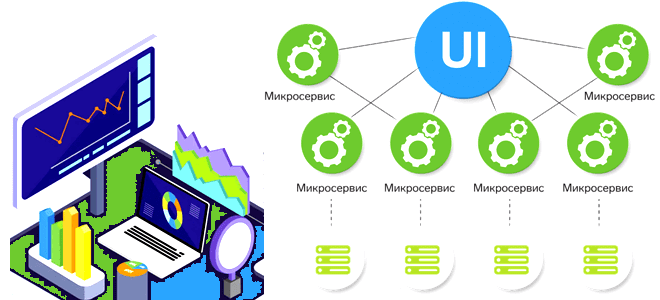
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...

Чем тип JSONB отличается от JSON и почему это так важно для хранения и обработки данных гибкой структуры в Greenplum. Примеры SQL-запросов к JSON-данным и особенности синтаксиса JSONPath. Чем JSONB отличается от JSON и почему это так важно? Будучи основанной на PostgreSQL, Greenplum имеет множество аналогичных возможностей, включая поддержку работы...
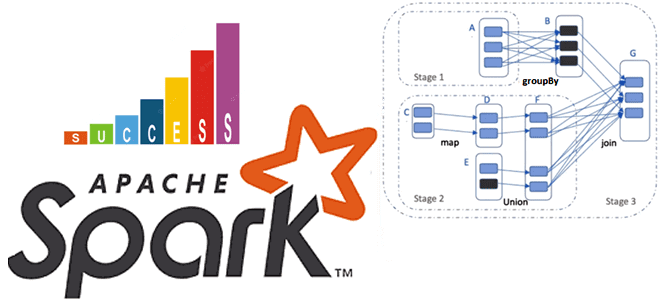
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...
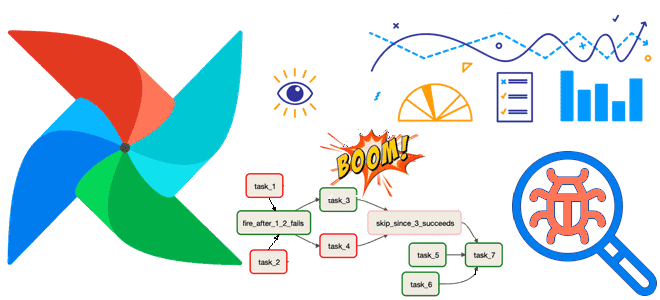
Проблемы отладки конвейеров обработки данных в Apache AirFlow и способы их решения средствами самого фреймворка. Как дата-инженеру настроить мониторинг системных событий на уровне DAG или отдельной задачи: операторы, кластерные политики и обратные вызовы. Отладка конвейеров обработки данных в Apache AirFlow: проблемы и возможности Практикующий дата-инженер знает, как бывает сложно найти...
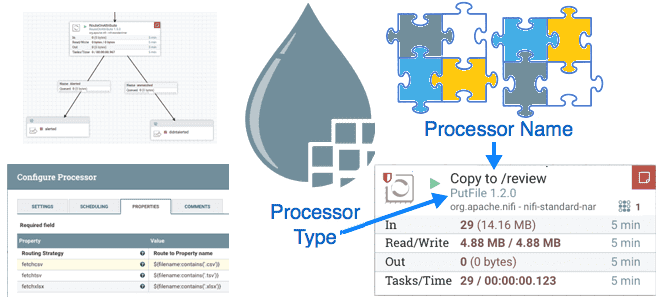
Вчера мы писали про паттерны проектирования процессоров Apache NiFi, ориентированные на данные. Сегодня рассмотрим шаблоны с фокусом на маршрутизацию потоковых файлов, которые можно применять при разработке пользовательского процессора. Маршрутизация на основе содержимого (Route Based on Content) Процессор этого типа направляет входящий FlowFile на основе его содержимого в одно или несколько...

Что пригодится дата-инженеру при разработке пользовательского процессора Apache NiFi: паттерны приема и выдачи данных, а также обогащение содержимого потокового файла. Знакомимся с принципами работы шаблонов проектирования процессоров NiFi, ориентированных на данные. Прием данных (Data Ingress) Apache NiFi предоставляет более 300 готовых процессоров – обработчиков, которые выполняют определенные действия с потоковыми...
Что не так с механизмом контрольных точек в Apache Flink, и как журнал изменений состояния справляется с ростом сквозной задержки в потоковой обработке данных средствами этого фреймворка. Проблемы контрольных точек в Apache Flink Одной из наиболее важных характеристик систем потоковой обработки данных является сквозная задержка, которая в Apache Flink зависит...
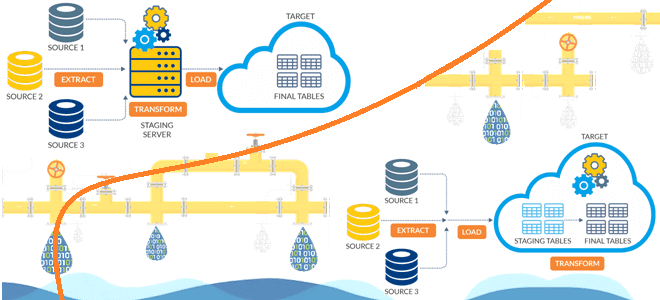
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов. Чем ETL отличается от ELT: ликбез для дата-инженера Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их...
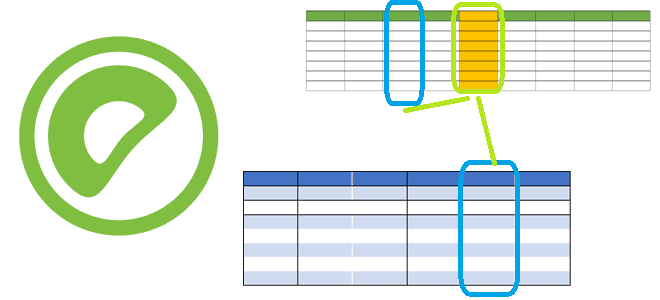
Зачем в Greenplum 7 добавлены вычисляемые (генерируемые) столбцы, как их использовать, и чем они опасны: достоинства, недостатки и ограничения этой возможности. Что такое генерируемые столбцы Поскольку Greenplum основана на PostgreSQL, эта MPP-СУБД имеет множество похожих функций. В частности, в 7-ю версию Greenplum добавлена возможность сохранения вычисляемых (генерируемых) столбцов, которые вычисляются...

Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...