 648
648 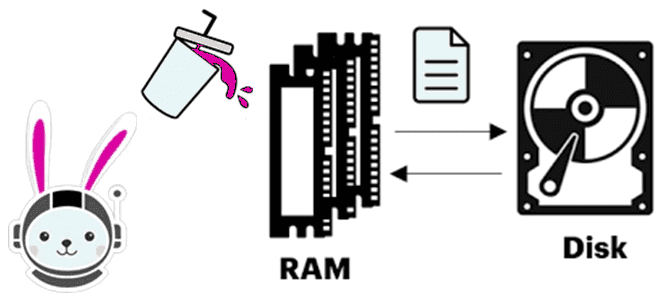
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок.
Spill-to-disk: сброс промежуточных результатов на диск в Trino
Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм этого фреймворка, каким образом его настроить и почему в последнее время он считается устаревшей и нерекомендуемой функцией. Как и во многих вычислительных движках, выполняющих операции с данными в оперативной памяти, в Trino есть механизм сброса данных диск, когда RAM переполнена. В Trino он называется spill-to-disk и использует при операциях с интенсивным использованием памяти, выгружая промежуточные результаты на диск, чтобы выполнить запросы, потребляющие больше ресурсов, чем настроенные лимиты запроса или всего узла. Этот механизм похож на подкачку страниц на уровне операционной системы, но реализован на уровне приложения Trino.
По умолчанию Trino прекращает запрос, если объем памяти, запрошенный для его выполнения, превышает значения, заданные в свойства сеанса query_max_memory или query_max_memory_per_node. Это обеспечивает справедливость при выделении памяти запросам и предотвращает тупики, вызванные выделением памяти. Это эффективно, когда в кластере много мелких запросов, но приводит к уничтожению больших запросов, которые не укладываются в заданные ограничения. Чтобы избежать этого, в Trino введена концепция отзываемой памяти. Запрос может потребовать память, которая не учитывается в ограничениях, но она может быть отозвана менеджером памяти в любое время. Когда память отзывается, исполнитель запросов сбрасывает промежуточные данные из памяти на диск и продолжает обрабатывать их позже. На практике, когда кластер простаивает и вся память доступна, интенсивный запрос памяти может использовать всю память в кластере. С другой стороны, когда в кластере не так много свободной памяти, тот же запрос может быть вынужден использовать диск в качестве хранилища для промежуточных данных. Запрос, который вынужден сбрасывать данные на диск, может выполняться в несколько раз медленнее, чем тот, который полностью выполняется в RAM. Включение функции spill-to-disk не гарантирует выполнение всех запросов, интенсивно использующих память. Иногда бывает, что обработчик запросов не может разделить промежуточные данные на достаточно маленькие фрагменты, чтобы поместить каждый из них в память. И это тоже приводит к OOM-ошибкам при загрузке данных с диска.
Механизм сброса на диск в Trino работает не для всех запросов. В настоящее время spill-to-disk поддерживается для следующих операций:
- соединение, когда одна из таблиц, которые соединяются, сохраняется в памяти. Эта таблица называется таблицей сборки. Строки из другой таблицы передаются потоком и передаются в следующую операцию, если они соответствуют строкам в таблице сборки. Наиболее емкая по памяти часть соединения — эта таблица сборки. Когда параллелизм задач больше единицы, таблица сборки разделяется. Количество разделов равно значению параметра конфигурации concurrency. Когда таблица сборки разделена, механизм сброса данных на диск может уменьшить пиковое использование памяти, необходимое для операции соединения. Когда запрос приближается к пределу памяти, подмножество разделов таблицы сборки сбрасывается на диск вместе со строками из другой таблицы, которые попадают в те же разделы. Количество сбрасываемых на диск разделов влияет на объем необходимого дискового пространства. После этого удаленные разделы считываются по одному для завершения JOIN-операции. С помощью этого механизма пиковая память, используемая оператором JOIN, может быть уменьшена до размера наибольшего раздела таблицы сборки. При отсутствии перекоса данных это в разы превышает размер всей таблицы сборки.
