 1016
1016 
Содержание
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning).
Как работают рекомендательные ML-системы в соцсетях: разбираем на примере Twitter
Не секрет, что современные контент-платформы и соцсети активно используют машинное обучение для формирования персональных рекомендаций по контенту для каждого пользователя. В частности, в Twitter по умолчанию для вас отображаются те посты, которые с максимальной вероятностью будут интересны именно вам, в зависимости от прошлых прочтений, интересов, лайков, твитов и прочих событий пользовательского поведения. Для этого выбора применяются динамические алгоритмы Machine Learning, которые прогнозируют какие твиты будут наиболее интересны отдельному пользователю. ML-модель учится делать эти прогнозы, анализируя большие объемы данных, чтобы сформировать понимание интересов пользователей на основе их предыдущего поведения. А поскольку интерес пользователей постоянно меняется, модель необходимо регулярно обновлять и желательно делать это очень оперативно.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
15 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Весь процесс работы с данными при этом можно представить в виде следующей типовой последовательности действий [1]:
- Сбор данных (Data Collection), таких как характеристики или предикторы (features) и метки (labels) из журналов сервера и взаимодействий пользователей, например, из избранного и ретвитов;
- Объединение данных (Joining the Data) – поскольку предикторы и метки обычно хранятся отдельно, для обучения модели их следует свести вместе. В частности, характеристика каждого твита маркируется положительной меткой, если твит задействован, либо отрицательной в противном случае.
- Формирование обучающей выборки (Downsampling) предикторы и их метки составляют примеры, среди которых часто бывает перекос в положительную или отрицательную стороны. Это снижает точность ML-модели. Чтобы избежать этой асимметрии и повысить точность прогнозирования, из выборки удаляются некоторые примеры, которых слишком много (положительные или отрицательные), для формирования объективного датасета.
- Обучение модели (Training the Model) – после того, как данные собраны и подготовлены, они передаются для тренировки модели машинного обучения, которая считывает исторические данные и генерирует новую математическую модель для прогнозирования новых пользовательских интересов. В Twitter необработанный набор обучающих данных хранится менее 7 дней, независимо от того, была ли на его основе обучена ML-модель.
- Обновление модели (Refreshing the Model) – после обучения новой модели Machine Learning она сравнивается с историческими данными, которые не являются частью обучающей выборки. Если точность модели достаточно хорошая, она заменяет прежнюю. Иначе существующая модель остается неизменной.
- Прогнозирование (Prediction), когда обновленная модель используется для ранжирования наиболее релевантных твитов и предложения их пользователям.
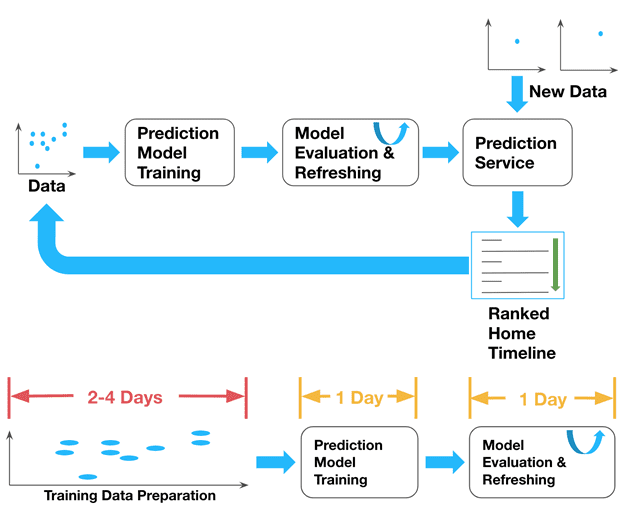
Почему так медленно: пакетная архитектура обучения ML-модели
Сначала описанный конвейер (data pipeline) сбора данных и подготовки журналов был основан на пакетной автономной обработке. Серверные логи (features) и взаимодействия пользователей (метки) сначала записывались в автономное хранилище как сырой набор данных.
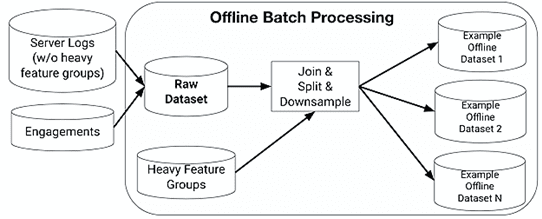
Основными проблемами этой ML-системы прогнозирования были задержка (latency) и качество данных (data quality). C момента регистрации данных до обновления новой обученной модели проходило 4-6 дней из-за следующих причин:
- низкая доступность данных – обучающий датасет формируется по дням, поэтому нужно ждать до конца суток, чтобы собрать все данные (1-2 дня);
- предварительная обработка данных при объединении предикторов и меток, которые хранятся отдельно, на что уходит пара дней;
- обучение модели занимает почти целый день;
- валидация данных, когда требуется проверить качество модели на самых последних данных, на что тоже уходит 1 день.
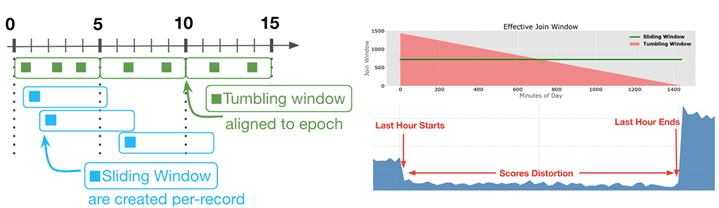
Проблемы качества данных возникали на этапах их сбора и объединения. В частности, имелось расхождения между зарегистрированными данными и теми, которые фактически использовались для прогнозирования. Полные сырые данные были слишком велики, поэтому они регистрировались частично, что приводило к ошибкам. Также ошибки возникали при объединении характеристик твита с их метками. В идеале для каждого твита система сбора данных ожидает взаимодействия с пользователем в течение некоторого времени и решает, является ли твит положительным или отрицательным примером. Время ожидания называется окном соединения (join window), которых может быть 2 вида: кувыркающиеся (Tumbling) и скользящие (Sliding) [1]. Эта терминология часто используется в Apache Kafka Streams [2]:
- кувыркающиеся окна захватывают события, попадающие в определенный промежуток времени. Например, все биржевые транзакции заданной компании каждые 20 секунд, по окончании которых окно «кувыркается» и переходит на новый 20-секундный интервал наблюдения.
