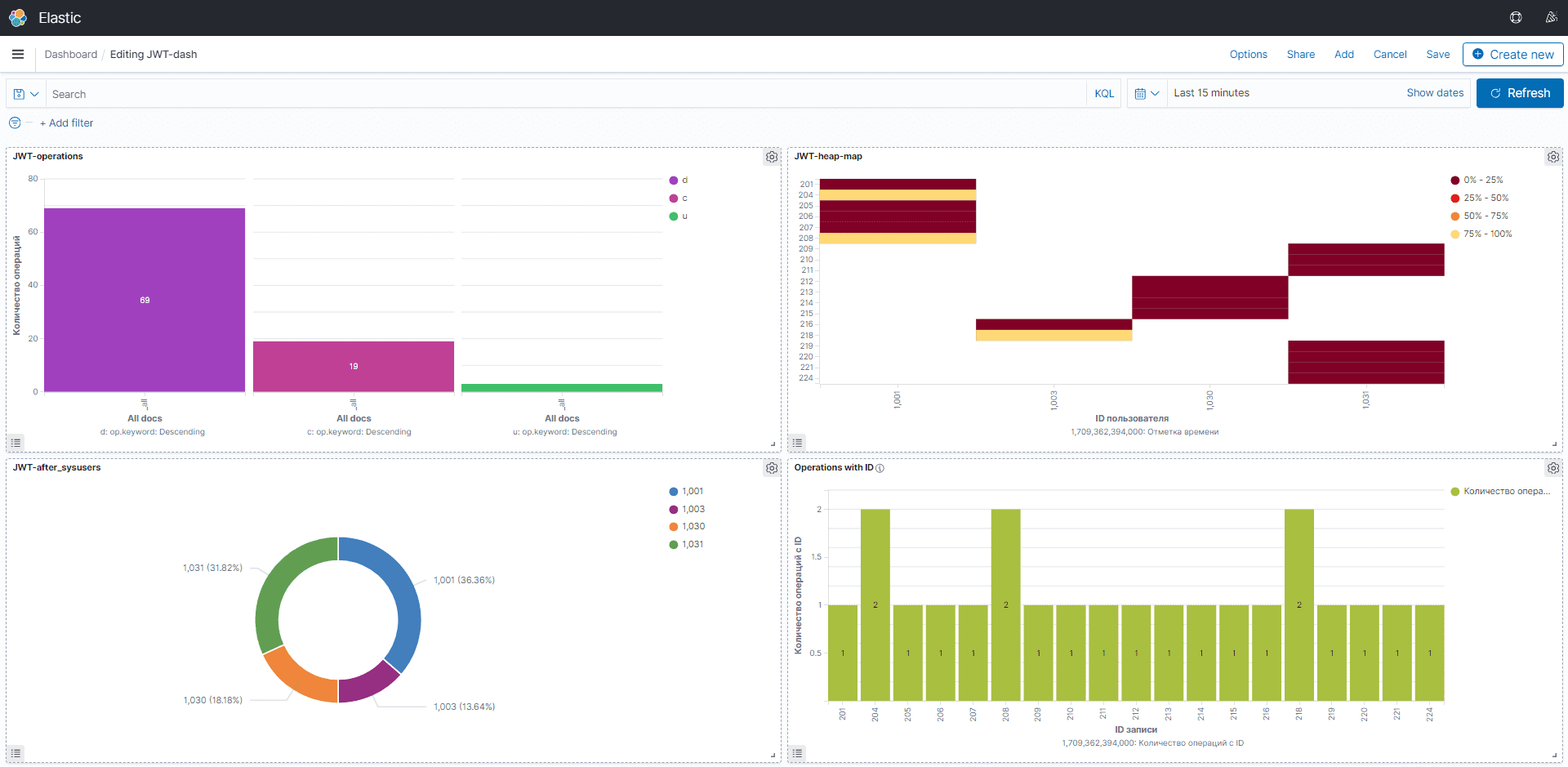
В итоговый дашборд я включила 4 визуализации, которые показывают, какие операции с JWT-таблицей были совершены, с какими пользователями связаны и насколько часто они выполнялись.
В заключение еще раз отмечу, что использование коннекторов занимает существенно меньше времени и сил по сравнению с разработкой полноценного продюсера и потребителя. Однако, применять source- и sink-коннекторы для публикации и потребления данных в/из Kafka можно только в тех случаях, когда не требуются сложные вычисления, поскольку коннектор может реализовать только относительно простые ETL-операции.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

