 388
388 
Зачем в Greenplum 7 добавлены вычисляемые (генерируемые) столбцы, как их использовать, и чем они опасны: достоинства, недостатки и ограничения этой возможности.
Что такое генерируемые столбцы
Поскольку Greenplum основана на PostgreSQL, эта MPP-СУБД имеет множество похожих функций. В частности, в 7-ю версию Greenplum добавлена возможность сохранения вычисляемых (генерируемых) столбцов, которые вычисляются из значений других атрибутов, но изначально не хранится в базе данных, подобно представлению таблицы. Различают 2 вида генерируемых столбцов:
- сохранённый (STORED), который вычисляется при записи (добавлении или изменении) и занимает место в таблице так же, как и обычный столбец;
- виртуальный, который не занимает места и вычисляется при чтении.
Таким образом, виртуальный генерируемый столбец похож на представление, а сохранённый генерируемый — на материализованное представление, которое всегда обновляется автоматически. Сгенерированные столбцы полезны в тех случаях, когда расчетное значение необходимо отображать часто, а его вычисление стоит дорого, выполняется долго или нецелесообразно. Сохраненные сгенерированные столбцы рассчитываются во время вставки или обновления и сохраняются на диске как часть данных таблицы.
Генерируемые столбцы пересчитываются после выполнения триггеров BEFORE. Поэтому в них отражаются те изменения, которые производятся триггером BEFORE в базовых столбцах. Но обращаться в коде такого триггера к генерируемым столбцам нельзя. Подробнее про триггеры и хранимые процедуры в Greenplum и PostgreSQL мы писали здесь.
Как и PostgreSQL, Greenplum поддерживает только сохранённые генерируемые столбцы. Поэтому при создании генерируемого столбца обязательно указывать ключевое слово STORED в предложении GENERATED ALWAYS AS команды CREATE TABLE, например:
CREATE TABLE t ( w real, h real, area real GENERATED ALWAYS AS (w*h) STORED );
Поскольку значения генерируемого столбца вычисляются автоматически, напрямую записать в них данные нельзя. Это означает, что в командах INSERT или UPDATE невозможно указывать названия генерируемых столбцов. В отличие от значения столбца по умолчанию (DEFAULT), которое вычисляется один раз при 1-ой вставке строки в таблицу, значение генерируемого столбца может меняться при изменении строки и не может быть переопределено. Выражение значения по умолчанию не может обращаться к другим столбцам таблицы, тогда как генерирующее выражение, наоборот, обращается к ним. В выражении значения по умолчанию могут вызываться такие функции как random() или функции, зависящие от времени, а для генерируемых столбцов это недопустимо.
Это не единственные ограничения генерируемых столбцов и таблиц, в которых они присутствуют. Сюда же относятся следующие особенности:
- в генерирующем выражении могут использоваться только постоянные функции, т.е. не random() или now();
- в генерирующем выражении не могут использоваться подзапросы и ссылки на значения, не относящиеся к данной строке;
- генерирующее выражение не может обращаться к другому генерируемому столбцу или системным столбцам, кроме tableoid;
- для генерируемого столбца нельзя задать значение по умолчанию или свойство идентификации;
- генерируемый столбец не может быть частью ключа секционирования;
- генерируемые столбцы могут содержаться в сторонних таблицах;
- если родительский столбец является генерируемым, дочерний должен генерироваться тем же выражением. При этом в определении дочернего столбца опускается предложениеGENERATED, поскольку оно копируется из родительского.
- В случае множественного наследования, если один родительский столбец является генерируемым, все соответствующие ему столбцы в иерархии наследования должны генерироваться тем же выражением.
- Если родительский столбец не является генерируемым, дочерний столбец может быть как генерируемым, так и обычным.
- Права доступа к генерируемым столбцам настраиваются отдельно от прав на нижележащие базовые столбцы. В частности, можно сделать так, чтобы определённый пользователь мог прочитать лишь генерируемый столбец, но не нижележащие базовые столбцы.
В Greenplum генерируемые столбцы также можно использовать с внешними таблицами. Вычисленное значение будет представлено оболочке сторонних данных для хранения и должно быть возвращено при чтении. Чтобы понять основные варианты использования генерируемых столбцов, рассмотрим несколько практических примеров.
Варианты использования в Greenplum
В этом примере столбец raw_data содержит список показаний датчиков, разделенных запятыми. Каждое показание представляет собой одно значение в определенный момент времени. Преобразовать эти необработанные данные в более структурированный формат можно с помощью функции процедурного языка PL/Python для получения среднего значения показаний заданного датчика из необработанных данных. Эта Python-функция является неизменяемой (IMMUTABLE), всегда возвращая один и тот же результат для одного и того же ввода.
