Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...
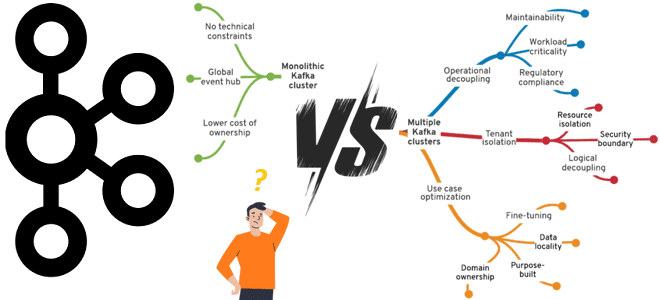
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...
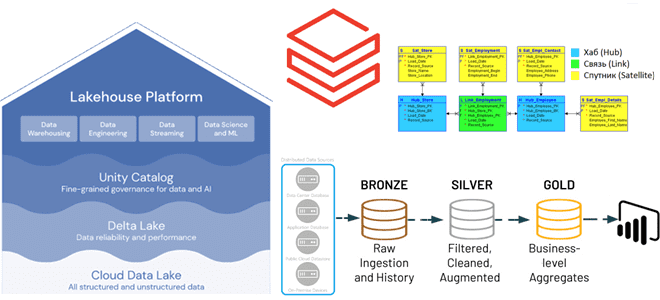
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
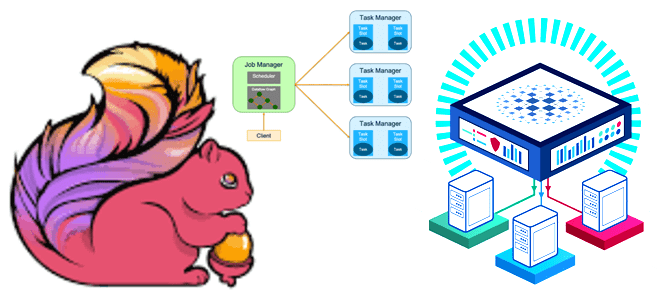
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink. Архитектура Flink-приложения: ключевые компоненты и связь между ними Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink...
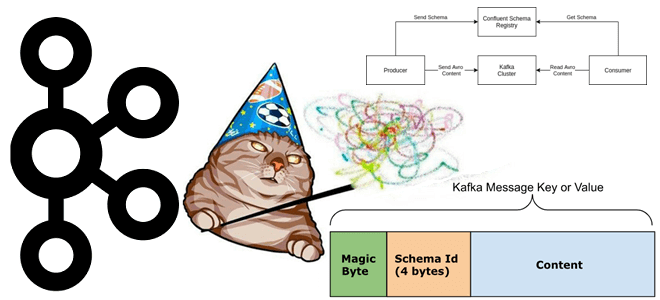
Что такое неизвестный магический байт, почему возникает эта ошибка и как предупредить такое исключение сериализации при работе с Kafka Streams, клиентами Apache Kafka и реестром схем. Что такое магический байт в сообщении Чтобы корректно обработать на стороне потребителя сообщение, считанное из Kafka, необходимо знать его формат, поскольку данные, публикуемые приложением-продюсером...
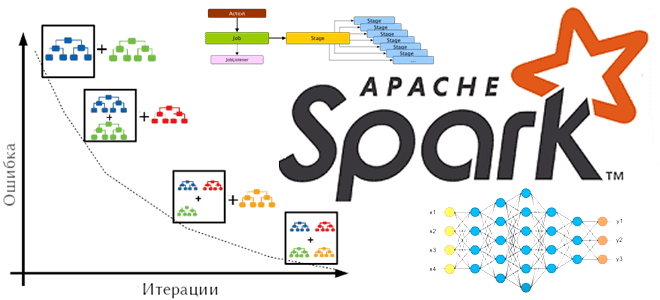
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...
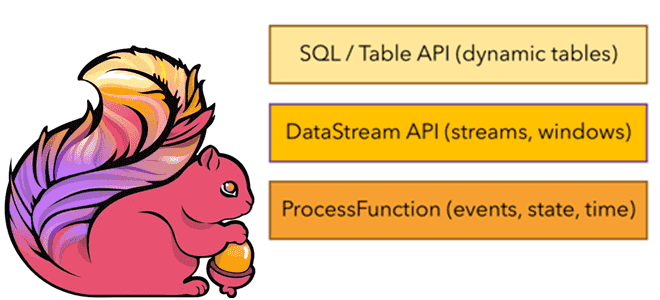
Какие возможности Apache Flink предоставляет разработчику и как их использовать: краткий обзор существующих API и потоковых примитивов. Потоковые примитивы и низкоуровневый API Будучи популярным фреймворком для stateful-вычислений над неограниченными и ограниченными потоками данных, Apache Flink предоставляет несколько API на разных уровнях абстракции и предлагает специальные библиотеки для различных сценариев. На...
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...
