 941
941 
Что не так с механизмом контрольных точек в Apache Flink, и как журнал изменений состояния справляется с ростом сквозной задержки в потоковой обработке данных средствами этого фреймворка.
Проблемы контрольных точек в Apache Flink
Одной из наиболее важных характеристик систем потоковой обработки данных является сквозная задержка, которая в Apache Flink зависит от механизма контрольных точек, который предполагает автоматическое создание образа состояния задания в определенный момент времени. Это обеспечивает отказоустойчивость и содержит состояние операторов в задании Flink, а также указатели смещения для каждого из источников данных. Результаты потоковой обработки должны стать видимыми только после того, как состояние потока будет сохранено в энергонезависимой памяти или опубликованы.
Создание контрольной точки в Apache Flink состоит из двух фаз:
- Синхронизация, когда состояния в памяти сбрасываются на диск;
- Асинхронный этап, когда локальные файлы состояния загружаются в удаленное хранилище.
Контрольная точка завершается успешно, если каждая задача успешно завершает свою асинхронную фазу. Для заданий с большим количеством задач и большими состояниями продолжительность асинхронной фазы определяет, насколько быстрой и стабильной может быть контрольная точка. Однако, на асинхронном этапе есть две проблемы:
- Размер загружаемых файлов сильно зависит от реализации серверной части состояния Flink, а это означает, что эти файлы не всегда могут быть маленькими.
- Фаза асинхронности не начинается до тех пор, пока фаза синхронизации не завершится.
Например, если в качестве хранилища состояний используется key-value СУБД RocksDB, ее уплотнение приводит к большим колебаниям размера загружаемых файлов. Это связано с тем, что сжатие может создать множество новых файлов, которые необходимо загрузить в следующей инкрементной контрольной точке. В результате некоторые задачи могут занимать больше времени на загрузку вновь созданных файлов во время асинхронной фазы, что приведет к увеличению времени выполнения контрольной точки. При большом количестве задач высока вероятность того, что некоторые задачи будут проводить больше времени в асинхронной фазе.
Набор файлов для загрузки не готов до конца фазы синхронизации. Поэтому асинхронная фаза не может начаться раньше, что приводит к потере большой доли времени между двумя последовательными контрольными точками. Другими словами, загрузка файлов на асинхронном этапе происходит за короткий промежуток времени. Если загруженные файлы имеют большой размер, загрузка файлов потребует много ресурсов ЦП и сетевых ресурсов за короткий промежуток времени.
Более короткий интервал создания контрольных точек дает следующие преимущества:
- Снижение задержки для приемников транзакций, которые фиксируются в контрольных точках;
- более предсказуемые интервалы между контрольными точками;
- уменьшение работ по восстановлению состояния stateful-приложения в случае сбоя. Чем чаще контрольная точка, тем меньше событий необходимо повторно обрабатывать после восстановления.
Однако, каждая контрольная точка задерживается как минимум на одну задачу с высоким параллелизмом. С инкрементной реализацией контрольной точки при использовании RocksDB в качестве хранилища состояний каждая подзадача должна периодически сжиматься. Это уплотнение приводит к появлению новых относительно больших файлов, что, в свою очередь, увеличивает время загрузки. Вероятность того, что хотя бы один узел выполнит такое уплотнение и тем самым замедлит работу всей контрольной точки, растет пропорционально количеству узлов. В крупных развертываниях почти каждая контрольная точка задерживается каким-либо узлом.
Серверные части состояния не начинают работу по созданию моментальных снимков, пока задача не получит хотя бы один барьер контрольной точки, что увеличивает ее продолжительность. Чтобы устранить этот недостаток и загружать моментальный снимок непрерывно в течение всего интервала создания контрольных точек, в Apache Flink 1.15 реализован журнал изменений состояния, который мы рассмотрим далее.