Сперва создадим таблицу:
CREATE TABLE sensor_data (
id SERIAL PRIMARY KEY,
timestamp TIMESTAMP NOT NULL,
sensor_id VARCHAR(255) NOT NULL,
raw_data TEXT NOT NULL
);
Добавим в таблицу данные:
INSERT INTO sensor_data (timestamp, sensor_id, raw_data) VALUES ('2022-01-01 00:00:00', 'sensor1', '23.5,24.1,25.3,24.9,26.2');
INSERT INTO sensor_data (timestamp, sensor_id, raw_data) VALUES ('2022-01-01 00:01:00', 'sensor2', '18.7,18.9,19.1,19.0,18.8');
INSERT INTO sensor_data (timestamp, sensor_id, raw_data) VALUES ('2022-01-01 00:02:00', 'sensor1', '24.2,25.6,27.3,29.1,30.0');
Подключим Python-расширение:
CREATE extension plpython3u;
Определим функцию вычисления среднего значения:
CREATE OR REPLACE FUNCTION get_average(raw_data TEXT)
RETURNS FLOAT
AS $$
values = raw_data.split(',')
total = sum(float(value) for value in values)
count = len(values)
return total / count if count > 0 else 0.0
$$ LANGUAGE plpython3u IMMUTABLE;
Выполним определенную функцию, чтобы получить результаты:
SELECT sensor_id , raw_data, get_average(raw_data) FROM sensor_data;
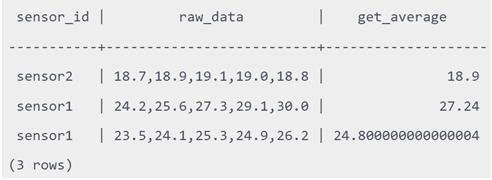
Результаты, представленные в колонке вывода get_average можно преобразовать в сгенерированный столбец, создав в таблице новый столбец, который вычисляет и сохраняет результат функции:
ALTER TABLE sensor_data ADD COLUMN average_value FLOAT GENERATED ALWAYS AS (
get_average(raw_data)
) STORED;
Это позволит избежать вычислений при извлечении записей:
SELECT * FROM sensor_data;
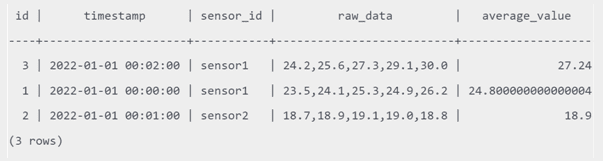
Таким образом, генерируемые столбцы особенно полезны для хранения трудоемких вычислений и повышения производительности запросов. Также они могут пригодиться при миграции в Greenplum с других СУБД, таких как SQL Server и Oracle, которые уже давно используют вычисляемые столбцы.
По умолчанию значения сгенерированных столбцов не используются с командами копирования (COPY). Поэтому данные столбцов, сгенерированные во время резервного копирования, с целью экономии места в файлах резервных копий не выводятся и вычисляются на лету во время операции восстановления. Это характерно для утилит gpbackup, gpcopy и pg_dump.
Подводя итог, еще раз перечислим преимущества сохраненных генерируемых столбцов в Greenplum:
- повышение производительности запросов, т.к. вычисленное значение физически хранится в таблице, и его можно быстро извлечь без выполнения вычислений при каждом запросе;
- упрощенное управление данными за счет сокращения объема кода для выполнения расчетов;
- непротиворечивость данных — сохраненные генерируемые столбцы гарантируют, что вычисляемое значение всегда будет актуальным и непротиворечивым, независимо от способов обработки данных.
Однако, генерируемые столбцы в Greenplum имеют следующие недостатки и ограничения:
- отсутствие значений по умолчанию;
- невозможность выступать в качестве ключа, однозначно идентифицирующего запись в таблице. Это означает, что сгенерированный столбец не может быть частью первичных ключей или ограничений уникальности;
- генерируемый столбец не может быть частью ключа разделения и распределения данных;
- выражение генерации значений такого столбца может использовать только неизменяемые функции (IMMUTABLE), а также не может использовать подзапросы или ссылаться на что-либо, кроме текущей строки, включая другой сгенерированный столбец и системные столбцы, кроме tableoid.
Наконец, генерируемые столбцы могут влиять на производительность записи, поскольку их значения необходимо вычислять и сохранять при каждой операции вставки или обновления.
Узнайте больше подробностей про администрирование и эксплуатацию Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

