Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки.
Управление ресурсами в ClickHouse
Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения распределённых SQL-запросов в ClickHouse используется сервис синхронизации метаданных ClickHouse Keeper, аналогичный по функция Apache Zookeeper, но написанный на C++. Данные в ClickHouse располагаются на разных сегментах, называемых шардами (shard). Шард – это группа копий данных (реплик) для обеспечения отказоустойчивости СУБД и параллельного выполнения SQL-запроса. Такие одновременные вычисления на всех сегментах обеспечивают ClickHouse высокую скорость работы, на порядок выше, чем, например, у Greenplum. В частности, ClickHouse может обрабатывать до 1 миллиарда строк в секунду на одном сервере и до двух ТБ в секунду на кластере из 400 узлов.
Когда ClickHouse выполняет несколько запросов одновременно, они могут использовать общие ресурсы, например, диски. Ограничения и политики планирования могут применяться для регулирования того, как ресурсы используются и распределяются между различными рабочими нагрузками. Для каждого ресурса можно настроить иерархию планирования. Корень иерархии представляет собой ресурс, а листья — это очереди, в которых хранятся запросы, превышающие емкость ресурса.
Чтобы включить планирование ввода-вывода для конкретного диска, необходимо указать значения read_resource и/или write_resource в конфигурации хранилища, которая представляет собой XML-файл.
<clickhouse>
<storage_configuration>
...
<disks>
<s3>
<type>s3</type>
<endpoint>https://clickhouse-public-datasets.s3.amazonaws.com/my-bucket/root-path/</endpoint>
<access_key_id>your_access_key_id</access_key_id>
<secret_access_key>your_secret_access_key</secret_access_key>
<read_resource>network_read</read_resource>
<write_resource>network_write</write_resource>
</s3>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
Эта конфигурация указывает ClickHouse, какой ресурс использовать для каждого запроса на чтение и запись с данного диска. Ресурс чтения и записи может ссылаться на одно и то же имя ресурса, что полезно для локальных твердотельных накопителей или жестких дисков. Несколько разных дисков также могут ссылаться на один и тот же ресурс, что полезно для удаленных дисков, например, когда надо обеспечить справедливое разделение пропускной способности сети между производственными рабочими нагрузками и запросами к тестовому контуру.
Запросы можно пометить с помощью настроек workload, чтобы различать разные рабочие нагрузки. Если параметр workload не установлен, используется значение по умолчанию. Ограничения настроек можно использовать для того, чтобы сделать их рабочие нагрузки постоянными. Это подходит для сценариев, когда все запросы пользователя отмечаются фиксированным значением настройки workload. Например, следующие 2 запроса помечены по-разному, т.к. в одном из них идет обращение к производственному контуру, а в другом – к тестовому.
SELECT count() FROM table WHERE value = 42 SETTINGS workload = 'production' SELECT count() FROM table WHERE value = 13 SETTINGS workload = 'test'
Планирование рабочих нагрузок
С точки зрения подсистемы планирования ClickHouse ресурс представляет собой иерархию узлов планирования, которые могут быть следующих типов:
- inflight_limit (ограничение) — блокируется, если количество одновременных текущих запросов превышает max_requests, или их общая стоимость превышает max_cost. Этот узел имеет один дочерний узел.
- bandwidth_limit (ограничение) — блокируется, если текущая пропускная способность превышает max_speed или пакетную нагрузку max_burst. По умолчанию max_burst равна max_speed, равной 0. Этот узел имеет один дочерний узел.
- fair (политика) — выбирает следующий запрос для обслуживания от одного из своих дочерних узлов в соответствии с максимальной и минимальной справедливостью. Дочерние узлы могут указывать вес для расчета выбора, weight, по умолчанию равный 1.
- priority (policy) — выбирает следующий запрос для обслуживания от одного из своих дочерних узлов в соответствии со статическими приоритетами, где меньшее значение означает более высокий приоритет. Дочерние узлы могут указывать priority, по умолчанию равный 0.
- fifo (очередь) — лист иерархии, способный удерживать запросы, превышающие мощность ресурса.