Журнал изменений состояния
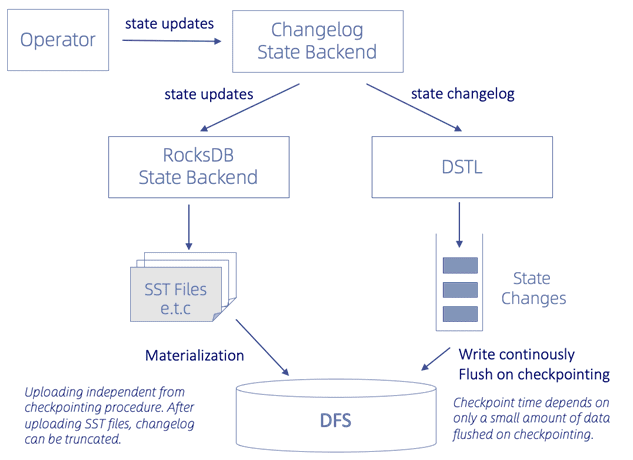
Журнал изменений состояния в Apache Flink работает на уровне операторов потоковой обработки:
- операторы с отслеживанием состояния записывают изменения состояния в журнал изменений состояния, а также применяют их к таблицам состояний в RocksDB или в хеш-таблице в памяти;
- оператор может подтвердить контрольную точку, как только изменения в журнале достигнут надежного хранилища контрольной точки;
- таблицы состояний также периодически сохраняются, независимо от контрольных точек, что можно назвать материализацией состояния;
- как только состояние материализуется в хранилище контрольных точек, журнал изменений состояния может быть усечен до точки, где состояние материализуется.

Этот подход похож на механизм создания моментальных снимков в базах данных:
- изменения (вставки/обновления/удаления) записываются в журнал транзакций, и транзакция считается устойчивой после синхронизации журнала с диском (или другим надежным хранилищем);
- изменения материализуются в таблицах, чтобы СУБД могла эффективно запрашивать таблицу;
- таблицы сохраняются асинхронно;
- как только все части измененных таблиц сохранены, журнал транзакций может быть усечен, что аналогично процедуре материализации контрольных точек в Apache Flink.
Таким образом, журнал изменений является частью контрольной точки и имеет те же гарантии долговечности. Однако, продолжительность хранения журнала изменений будет короткой, пока изменения не материализуются.
Размер контрольной точки — это объем данных, сохраняемых после получения необходимого количества барьеров контрольных точек во время синхронных, а затем асинхронных фаз. Большая часть данных сохраняется упреждающе, после предыдущей контрольной точки и перед текущей. Поэтому этот размер намного меньше при включенном журнале изменений. Полный размер контрольной точки — это общий размер всех файлов, составляющих контрольную точку, включая любые файлы, повторно используемые из предыдущих контрольных точек. По сравнению с обычной контрольной точкой, точка с журналом изменений менее компактна, сохраняет все исторические значения с момента последней материализации и поэтому занимает гораздо больше места.
Рабочая нагрузка связана с большими объемами записи: журнал изменений записывается непрерывно и читается только в случае сбоя. После записи данные не могут быть изменены. Как только изменение сохраняется и подтверждается Job Manager, оно должно быть доступно для воспроизведения, чтобы обеспечить возможность восстановления. В кластере Apache Flink это может быть достигнуто с помощью одной машины, кворума или синхронной репликации.
Каждая задача записывает в свой собственный журнал изменений, что предотвращает проблемы параллелизма между несколькими задачами. Однако при перезапуске задачи ей необходимо записывать в тот же журнал, что может вызвать проблемы с параллелизмом. Это решается с помощью уникальных идентификаторов сегментов журнала при записи и отслеживания обработки подтверждений контрольной точки. После закрытия журнала он обрабатывается как состояние Flink, доступное только для чтения.
Для долгосрочного и устойчивого хранения состояний журнал изменений использует DSTL-лог (Durable Short-term Log). DSTL можно реализовать разными способами, например, в виде распределенного журнала, распределенной файловой системы (DFS, Distributed File System) или базы данных. В Apache Flink 1.15 используется DFS по следующим причинам:
- Отсутствие дополнительной внешней зависимости; DFS доступна в большинстве сред и уже используется для хранения контрольных точек.
