 1230
1230 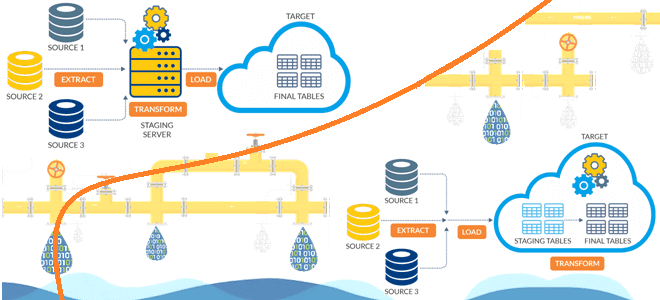
Содержание
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов.
Чем ETL отличается от ELT: ликбез для дата-инженера
Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их преобразование в нужный формат или необходимую структуру и загрузку в репозиторий (хранилище или озеро данных).
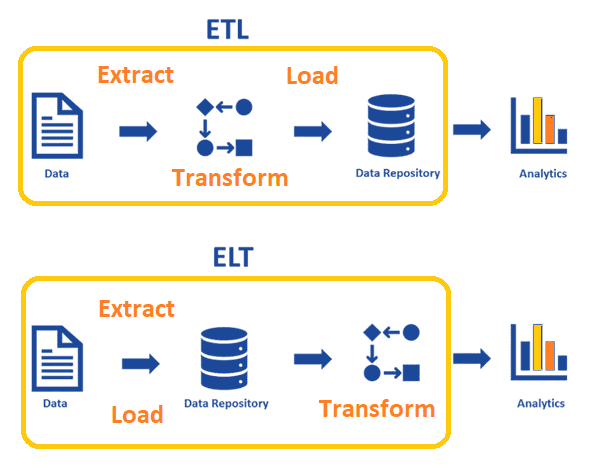
В ETL (Extract-Transform-Load) преобразование происходит после извлечения данных и перед их загрузкой, тогда как в ELT (Extract- Load-Transform) преобразование выполняется после загрузки. В ETL терабайты данных сперва поступают в промежуточную область, где они преобразуются с помощью сложных вычислений, а затем загружаются в какой-то репозиторий данных. Хотя преобразование большого набора данных занимает вычислительных ресурсов, после этого данные можно запросить почти сразу для дальнейшего анализа и обработки.
В ELT множество данных загружается в репозиторий, и операции преобразования над ними выполняются только по мере необходимости, что экономит вычислительные ресурсы, но может замедлить скорость аналитических запросов.
ETL имеет более длительную историю существования (с 1970-х годов), но больше подходит для работы со структурированными данными. Именно поэтому при работе с DWH используются ETL-конвейеры. Однако, сегодня большинству бизнес-доменов требуется масштабируемые и эффективные способы обработки как структурированных, так и неструктурированных данных (изображения, видео, PDF-файлы и пр.), в т.ч. в режиме реального времени и с помощью машинного обучения. Именно ELT предлагает гибкость, необходимую для обеспечения быстрого доступа к данным в Data Lake – озере данных.
Тем не менее, ETL по-прежнему является наиболее широко используемой архитектурой конвейера данных, совместимой со средствами обеспечения безопасности. Поэтому далее мы рассмотрим, как построить эффективные ETL-конвейеры, используя современные технологии Big Data.
Как построить высокоэффективные конвейеры ETL
Чтобы справиться с пиковыми моментами нагрузки, резко растет объем данных, извлекаемых из источников, инфраструктура ETL должна иметь возможность эластично добавлять вычислительные ресурсы. Сегодня с этим отлично справляются средства оркестрации, например, Kubernetes, AWS ECS, AWS EKS, Nomad и пр. В частности, AWS ECS проще в управлении по сравнению с управляемым сервисом Kubernetes в том же Amazon (AWS EKS). Помимо планирования рабочих процессов в экземплярах ECS, связанных с поставщиком емкости для автоматического масштабирования, ECS отлично подходит для запуска рабочих ETL-процессов: при необходимости запуска дополнительного количества задач в ECS, провайдер ресурсов автоматически добавит экземпляры для их включения. Также вместо автоматического масштабирования службы ECS можно использовать лямбда-выражение AWS, которое управляет масштабированием рабочих процессов ECS.
Чтобы повысить надежность конвейера данных, необходимо включить в архитектуру инструменты мониторинга и генерации оповещений о системных ошибках и критических сбоях. К примеру, можно отслеживать, сколько рабочих процессов требуется для обработки доступных заданий, используя комбинацию предупреждений Cloudwatch + Cloudwatch EventRule + SNS + Lamda.
Однако, при работе с большими данными затраты на облачную инфраструктуру могут расти. Сэкономить поможет использование спотовых инстансов, которые на 90 % дешевле по сравнению с обычными экземплярами по запросу (on-demand). Однако, надежность спотовых инстансов невысока: они могут отключаться. Решить эту проблему поможет повышение отказоустойчивости системы, а также масштабирование до полного нуля с помощью лямбда-сервиса Scaler, который завершает все доступные экземпляры, когда нет данных для обработки.
Чтобы отслеживать статус каждого задания загрузки данных в ETL-конвейерах, можно использовать NoSQL-СУБД для хранения статусов и других метаданных. Например, это может быть AWS DynamoDB или другая нереляционная база данных типа ключ/значение (key-value). Для визуализации хранимых данных, эту СУБД можно подключить к панели аналитики, например, AWS Quicksight.
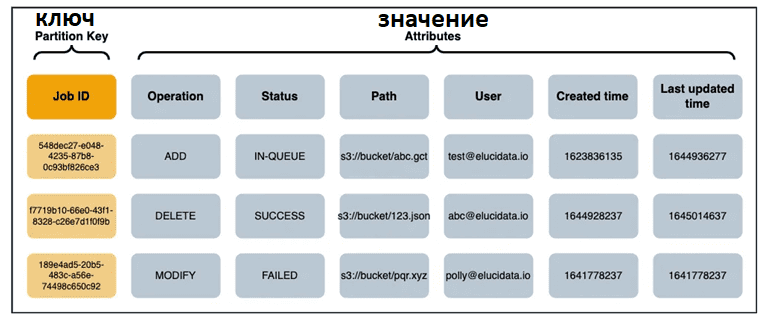
При использовании спотовых инстансов для запуска ETL-процессов, их неожиданное завершение между заданиями неизбежно. В таком случае задание следует повторить нужное количество раз, прежде чем оно будет помечено как FAILED. Чтобы определить незавершенное задание, можно применить функцию тайм-аута видимости SQS, а затем назначить новый worker для повторного запуска.
В заключение перечислим несколько распространенных ошибок дата-инженеров при построении конвейеров обработки данных. В частности, не рекомендуется использовать системные дату и время в бизнес-логике преобразования данных. А для обеспечения качества следует применять инструменты профилирования, чтобы проверить уникальность идентификаторов и естественных ключей исходных данных, а также типов данных и целостность связей по внешним ключам. Сюда же относится обработка пропущенных значений и выбросов. Подробнее про профилирование данных мы писали здесь.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

