 702
702 
Содержание
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams.
Архитектура приложения Kafka Streams в Twitter
При относительной простоте высокоуровневой архитектуры конвейера Machine Learning в рамках рекомендательной системы Twitter на базе Apache Kafka, о чем мы рассказывали вчера, ее создание не обошлось без трудностей. В частности, специалистам Big Data в компании пришлось модифицировать типовую join-функцию в Kafka Streams. Кроме того, большой объем трафика, также оказывал отрицательное влияние на join-функции по умолчанию, дополнительно нагружая сам кластер Kafka. При этом логика обработки конвейера логов ML-системы Twitter состояла в объединении характеристик или предикторов (features) твитов с метками пользовательского поведения или взаимодействия (labels). Инструментарий Kafka Streams использовался в следующих условиях [1]:
- для резервного копирования состояний применялась RocksDb — высокопроизводительная встраиваемая СУБД типа ключ-значение, оптимизированная для многоядерных ЦП, рабочих нагрузок ввода/вывода и эффективного использования быстрой памяти, например, твердотельных накопителей (SSD). Она основан на журнально-структурированном дереве со слиянием (LSM tree) и часто используется как механизм хранения в рамках более крупной СУБД [2]. В случае Twitter RocksDb выполняет роль локального хранилища для резервного временных данных, когда не хватает ОЗУ не для удерживания всех состояний.
- Обработка данных ведется в рамках т.н. скользящих окон (Sliding windows), чтобы избежать перекоса в количестве событий, характерного для кувыркающихся (Tumbling) окон. Подробнее о механизме временных окон в Apache Kafka Streams мы писали здесь.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
- Объединение данных из локального хранилища состояний RocksDb и скользящего окна топиков Apache Kafka выполняется с помощью SQL-операторов LeftJoin и InnerJoin. LeftJoin проверяет правое хранилище и, если нет совпадающих записей, немедленно генерирует левую. При этом требуется настраиваемое поведение LeftJoin, поскольку метки обычно прибывают позже, чем предикторы, и необходимо подождать достаточное количество времени, прежде чем выдавать несогласованные записи с левой стороны. Для решения этой задачи были использованы API-интерфейсы процессора KafkaStreams.
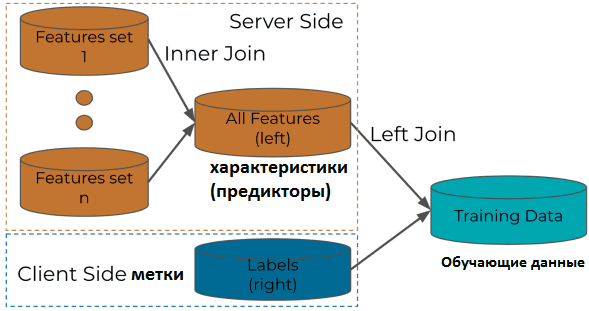
Особенности JOIN-процедур в Kafka Streams
Чтобы настроить LeftJoin, необходимо создать хранилище «ключ-значение» (Key-Value), чтобы временно хранить как объединенные, так и разрозненные записи, отсортированные по порядку обработки. Для этого в LeftJoin были введены два новых хранилища состояний, в дополнение к двум WindowStores с каждой стороны: хранилище состояний KeyValue (kvStore) с левой стороны и хранилище JoinedIndicatorStore, которое используется обеими сторонами [3]:
- WindowStore (KeySortedStore), ключ полезной нагрузки (Payload Key) которого состоит из нескольких частей – составного ключа, за которым следует метка времени (timestamp) записи, а также порядкового номера, который в основном поддерживает дублированные записи. Ключ полезной нагрузки используется для сопоставления записей: две записи с одинаковым ключом полезной нагрузки становятся совпадающей парой, а timestamp определяет, находятся ли две записи в одном временном окне. Если две записи имеют один и тот же ключ и находятся в одном временном окне, то они сопоставляются и объединяются. Поскольку ключи RocksDB отсортированы, ключи WindowStore — это отсортированные ключи полезной нагрузки, получившие название KeySortedStore. Кроме того, одинаковые ключи полезной нагрузки с разными метками времени и порядковыми номерами хранятся рядом на физическом диске. В результате хранилище WindowStore очень эффективно для сопоставления ключей полезной нагрузки. Но оно изменяет порядок исходных записей с их метками времени. Значение (Value) WindowStore — это смещение полезной нагрузки (offset), которое соответствует смещению kvStore.
- kvStore (TimeSortedStore) с типом KeyValueStore имеет timestamp в первой части составного ключа, за которой следует смещение записи и ключ полезной нагрузки. С меткой времени в качестве ведущей части все записи в kvStore имеют своевременный порядок, т.к. все ключи уже отсортированы в RocksDB. Часть смещения в основном используется для хранения дублированных записей. Значение (Value) kvStore — это значение полезной нагрузки, которое используется для leftjoinValue.
- JoinedIndicatorStore, общий для обеих сторон с типом хранилища WindowStore имеет составной ключ JoinedKey, timestamp события слева и номер последовательности. В качестве значения (Value) используется JoinedIndicatorStore – объединенное правостороннее событие.