- агрегация над группой значений с возвратом одного результата. Если количество групп, по которым выполняется агрегация, велико, может потребоваться значительный объем памяти. Если ее недостаточно, промежуточные накопленные результаты агрегации записываются на диск, загружаются обратно и соединяются с меньшим потреблением RAM.
- сортировка, которая может требовать значительный объем памяти при большом объеме данных. Когда включена функция spill-to-disk при нехватке памяти промежуточные отсортированные результаты записываются на диск, загружаются обратно и соединяются с меньшим потреблением RAM.
- Оконные функции, которые выполняют оператор над окном строк и возвращают одно значение для каждой строки. Если это окно строк велико, может потребоваться значительный объем памяти. Когда включен сброс данных на диск для оконных функций, при нехватке памяти промежуточные результаты записываются на диск, загружаются обратно и соединяются, когда память снова становится доступной. Это срабатывает не во всех случаях, например, когда одно окно очень большое, сброс на диск не запускается, и возникает OOM-ошибка.
Сброс промежуточных результатов на диск и их извлечение обратно обходится дорого с точки зрения операций ввода-вывода. Поэтому запросы, использующие spill-to-disk, ограничены доступным объемом дискового пространства. Для повышения производительности таких запросов рекомендуется настроить несколько путей на отдельных локальных устройствах, задав свойство spiller-spill-path. Trino сбрасывает промежуточные результаты агрегаций, соединений, сортировки и оконных функций в один или несколько каталогов на разных дисках, что указано в параметре конфигурации spiller-spill-path. Не рекомендуется выполнять сброс на системные диски или те, которых записаны логи JVM, поскольку это перегрузит постоянное хранилище и может привести к длительной остановке виртуальной машины Java, т.е. сбою. Таким образом, неправильная настройка механизма spill-to-disk тоже может привести к OOM-ошибке, когда недостаточно места на диске, и Trino пытается хранить все промежуточные результаты в памяти. Избежать этого можно, ограничив потребление памяти отдельными запросами или пользователями с помощью плагинов для управления ресурсами (Resource Group Manager). Поскольку Trino рассматривает пути сброса как набор независимых дисков (JBOD), нет необходимости использовать RAID-массив.
Чтобы повысить эффективность сброса данных на диск, можно настроить сжатие с помощью свойства spill-compression-codec. Это сокращает дисковый ввод-вывод за счет дополнительной нагрузки на ЦП на сжатие и распаковке страниц. Также дополнительную нагрузку на ЦП создает шифрование сброшенных на диск данных, включенное с помощью свойства spill-encryption-enabled. При этом содержимое шифруется с помощью секретного ключа, случайно сгенерированного для каждого сбрасываемого файла. Хотя это повышает нагрузку на ЦП и снижает пропускную способность сброса данных на диск, так можно защитить слитые страницы. При включении этого шифрования рекомендуется снизить значение порога memory-revoking-threshold, чтобы учесть увеличение задержки сброса данных на диск.
Таким образом, сброс на диск не гарантирует абсолютного избавления от OOM-ошибки. Поэтому в настоящее время в Trino механизм spill-to-disk считается устаревшим. Когда Trino использует его, это может привести к увеличению времени выполнения запросов, особенно при работе с большими объемами данных. Кроме того, сброс временных данных на диск увеличивает риск возникновения проблем из-за ограничений дискового пространства или сбоев в файловой системе, что может привести к прерыванию выполнения запросов и потере данных. Вместо использования spill-to-disk, предпочтительнее оптимизировать запросы и конфигурацию кластера Trino для лучшего управления памятью. Это можно сделать следующими способами:
- увеличить размер JVM-кучи;
- добавить рабочие узлы в кластер;
- сделать распределение задач более сбалансированным.
Рекомендуется отказаться от механизма spill-to-disk в пользу отказоустойчивого выполнения с политикой повтора задач и настроенным менеджером обменов, что мы рассмотрим в следующий раз.
Научиться работать с Trino вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

