Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков.
Проблемы обработки сложных структур данных с JDBC-коннектором Apache Kafka
Для передачи данных из Apache Kafka в реляционные РСУБД можно использовать JDBC-коннектор от Confluent, который потребляет записи из топика Kafka и отправляет их в базу данных с помощью JDBC-драйвера. JDBC Connector (Source and Sink) поддерживает множество баз данных, не требуя специального кода для каждой из них: данные загружаются путем периодического выполнения SQL-запроса и создания выходной записи для каждой строки в результирующем наборе. По умолчанию все таблицы в базе данных копируются, каждая в свой отдельный выходной топик. Сама база данных отслеживается на наличие новых или удаленных таблиц и автоматически адаптируется.
При копировании данных из таблицы коннектор может загружать только новые или измененные строки, указывая, какие столбцы следует использовать для обнаружения новых или измененных данных. Можно добиться идемпотентной записи с помощью операций вставки-обновления (upserts). Также поддерживается автоматическое создание таблиц и ограниченное автоматическое развитие.
Коннектор приемника требует знания схем, поэтому следует использовать подходящий преобразователь, например, AVRO, который поставляется с реестром схем (Schema Registry), или преобразователь JSON с включенными схемами. Ключи записи Kafka могут быть примитивными типами или структурой Connect, а значение записи должно быть структурой Connect. Поля, выбираемые из структур Connect, должны относиться к примитивным типам. Если данные в теме имеют несовместимый формат, может потребоваться реализация пользовательского преобразователя.
На практике этот коннектор отлично работает при соблюдении следующих условий:
- схема записей, которые необходимо отправить в СУБД, плоская и не содержит массивов или аналогичных сложных структур, таких как вложенные массивы объектов с несколькими уровнями;
- каждая запись из топика Kafka однозначно сопоставляется с одной строкой в целевой таблице реляционной базы данных.
В реальности эти условия соблюдаются не всегда: некоторые записи имеют сложные схемы данных со вложенными массивами, которые также могут содержать многоуровневые структуры. При их отправке из топика Kafka с помощью JDBC Sink-коннектора можно столкнуться с исключением
org.apache.kafka.connect.errors.ConnectException: Unsupported source data type: ARRAY
Для решения этой проблемы стоит рассмотреть следующие варианты:
- сгладить схему данных с помощью топологии Kafka Streams, а затем использовать эту упрощенную схему в качестве входных данных для JDBC-коннектора приемника;
- применить функцию explode() в ksqlDB;
- написать свой собственный Java-потребитель или коннектор Kafka;
- использовать JDBC Sink с функцией Flatten, который является расширением существующего JDBC-коннектора от Confluent. При его использовании сопоставления и массивы будут разделены и записаны в отдельные целевые таблицы.
Каждый из перечисленных вариантов имеет свои достоинства и недостатки. В частности, если требуется универсальное решение, которое можно повторно использовать для нескольких сценариев с Kafka Connect и минимальными усилиями на разработку кода, предпочтительным кажентся последнее решение – расширение JDBC Sink-коннектора с функцией Flatten. Однако, для сложных схем AVRO потребуется его тщательная настройка и отладка. Поэтому имеет смысл разработать собственный преобразователь отдельных сообщений (SMT, Single Message Transformation) для применения к сообщениям из топика Kafka по мере их прохождения через платформу Connect. SMT преобразуют входящие сообщения после их создания коннектором источника, но до того, как они будут записаны в Kafka. SMT преобразуют исходящие сообщения перед их отправкой на коннектор приемника. Как это реализовать, рассмотрим далее.
Пользовательский SMT для обработки вложенных структур
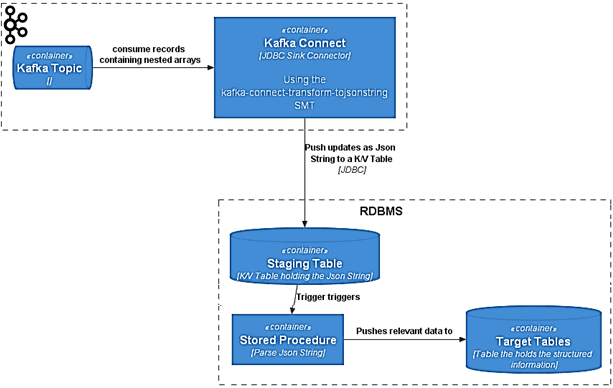
Если большинство СУБД-приемников поддерживают работу со строками JSON или строками XML, можно использовать обычный JDBC-коннектор приемника Kafka, добавив специальный SMT, который преобразует исходную сложную схему в более простую, содержащую только одно поле. Содержимое этого поля — исходная схема со всеми данными в строковом представлении JSON или XML. Эта строка помещается в промежуточную таблицу «Ключ/Значение» в целевой БД. Логика на стороне БД с использованием триггеров и хранимых процедур анализирует строку JSON или XML и при необходимости сопоставляет ее с любой реляционной моделью. Исходный код этого коннектора доступен на Github по лицензии Apache 2, а его архитектура выглядит следующим образом:
- потребитель считывает данные со сложными схемами и вложенными структурами из топика Kafka;
- SMT-преобразователь с JDBC-коннектором приемника на платформе Kafka упрощает схему данных;
- плоское представление исходной схемы данных в виде строки JSON или XML записывается в промежуточную таблицу «Ключ/Значение» в целевой реляционной базы;
- парсинг JSON-строки выполняется с помощью хранимых процедур в целевой СУБД;
- итоговый результат записывается в нужные таблицы базы-приемника.
Представленное решение имеет следующие преимущества:
- отсутствие дополнительных компонентов типа Kafka Streams или KSQL в интеграционном конвейере;
- универсальное решение, которое можно применять для нескольких вариантов использования со сходной структурой и большинства реляционных СУБД;
- изменения схемы данных в сообщениях не отразятся на стороне Kafka Connect, а затронут только хранимые процедуры СУБД;
- SMT можно комбинировать с другими подобными преобразователями для фильтрации или предварительного преобразования данных.
Обратной стороной этих достоинств являются следующие недостатки:
- Рост нагрузки на базу данных и повышенное потребление места на жестком диске из-за промежуточных таблиц, куда записываются огромные блоки данных, которые необходимо обрабатывать на стороне БД. При этом из объемной записи JSON может требоваться только один или несколько атрибутов, а остальная строка не нужна, а лишь занимает место.
- в некоторых реляционных СУБД работа с JSON и XML может быть сложна и требует от разработчика определенных навыков;
- изменения схемы данных необходимо учитывать в хранимых процедурах, поэтому знать об этом необходимо заранее;
- мониторинга Kafka Connect недостаточно, также необходимо следить за выполнением логики обработки данных в самой базе;
- отсутствие безопасности типов – при работе со строками разработчику придется заботиться о совместимости типов данных и применяемых к ним функций самостоятельно.
Некоторые из этих недостатков можно обойти, дополнив описанное SMT-решение функциями поиска конкретной информации из вложенных массивов в записи подключения, например, JsonPath/XPath, чтобы передавать в реляционные СУБД только те данные, которые действительно необходимы, а не огромные строки JSON целиком.
Больше практических деталей по администрированию и использованию Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники
- https://medium.com/bearingpoint-technology-advisory/handle-arrays-and-nested-arrays-in-kafka-jdbc-sink-connector-41929ea46301
- https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
- https://docs.confluent.io/platform/current/connect/transforms/overview.html
- https://github.com/an0r0c/kafka-connect-transform-tojsonstring

