 1139
1139 
Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI.
Что такое сервер истории Apache Spark
Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько приложений запускаются с одного и того же хоста, порт инкрементируется, например, 4041, 4042 и пр. Какие данные, полезные дата-инженеру при отладке и мониторинге программы можно увидеть в этом GUI, мы подробно писали здесь. Жизненный цикл этого веб-GUI привязан к Spark-приложению. Когда приложение Spark запускается, оно создает набор журналов событий, которые хранятся на жестком диске компьютера, где было запущено приложение. Эти журналы содержат подробную информацию о приложении, включая данные о выполнении задания, параметры конфигурации Spark и другие метаданные. Чтобы просмотреть журналы приложения после его завершения, нужно использовать сервер истории Spark, который отображает информацию о конфигурации фреймворка, заданиях, этапах, исполнителях и задачах, поток выполнения DAG, а также сведения об использовании ресурсов драйвера и исполнителя.
Для этого сервер истории Spark использует перехватчики событий, т.е. слушатели (SparkListeners). Каждая вкладка в веб-GUI Spark питается от шины событий. Пользовательский интерфейс сервера истории будет отображать задания Spark, если они настроены для регистрации событий в том же расположении, которое он отслеживает. Местом хранения может быть любая файловая система, доступная как для приложения Spark, так и для сервера истории, например, Hadoop HDFS.
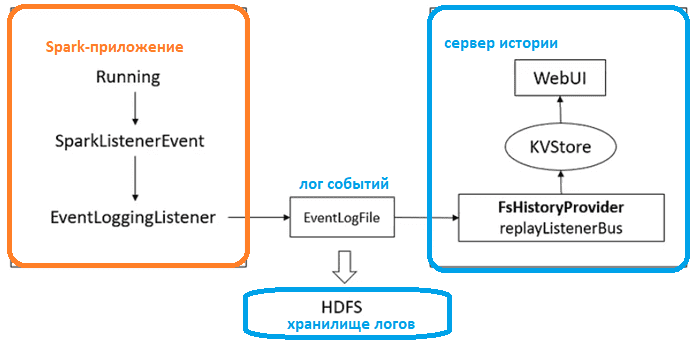
Как именно сервер истории и другие инструмента мониторинга Spark-заданий используют механизм слушателей, мы рассмотрим далее.
Слушатели: перехватчики событий
В Spark есть много счетчиков, которые можно использовать во время выполнения задания. Каждый из них отслеживает определенные компоненты задания, такие как время выполнения задачи, время сборки мусора JVM, количество прочитанных или записанных записей, время выполнения исполнителя, время сериализации и пр.
Spark позволяет программно получать значения этих счетчиков с помощью API слушателей. Этот API предоставляет информацию о dataShuffle, Input, Spill, Execution/Storage Memory Peak, причине отказа, причине удаления исполнителей и т. д.
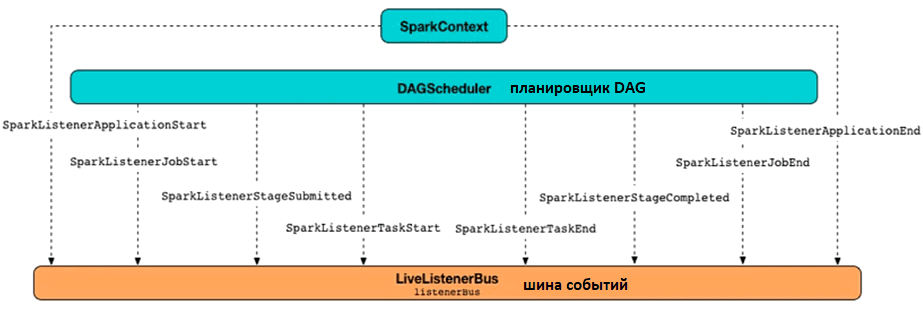
Чтобы использовать слушатели для мониторинга и отладки Spark-приложения, их сперва следует подключив, установив конфигурацию, например:
spark.sql.queryExecutionListeners spark.extraListeners spark.stream.addListeners spark.sql.streaming.streamingQueryListeners
Эти слушатели имеют следующие методы, которые можно подключить и переопределить для использования в своих целях, например, чтобы отследить события запуска и окончания работы приложения, .задания, задачи, и пр: ApplicationEnd, ApplicationStart, ExecutorAdded, ExecutorRemoved, JobEnd, JobStart, StageCompleted, StageSubmitted, TaskEnd, TaskGettingResult, TaskStart. В частности, слушатель Query Execution Listener позволяет разработчику подписываться на события завершения запроса. Он предоставляет более высокоуровневые метаданные о выполненных запросах, такие как логические и физические планы и показатели выполнения. Примечательно, что записи, прочитанные или записанные запросом, объединяются для всего запроса, а не для задачи или этапа.
Настраиваемый слушатель SQLListener активирует вкладку SQL в веб-интерфейсе Spark, отображая событий начала и конца выполнения SQL-запроса с помощью методов SQLExecutionStart, SQLExecutionEnd и DriverAccumUpdates. А слушатель StreamingQueryListeners выдает данные о событиях жизненного цикла потоковых запросов с помощью методов QueryStarted, QueryProgress, QueryTerminated, о чем мы писали здесь.
Чтобы добавить собственный слушатель, необходимо выполнить следующие шаги:
- Написать код на Scala/Java и упаковать его в JAR-архив;
- Добавить этот JAR-архив в Spark.driver.extraClassPath и Spark.executor.extraClassPath в PySpark или запустите SparkConf приложения на Scala/Java;
- Добавить полное имя класса слушателя в свойство конфигурации spark.extraListeners:
В заключение добавим, что не только сервер истории и веб-GUi Apache Spark используют слушателей для получения данных метрик, связанных с заданием. Также этот механизм перехвата событий лежит в основе сторонних решений мониторинга, таких как Sparklens, Dr Elephant, Sparkmonitor и SparkMeasure, который упрощает сбор и анализ показателей производительности.
SparkMeasure обеспечивает мониторинг путем передачи метрик во внешние системы, такие как InfluxDB, Apache Kafka, шлюз Prometheus, позволяя выполнять тестирование, измерение и сравнение показателей выполнения Spark-заданий с меняющимися конфигурациями или кодом на Scala, Python и Java.
Освойте тонкости применения Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