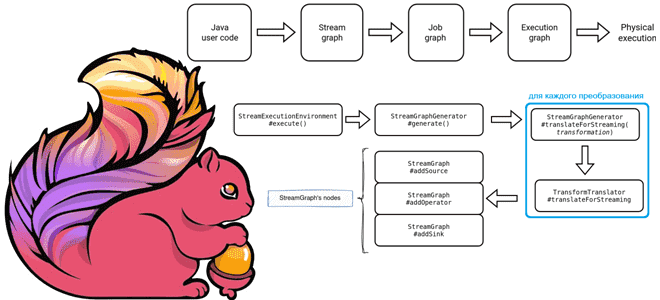
Как планируются и исполняются задания Apache Flink: от пользовательского Java-кода до физического исполнения, а также отслеживание статуса задания в JobManager. Подробности преобразований с примерами кода. 3 этапа преобразования задания Apache Flink Задание Apache Flink проходит несколько этапов перед своим физическим выполнением: сперва пользовательский код преобразуется в потоковый граф (Stream Graph);...
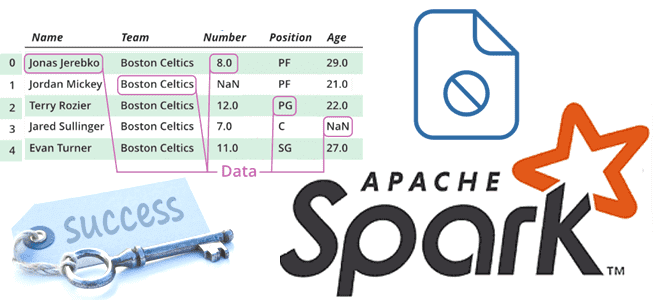
Когда и зачем Spark-приложение создает файл _SUCCESS, почему в нем нет данных, как его использовать, можно ли обойтись без него и как это сделать. Пример запуска PySpark-приложения в Google Colab. Когда и зачем Spark-приложение создает файл _SUCCESS В Apache Spark при выполнении операций записи с использованием таких методов, как saveAsTextFile(),...
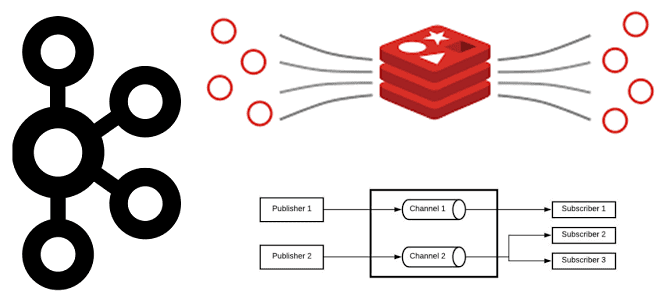
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...

Насколько быстро ClickHouse выполняет SQL-запросы: тестирование СУБД в открытой онлайн-песочнице. Примеры запросов и время их выполнения. Работа с онлайн-песочницей Clickhouse: выполнение SQL-запросов Будучи реляционной аналитической СУБД, ClickHouse позволяет обрабатывать гигабайты данных в реальном времени. Архитектурные особенности, благодаря которым реализуется такая скорость, мы недавно разбирали здесь. Чтобы оценить это на практике,...

Сходства и различия популярных реляционных аналитических СУБД с открытым исходным кодом: что общего у Greenplum с ClickHouse, чем они отличаются, что и когда выбирать. Greenplum и Clickhouse: обзор возможностей для аналитики больших данных Обе СУБД являются реляционными и относятся к классу OLAP-систем, т.е. ориентированы на аналитические варианты использования, т.е. чтение...
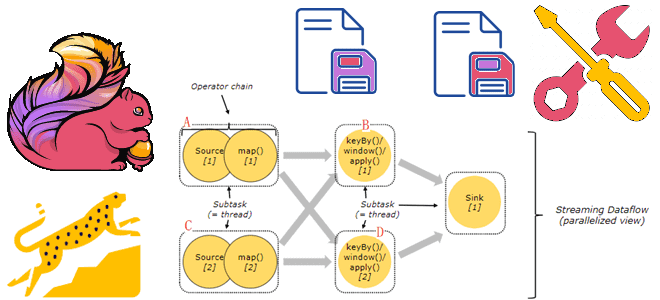
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...
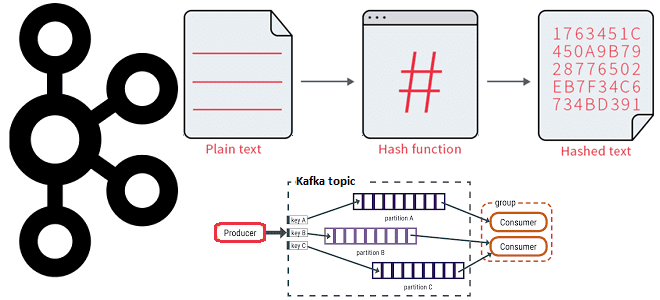
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...