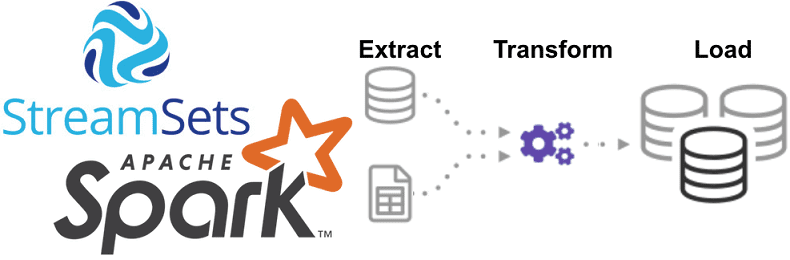
Однажды мы уже рассказывали про StreamSets Data Collector, сравнивая его с Apache NiFi. Сегодня рассмотрим, как устроен этот исполнительный движок для запуска конвейеров обработки больших данных, каким образом он связан с Apache Spark и чем полезен инженеру Big Data при организации ETL-процессов на локальных и облачных озерах данных (Data Lake,...
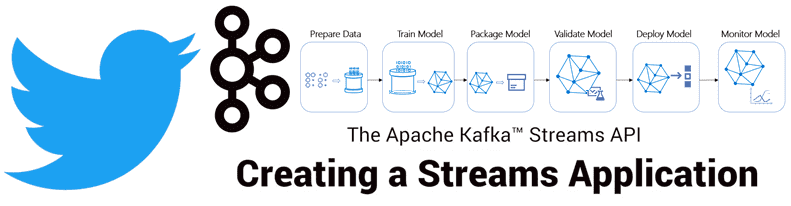
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning). Как...
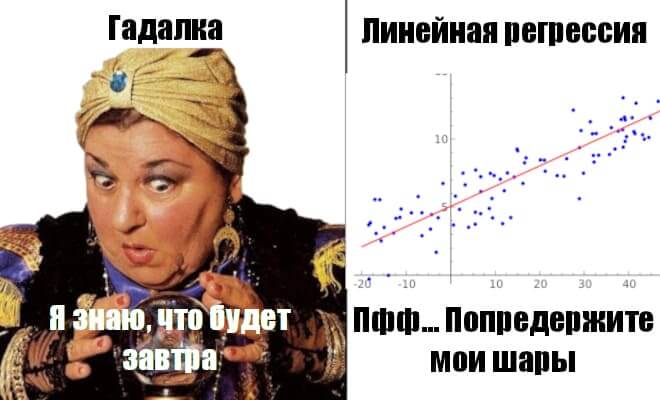
В прошлый раз мы говорили о решении задачи классификации в рамках Machine Learning с помощью PySpark MLlib. Сегодня рассмотрим задачу регрессии. Читайте далее: что такое линейная регрессия, L1 и L2 регуляризация, алгоритм подбора значений гиперпараметров Grid Search, а также применение кросс-валидации в PySpark. Датасет с домами на продажу Обучать модель...

PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...
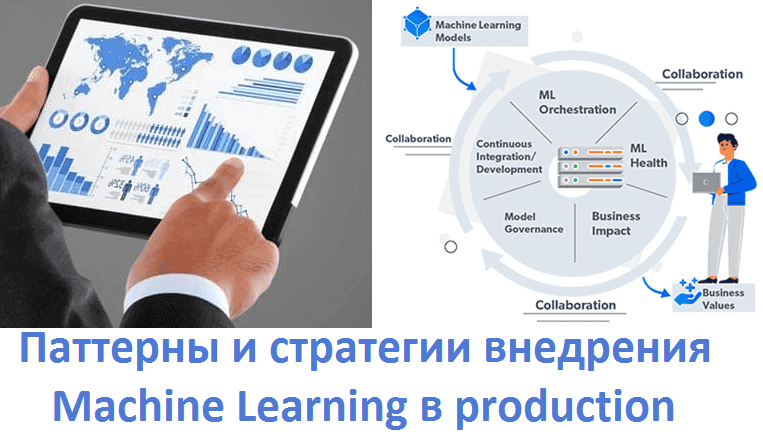
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
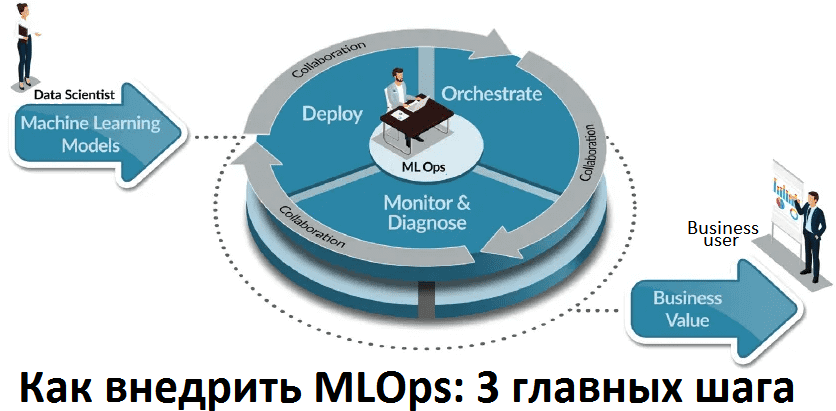
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
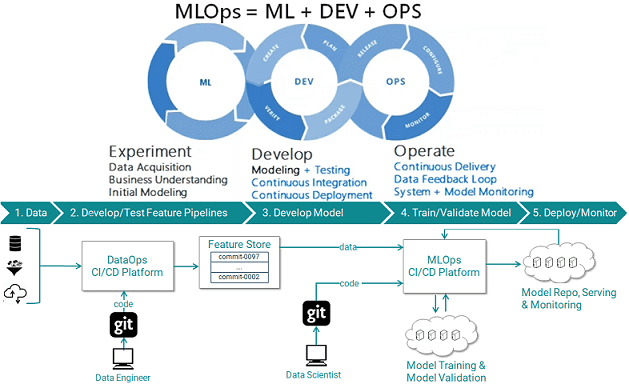
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...