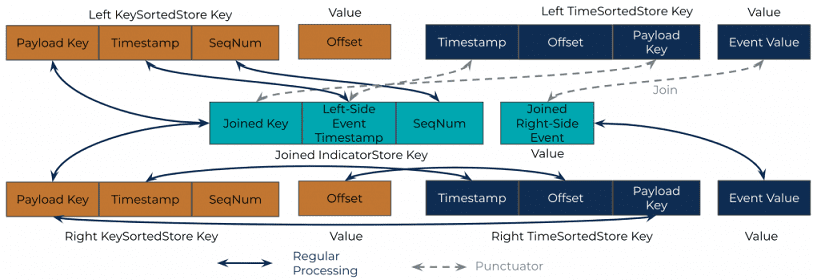
Реализация left join
Реализация left join в рекомендательной ML-системе Twitter на базе Apache Kafka Streams работает следующим образом [3]:
- При поступлении левой или правой записи для join-объединения, она всегда помещается в KeySortedStore и в TimeSortedStore. В частности, ключ полезной нагрузки KeySortedStore соответствует ключу полезной нагрузки TimeSortedStore; поле метки времени KeySortedStore соответствует ключу полезной нагрузки TimeSortedStore; а смещение, которое является значением KeySortedStore, соответствует смещению TimeSortedStore как части ключа.
- При этом KeySortedStore просматривается с целью поиска совпадений – если они есть, то ключ полезной нагрузки, левый timestamp и правое значение полезной нагрузки помещаются в JoinedIndicatorStore. Если соединение происходит с правой стороны, значит, у значение полезной нагрузки уже есть, и его можно напрямую вставить в JoinedIndicatorStore. Но если соединение происходит с левой стороны, следует сначала получить поля из правого KeySortedStore, поскольку именно так сопоставляются записи. Затем выбираются соответствующее значения полезной нагрузки из TimeSortedStore по полям в KeySortedStore и, наконец, вставляются в JoinedIndicatorStore.
- Записи в JoinedIndicatorStore сначала проверяются проверены и потенциально отправлены в левом пунктуаторе (Punctuator) – методе, который используется для определения времени потока. Например, если запланировать функцию Punctuator каждые 10 секунд на основе PunctuationType.STREAM_TIME, и обработать поток из 60 записей с последовательными метками времени от 1 (первая запись) до 60 секунд (последняя запись), то метод punctuate() будет вызываться 6 раз. Это происходит независимо от времени, необходимого для фактической обработки этих записей – метод punctuate() будет вызываться 6 раз независимо от того, занимает ли обработка этих 60 записей секунду, минуту или час [4]. Метка времени JoinedIndicatorStore всегда является левой меткой времени, поскольку она нужна для извлечения JoinedIndicatorStore в пунктуаторе. Кроме того, значение JoinedIndicatorStore является правым значением полезной нагрузки, т.к. с левой стороны периодически будет пунктуатор. С его помощью можно получить значение полезной нагрузки слева, запросив левый kvStore.
- Левосторонний пунктуатор в основном ожидает, пока окно для левой записи не закроется, и отправляет соответствующие совпавшие записи в JoinedIndicatorStore путем сканирования диапазона левого TimeSortedStore и последующего запроса точки к JoinedIndicatorStore. Здесь выполняется сопоставление меток времени и полей: ключ полезной нагрузки TimeSortedStore соответствует объединенному ключу в JoinedIndicatorStore. Так можно получать записи из обоих хранилищ. Наконец, с помощью punctuate() можно также очистить просроченные записи в левом TimeSortedStore. Очистка KeySortedStore и JoinedIndicatorStore выполняется Kafka Streams через

Поскольку WindowStore содержит только минимальный объем данных, запрос на сопоставление данных выполняется очень быстро. Кроме того, т.к. метки времени в kvStore уже отсортированы, сканирование диапазона в также происходит весьма оперативно. Для Twitter c миллионами событий в секунду эффективная реализация очень важна [3]. Подводя итог описанию реализованной системы, Big Data специалисты Twitter отмечают, что настраиваемый DSL для JOIN-операций в Kafka Streams – это успех в ML-конвейере, принесший следующие положительные результаты [1]:
- сокращение цикла обновления моделей Machine Learning примерно в 7 раз, до одного дня;
- актуализация обучающих данных;
- существенная экономия времени дата-инженеров за счет автоматизации процессов сбора и агрегации данных.
В будущем Twitter планирует попробовать кооперативную ребалансировку, которая была введена в Apache Kafka 2.5, чтобы еще более повысить эффективность работы своего ML-конвейера.
Курс Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
26 января, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Завтра мы продолжим разговор про Apache Kafka и рассмотрим интеграцию с платформой удаленного мониторинга приложений New Relic с помощью фреймворка Connect. Больше практических деталей по администрированию и эксплуатации Apache Kafka для потоковой обработки и хранения больших данных в проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://blog.twitter.com/engineering/en_us/topics/infrastructure/2020/streaming-logging-pipeline-of-home-timeline-prediction-system/
- https://ru.bmstu.wiki/RocksDB
- https://www.confluent.io/blog/how-twitter-built-a-machine-learning-pipeline-with-kafka/
- https://kafka.apache.org/10/documentation/streams/developer-guide/processor-api/

