Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Как устроен механизм отказоустойчивого выполнения в Trino, чем политика повтора QUERY отличается от TASK, зачем настраивать диспетчер обмена на внешнее S3-совместимое хранилище и задавать коэффициент задержки перед повторными попытками выполнить SQL-запрос. 2 политики отказоустойчивого выполнения в Trino Будучи движком online-обработки больших объемов данных с помощью распределенных SQL-запросов, Trino должен иметь...
Как получить спецификацию AsyncAPI из кода с помощью декораторов функций публикации и потребления сообщений средствами Python-библиотеки FastStream: простой пример потокового конвейера на Apache Kafka. Еще раз про FastStream и спецификацию AsyncAPI Вчера я рассказывала про Python-библиотеку FastStream для разработки потоковых конвейеров на Apache Kafka, RabbitMQ, NATS и Redis. Помимо мощного,...

Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений. О библиотеке FastStream Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а...
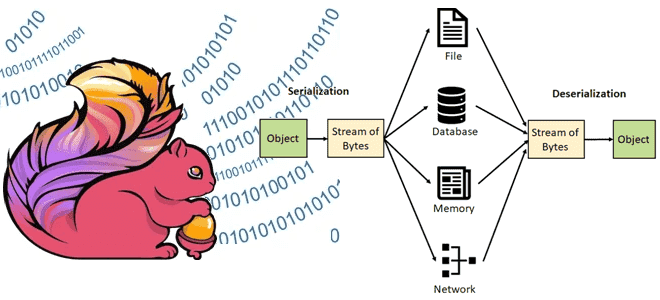
Какие типы данных поддерживает Apache Flink, как сериализация влияет на скорость обработки, зачем выбирать специализированные типы данных вместо общих структур и возможно ли изменение схемы данных без перезапуска приложения. Типы данных в Apache Flink В Apache Flink сериализация играет ключевую роль в процессе обработки данных, обеспечивая преобразование объектов в байтовый...
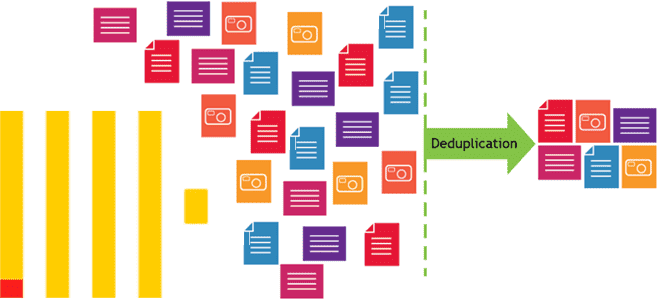
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...
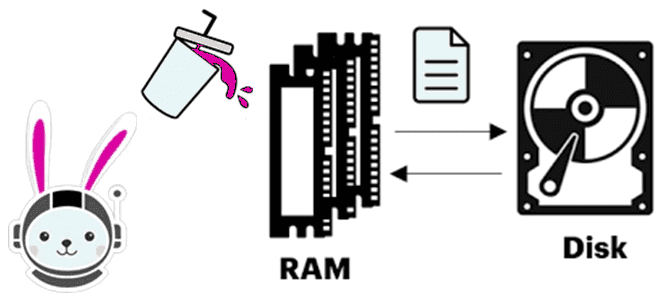
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...

Почему в кластере Trino может возникнуть OOM-ошибка и как справиться с нехваткой памяти, оптимизировав SQL-запросы и настроив конфигурации: примеры и рекомендации. Причины OOM-ошибок в кластере Trino и как их устранить Для Trino, как и для многих JVM-приложений, характерны проблемы с управлением памятью, включая возникновение OOM-ошибок (Out Of Memory). Это связано...
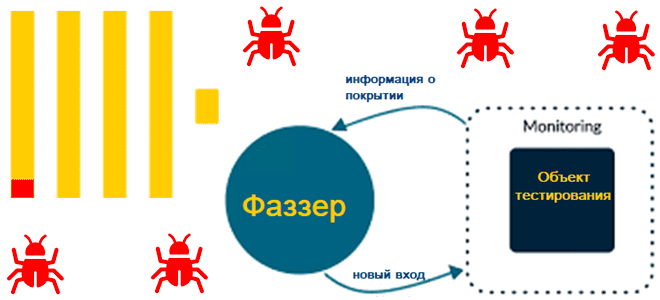
Что такое фаззинг-тестирование, зачем нужен новый фаззер для ClickHouse, и как BuzzHouse выявляет сложные проблемы и потенциальные уязвимости самой популярной колоночной СУБД, Что такое фаззинг-тестирование баз данных Поскольку база данных тоже программный продукт, перед выпуском в релиз она тестируется. Используемых при этом методов тестирования довольно много, и одним из них...

Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...