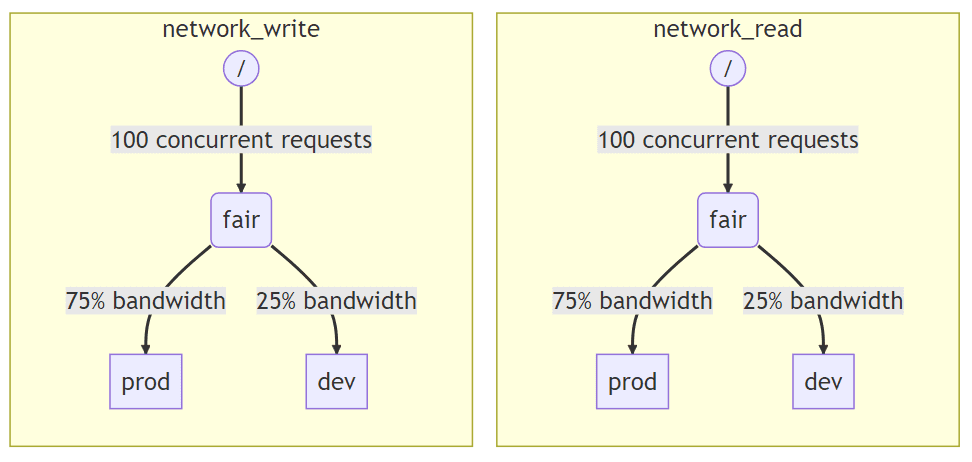
Для планирования иерархии узлов, приведенной на рисунке, нужно внести данные в конфигурационный xml-файл:
<clickhouse>
<resources>
<network_read>
<node path="/">
<type>inflight_limit</type>
<max_requests>100</max_requests>
</node>
<node path="/fair">
<type>fair</type>
</node>
<node path="/fair/prod">
<type>fifo</type>
<weight>3</weight>
</node>
<node path="/fair/dev">
<type>fifo</type>
</node>
</network_read>
<network_write>
<node path="/">
<type>inflight_limit</type>
<max_requests>100</max_requests>
</node>
<node path="/fair">
<type>fair</type>
</node>
<node path="/fair/prod">
<type>fifo</type>
<weight>3</weight>
</node>
<node path="/fair/dev">
<type>fifo</type>
</node>
</network_write>
</resources>
</clickhouse>
Для этого примера используются классификаторы рабочей нагрузки, чтобы определить сопоставления workload, указанных в запросе конечных очередей, которые надо использовать для конкретных ресурсов. На данный момент доступно только статическое сопоставление. Как обычно в ClickHouse, задать классификацию рабочих нагрузок надо в конфигурационном xml-файле:
<clickhouse>
<workload_classifiers>
<production>
<network_read>/fair/prod</network_read>
<network_write>/fair/prod</network_write>
</production>
<development>
<network_read>/fair/dev</network_read>
<network_write>/fair/dev</network_write>
</development>
<default>
<network_read>/fair/dev</network_read>
<network_write>/fair/dev</network_write>
</default>
</workload_classifiers>
</clickhouse>
Чтобы использовать всю мощность базового ресурса, следует настроить параметр inflight_limit. Слишком низкое число max_requests или max_cost может привести к неполному использованию ресурсов, а слишком большое – к пустым очередям внутри планировщика. Это приведет к игнорированию политик (справедливости или приоритетов) в поддереве.
С другой стороны, когда нужно защитить ресурсы от слишком высокой загрузки, следует использовать параметр bandwidth_limit. Он регулируется, когда объем ресурсов, потребляемых в durationсекундах, превышает сумму байтов (max_burst+max_speed*duration). Два узла bandwidth_limit на одном ресурсе можно использовать для ограничения пиковой пропускной способности в течение коротких интервалов и средней пропускной способности для более длительных интервалов.
Квоты на использование ресурсов
Наконец, для эффективной утилизации ресурсов в ClickHouse есть механизм квот. Он позволяет настроить квоты, чтобы ограничить использование ресурсов в течение определенного периода времени или отслеживать их. Эти квоты настраиваются в пользовательской конфигурации, обычно это xml-файл users.xml, пример которого показан далее:
<!-- Quotas -->
<quotas>
<!-- Quota name. -->
<default>
<!-- Restrictions for a time period. You can set many intervals with different restrictions. -->
<interval>
<!-- Length of the interval. -->
<duration>3600</duration>
<!-- Unlimited. Just collect data for the specified time interval. -->
<queries>0</queries>
<query_selects>0</query_selects>
<query_inserts>0</query_inserts>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
Квота назначается пользователям в разделе «Пользователи» конфигурации. Для распределенной обработки запросов накопленные суммы сохраняются на сервере запроса. Это означает, что при переходе пользователя на другой сервер, квота на нем обнулится и начнется заново. При перезапуске сервера квоты сбрасываются. По умолчанию квота отслеживает потребление ресурсов за каждый час без ограничения использования. Потребление ресурсов, рассчитанное для каждого интервала, выводится в журнал сервера после каждого запроса.
В квоте можно задать ограничения на следующие параметры:
- queries – общее количество запросов;
- query_selects – общее количество выбранных запросов;
- query_inserts – общее количество запросов на вставку;
- errors – количество запросов, вызвавших исключение;
- result_rows – общее количество строк, полученных в результате;
- read_rows – общее количество исходных строк, прочитанных из таблиц для выполнения запроса на всех удаленных серверах;
- execution_time – общее время выполнения запроса в секундах. Если лимит превышен хотя бы в течение одного временного интервала, генерируется исключение с текстом о том, какое ограничение было превышено, за какой интервал и когда начинается новый интервал, когда запросы можно отправлять снова.
Квоты могут использовать ключ, чтобы независимо сообщать о ресурсах для нескольких ключей.
Освойте администрирование и эксплуатацию ClickHouse для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