- скользящие окна не ждут окончания интервала времени перед созданием нового окна для обработки недавних событий, а запускают новые вычисления после интервала ожидания, меньшего чем длительность окна. Например, требуется подсчитывать число биржевых транзакций каждые 20 секунд, но обновлять счетчик — каждые 5 секунд.
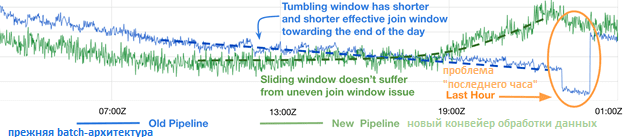
Возвращаясь к кейсу рекомендательной системы Twitter, отметим, что крайний случай происходит в течение последнего часа дня, когда обслуживаемые данные имеют только минуты, чтобы соответствовать потенциальным меткам, и обычно этого не происходит. Наличие предиктора «UTC-час» вместе с меньшим количеством меток в течение последнего часа приводит к резкому снижению рейтинговых оценок и, соответственно, ценности ML-модели [1].
Внедрение Apache Kafka в конвейер регистрации потоковых данных помогло специалистам Twitter сократить время обновления модели Machine Learning примерно в 7 раз, а также повысило гибкость и надежность всей системы в целом. Далее мы рассмотрим, как именно это было сделано.
Apache Kafka и Каппа-архитектура новой рекомендательной системы
Для решения вышеописанных проблем с качеством данных и длительным циклом обучения моделей Machine Learning было решено перейти от пакетной архитектуры к потоковой на основе Kappa-подхода, о котором мы рассказывали здесь. Это означает, что все данные для обучения будут собираться и подготавливаться в реальном времени без каких-либо задержек. Для реализации этой идеи команда Big Data профессионалов Twitter выбрала Apache Kafka и ее библиотеку Kafka Streams в качестве движка потоковой обработки для построения основной части конвейера обработки данных.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
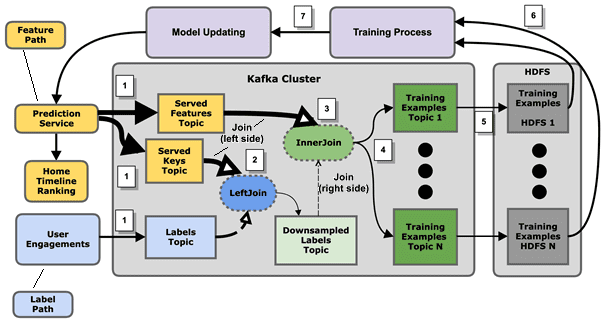
В результате data pipeline рекомендательной ML-системы был организован следующим образом [1]:
- Предикторы твитов публикуются в Apache Kafka службой прогнозирования сразу после того, как твиты отправляются пользователям. Чтобы сделать всю архитектуру более масштабируемой, создаются два потока: топик Served Keys и топик Served Features. Второй содержит все предикторы, а первый — только пару твит-пользователь и другие метаданные, которые точно идентифицируют обучающий пример. Аналогично с метками – действия пользователей (лайки, ретвиты и пр) записываются в соответствующий топик Apache Kafka.
- Топик Served Keys объединяется с метками через LeftJoin. Результирующий поток данных дискретизируется, особенно на отрицательных примерах, чтобы убедиться в сбалансированности итоговой выборки по количеству положительных и отрицательных примеров.
- Далее топик Served Features объединяется с метками через InnerJoins. Несмотря на то, что в каждом твите могут быть тысячи предикторов, InnerJoin на этом этапе масштабируется, поскольку ранее размер выборки был уменьшен.
- Результаты делятся на несколько потоков по типам взаимодействия, что предполагает более точную дискретизацию данных.
- Выходные потоки копируются в долговременное распределенное хранилище, например, Apache Hadoop HDFS для обучения ML-моделей.
- Целые группы ML-моделей обучаются ежедневно на новых данных.
- Обученная ML-модель обновляется в сервисе прогнозирования для обслуживания ранжированных твитов, завершая весь рабочий процесс.
Благодаря такой архитектуре обновленного data pipeline на базе Apache Kafka, команде Big Data специалистов в Twitter удалось резко сократить задержку подготовки данных с 2-4 дней до 4-6 часов, а задержку обновления сквозной ML-модели — с 4-6 дней до 1 дня. Кроме того, возможность работать с полным набором данных предикторов устранила несоответствия в данных и ошибки в обучающем датасете. А с помощью использования sliding-окон в Kafka Streams прекратилось снижение рейтинговых оценок из-за неравномерно распределенного окна обработки данных [1].
Разумеется, на практике реализация такой Big Data системы не обошлась без трудностей, о которых мы расскажем завтра. А как эффективно администрировать и использовать Apache Kafka для потоковой обработки и хранения больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://blog.twitter.com/engineering/en_us/topics/infrastructure/2020/streaming-logging-pipeline-of-home-timeline-prediction-system/
- https://habr.com/ru/company/piter/blog/457756/