- Никаких дополнительных компонентов с отслеживанием состояния для управления; использование любого другого носителя сохранения повлечет за собой дополнительные операционные накладные расходы
- DFS изначально обеспечивает гарантии надежности и согласованности, о которых необходимо позаботиться при внедрении нового настраиваемого распределенного хранилища журналов (в частности, при реализации репликации).
С другой стороны, подход DFS имеет следующие недостатки:
- имеет более высокую задержку, чем запись распределенного журнала на локальные диски;
- ограниченная масштабируемость.
Тем не менее, типовая DFS может удовлетворить 80% случаев использования. DSTL постоянно записывает изменения состояния в DFS и периодически сбрасывает их на контрольную точку. Таким образом, время контрольной точки зависит только от времени, необходимого для сброса небольшого количества данных. С другой стороны, бэкэнд состояний, например, key-value СУБД RocksDB по-прежнему используется для запроса состояния stateful-приложения. Кроме того, его SSTables периодически загружаются в DFS, что называется материализацией. Эта загрузка не зависит от процедуры создания контрольных точек и выполняется гораздо реже, с интервалом по умолчанию 10 минут.
Журнал изменений состояния должен быть усечен после того, как соответствующие изменения материализуются. Это усложняется при повторном масштабировании и совместном использовании базовых файлов несколькими операторами. Однако, Flink уже предоставляет механизм под названием SharedStateRegistry, аналогичный подсчету ссылок файловой системы. Фрагменты журнала можно рассматривать как объекты общего состояния, и поэтому они могут отслеживаться этим SharedStateRegistry.
При использовании DFS для каждой контрольной точки создается много файлов маленького размера, которых становится больше с увеличением частоты контрольных точек. Это чревато задержкой из-за увеличения операций дискового ввода-вывода. Поэтому изменения состояния, связанные с одним и тем же заданием в Task Manager, группируются в один файл. Кроме того, для снижения задержки запросы на запись повторяются, если они не могут быть выполнены в течение времени ожидания, которое по умолчанию составляет 1 секунду, но может быть настроено вручную.
Повышение стабильности и скорости контрольных точек после включения журнала изменений сильно зависит от следующих факторов:
- разница между размером различий в журнале изменений и размером полного или инкрементного состояния;
- возможность непрерывной загрузки обновлений во время контрольной точки, например, оператор может сохранять состояние в памяти и обновлять объекты состояния Flink только в контрольной точке;
- возможность группировать обновления из нескольких задач, которые должны быть развернуты на одном Task Manager. Группировка обновлений приводит к созданию меньшего количества файлов, снижая нагрузку на DFS, что повышает стабильность.
- Способность базового бэкенда накапливать обновления для одного и того же ключа перед очисткой. Журнал изменений состояния потенциально может содержать больше обновлений по сравнению с только окончательным значением, что приводит к увеличению размера добавочного журнала изменений.
- Скорость базового долговременного хранилища.
Если базовый бэкенд состояния, например, RocksDB, может накапливать несколько обновлений состояния для одного и того же ключа без сброса, моментальный снимок будет меньше по размеру, чем журнал изменений. В случае скользящего окна за обновлениями его содержимого в конечном итоге следует очистка. Если эти обновления и очистка происходят во время одной и той же контрольной точки, то окно не будет включено в моментальный снимок. Это также означает, что чем быстрее очищается окно, тем меньше размер моментального снимка.
Общие добавочные контрольные точки на основе журнала изменений впервые вышли в Apache Flink 1.15. Попробовать эту функцию можно, добавив в конфигурационный файл flink-conf.yaml следующее:
state.backend.changelog.enabled: true state.backend.changelog.storage: filesystem dstl.dfs.base-path: <location similar to state.checkpoints.dir>
Читайте в нашей следующей статье про отделение процедуры материализации бэкэнда состояния от процедуры создания контрольной точки Flink и GIC-подход (Generic Log-based Incremental Checkpoint), доступный с версии 1.16.
Узнайте больше про применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

