 675
675 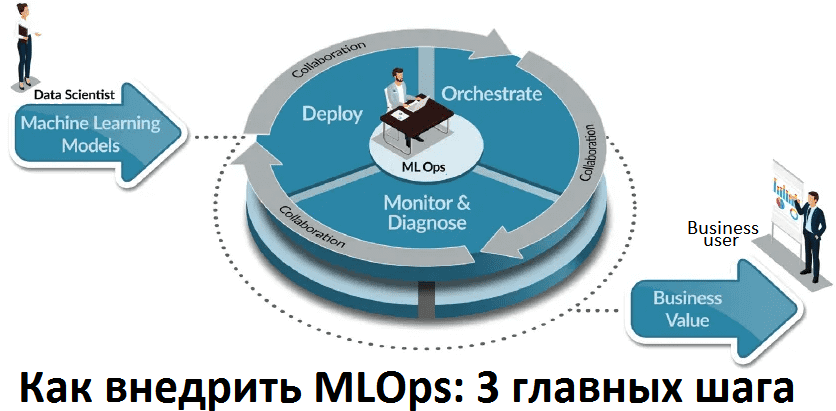
Содержание
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production).
2 направления для внедрения MLOps
Напомним, MLOps – это культура и набор практик для автоматизации комплексного управления жизненным циклом систем машинного обучения, от разработки (Development) до эксплуатации (Operations) всех компонентов: ML-модели, программный код и инфраструктура развертывания. MLOps расширяет методологию CRISP-DM с помощью Agile-подхода и технических инструментов автоматизированного выполнения операций с данными, ML-моделями, кодом и окружением. Таким образом, практическое внедрение MLOps следует вести сразу по 2-м направлениям:
- организационное, что предполагает адаптацию принципов Agile к корпоративной культуре и частичную перестройку бизнес-процессов и структур с целью ускорения циклов выпуска продуктов за счет оперативного и безбарьерного взаимодействия всех участников этой деятельности. Помимо обучающих тренингов, что такое Agile, также здесь необходимо объединение DevOps-инженеров, Data Scinetist’ов и инженеров Big Data в комплексную команду с закреплением личной и групповой ответственности в одном или нескольких ML-проектах и целостными KPI [1].
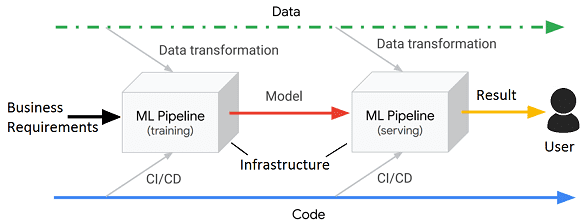
- техническое, что означает использование DevOps-инструментария (CI/CD) для автоматизации процессов разработки, тестирования (в т.ч. валидации данных), интеграции, развертывания и эксплуатационного сопровождения датасетов, моделей, кода и production-среды. Примечательно, что ведется работа с обоими ML-конвейерами: обучения (Training Pipeline) и обслуживания (Serving Pipeline), аналогичные по сути преобразования данных в которых могут различаться с точки зрения реализации. Например, конвейер обучения обычно работает с пакетными файлами, содержащими все функции, а конвейер обслуживания часто работает в интерактивном (потоковом) режиме и получает только часть функций в запросах, а остальные извлекает из существующего хранилища (СУБД или Data Lake на Apache Hadoop). Для согласования обоих pipeline’ов следует обеспечить повторное использование кода и данных везде, где это возможно [2].
Технический инструментарий Machine Learning Operations: лучшие практики и средства с примерами
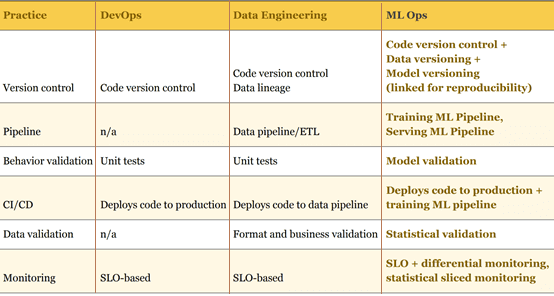
Объединяя лучшие практики DevOps- и инженерии данных, получаем следующий набор перспектив, каждая из которых должна быть автоматизирована с помощью соответствующего инструмента [3]:
- контроль версий кода, данных и ML-моделей в Git-подобном репозитории;
- конвейер операций (Training Pipeline и Serving Pipeline) в рамках готовой или самописной Big Data системы;
- валидация моделей Machine Learning и датасетов аналогично unit-тестированию с учетом бизнес-требований и форматов данных, например, с применением PyTest или комплексных систем типа Cloudera Data Science Workbench, о которой мы писали здесь;
- непрерывный мониторинг на основе SRE-метрик, таких как SLO (Service Level Objective) и статистические показатели, уникальные для конкретного случая, например, через Prometheus или Grafana.
Для комплексной автоматизации всех вышеперечисленных направлений можно выбрать готовую платформу или фреймворк, например, Allegro Trains, MLFlow, Sacred, DVC, AI Platform от Google Cloud, AzureML и SageMaker от Amazon Web Services или Kubeflow от Google для автоматизированного управления набором open-source инструментов MLOps на Kubernetes. Выбор решения зависит не только от уровня корпоративной MLOps-зрелости, но и от степени использования облачных сервисов в компании. Большинство перечисленных решений предполагают именно SaaS/PaaS-подход, когда нужно подключиться к уже готовому Cloud-продукту [3]. Впрочем, даже в этом случае потребуется конфигурирование имеющейся Big Data и ML-инфраструктуры, чтобы интегрировать ее с MLOps-платформами или перейти только на них. При этом также стоит учитывать паттерны предоставления ML-моделей в production, о которых мы поговорим завтра.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
54 000
Комплексное внедрение: 3 ключевых этапа
Сегодня многие ИТ-интеграторы и вендоры Big Data систем предлагают комплексные MLOps-решения на базе открытых технологий с услугами предпроектного обследования, внедрения и сопровождения [4]. Выбор, как обычно остается за заказчиком. Как сделать это наиболее оптимальным образом с учетом контекста и перспективы развития, мы рассматриваем здесь. Однако, независимо от того, каким образом компания будет внедрять подход Machine Learning Operations, это будет включать следующие этапы:
- Определение уровня MLOps-зрелости на предприятии;
- Организационные изменения корпоративной культуры, бизнес-процессов и структур (функциональных групп и проектных команд);
- Проектирование и реализация автоматизированных конвейеров ML-обучения и обслуживания с использованием соответствующих технических инструментов.
Как это сделать на практике, внедряя технологии больших данных и машинное обучение в проекты цифровизации частного бизнеса или цифровой трансформации государственных и муниципальных предприятий, вы узнаете на наших специализированных курсах в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Разработка и внедрение ML-решений
- Аналитика больших данных для руководителей
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники

