Как написать конвейер обработки данных Apache Beam, задав цепочку преобразований в YAML-конфигурации: практический пример фильтрации и агрегации платежей из CSV-файла. Пример разработки и запуска YAML-конвейера Apache Beam в Google Colab Недавно я рассказывала про Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
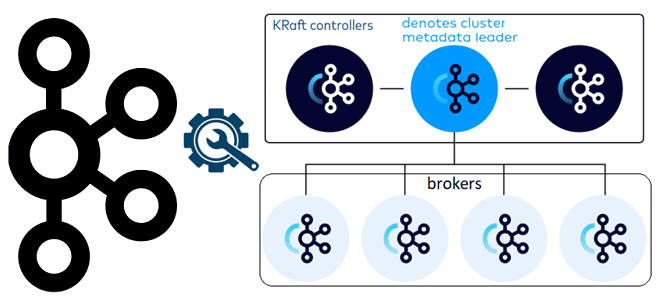
Чем контроллеры Kafka в режиме KRaft отличаются от режима Zookeeper, как их настроить и чем статический кворум отличается от динамического: краткий ликбез для администратора кластера. Брокеры и контроллеры: новые роли серверов Kafka в режиме KRaft Поскольку уже совсем скоро, в мажорном релизе Kafka 4.0, ожидается полный отказ от Zookeeper в...

Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии. О важности потоковой обработки данных и EDA-архитектуры для LLM-систем Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку...
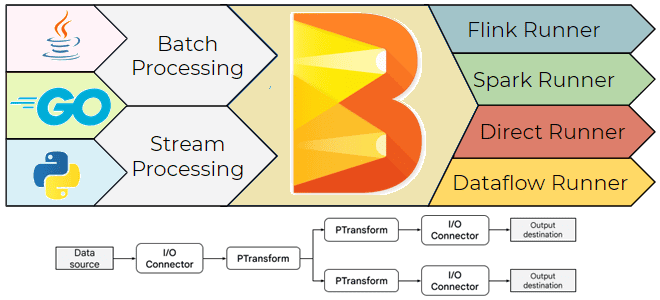
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...
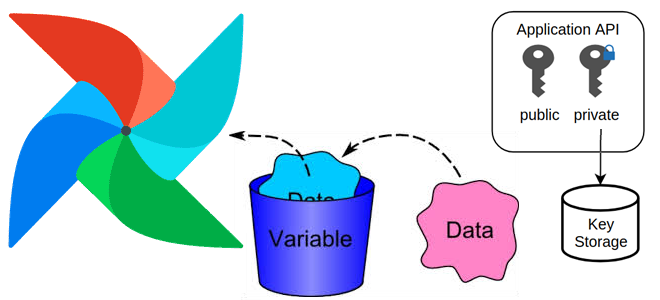
Зачем нужны переменные в Apache AirFlow, какие они бывают, как создать переменную и использовать ее: примеры и рекомендации для эффективной дата-инженерии. Зачем нужны переменные в Apache AirFlow, и какие они бывают Чтобы хранить информацию, которая редко меняется, например, ключи API, пути к конфигурационным файлам, в Apache Airflow используются переменные. Переменные...
Почему репортеры мониторинга системных метрик Flink, отправляющие данные в Prometheus, не решают проблемы предварительной обработки измерений с IoT-устройств, и как новый коннектор расширяет сферу применения фреймворка потоковой обработки. Встроенные средства мониторинга системных метрик Flink В декабре 2024 года вышел новый коннектор Apache Flink к Prometheus – популярной базе данных временных...
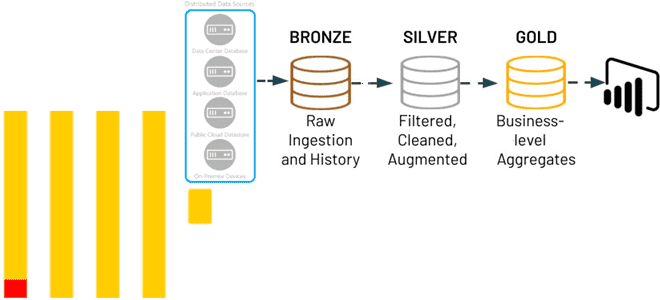
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...
Где и как задавать настройки безопасного доступа клиента к кластеру Trino, каким образом обеспечить безопасность внутри кластера и защитить доступ к внешним источникам данных: примеры конфигураций. Как настроить безопасную работу кластера Trino По умолчанию в Trino не включены функции обеспечения безопасности. Однако, это можно настроить для различных частей архитектуры фреймворка:...
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch. ETL-конвейер Flink CDC в YAML-файле Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink...