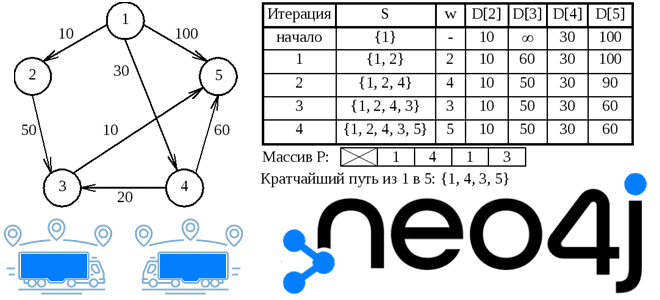
Вопрос перестройки логистических цепочек сегодня стал очень остро перед множеством предприятий, от малого до очень крупного бизнеса. Рассмотрим, как методы Data Science и аналитики больших данных помогают бизнесу справиться с современными вызовами на примере реализации алгоритма Дейкстры в библиотеке Graph Data Science графовой СУБД Neo4j. Постановка задачи: поиск кратчайшего пути...
Иногда в распределенных системах требуется строгий порядок событий, т.е. сообщений или записей с полезными данными и состоянием, который должен поддерживаться между продюсерами и потребителями в конвейере их обработки. Например, чтобы сохранить корректный порядок транзакций для правильного расчета остатков по счетам. Читайте далее, как это реализовать в Apache Kafka. Настройка продюсера...

Как снизить затраты на AWS EMR, сохранив эффективность Spark-конвейеров обработки данных на спотовых инстансах и других типах узлов облачного кластера. Также рассмотрим, что такое прерываемые виртуальные машины в Яндекс.Облаке и каким образом настроить такую облачную инфраструктуру, чтобы сократить затраты на выполнение Spark-приложений, одновременно повысив их отказоустойчивость. Блеск и нищета спотовых...
Недавно мы писали про проектирование микросервисной архитектуры на базе Apache Kafka. В продолжение этой актуальной для ИТ-архитекторов, разработчиков и дата-инженеров темы, сегодня рассмотрим опыт американской медиакомпании Storyblocks по переходу от монолитной архитектуры системы поставки контента к распределенным микросервисам с Apache Kafka в Confluent Cloud. Постановка задачи: монолит vs микросервисы По...

24 февраля 2022 года российская компания Аренадата Софтвер, выпускающая корпоративные решения для хранения и аналитики больших данных, добавила поддержку защищенного протокола Kerberos в своих продуктах Arenadata Hadoop, Streaming и Platform Security. Разбираемся, чем это полезно, как связано с Apache Ambari и как настроить. Улучшенная безопасность продуктов Arenadata c Kerberos Active Directory ...

Сегодня заглянем под капот Tanzu Greenplum Text: архитектура и принципы работы этого средства поиска и анализа текстов, интегрированного с популярной MPP-СУБД. Как движок наподобие Elasticsearch связывает кластер Apache Solr с базой данных Greenplum и зачем здесь нужен Zookeeper. Что такое Tanzu Greenplum Text Мы уже рассказывали про основные функциональные возможности...

В рамках обучения ИТ-архитекторов и разработчиков распределенных приложений рассмотрим, что представляет собой Transactional Outbox и как этот паттерн проектирования микросервисной архитектуры можно реализовать с помощью Neo4j и Apache Kafka, чтобы создать масштабируемый, общий и абстрактный способ запроса информации независимо от типа объекта. Постановка задачи: проблемы микросервисной архитектуры и способы их...

Сегодня поговорим про администрирование кластера Apache Kafka и разработку потоковых приложений передачи и разберем, как обеспечить их работу в бессерверном режиме с платформой Upstash. Финансовая экономия, простота сопровождения и другие преимущества FaaS-сервисов и serverless-подхода с RESTfull API для обработки событий в реальном времени. Снова про serverless: что такое Upstash Kafka...
Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков. Проблемы обработки сложных структур данных с JDBC-коннектором...
Сегодня рассмотрим, как использовать статистический язык R для анализа данных в Greenplum. Что такое GreenplumR, как работает этот интерактивный клиент, чем он полезен специалисту по Data Science и каковы недостатки этого инструмента аналитики больших данных. Что такое GreenplumR Хотя основным языком в области Data Science сегодня считается Python, иногда специалисты...